Elasticsearch数据采集和处理--Logstash VS Ingest Node

1、背景
Logstash是Elastic Stack的重要组成部分(即ELK中的L),在该架构中负责数据采集,处理,输出等功能,支持多种数据输入,数据处理,数据输出方式,并且具有可扩展性好,功能强大等优点。典型的采用Logstash进行数据采集和处理的Elastic Stack架构如下图:
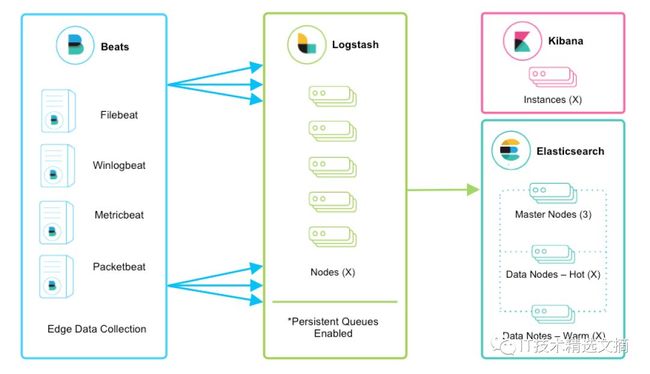
而Ingest Node是在Elasticsearch5.0之后引入的特性,用于在文档实际索引动作执行前对文档进行预处理,在数据处理层面上与Logstash有许多功能重叠之处。引入Ingest Node后的Elastic Stack数据采集和处理架构如下:
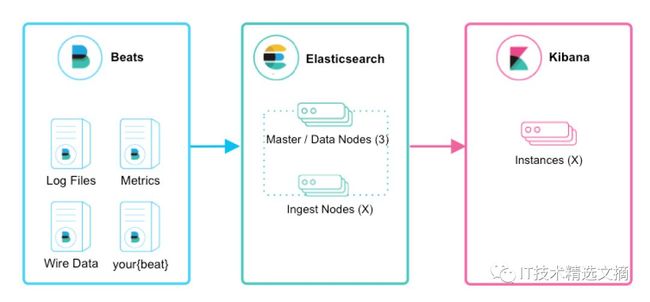
Ignest Node的出现为Elastic Stack 数据的采集和处理提供了一种新的方式,在许多场景下用户可以在不使用Logstash的情况下,完成数据的采集和处理,简化了系统架构。那么Logstash和Ignest Node有何异同?在实际使用中该如何选择呢?
2、Logstash与Ignest Node的比较
2.1 数据输入和输出
Ingest Node:作为Elasticsearch索引文档过程的一部分,仅能使用Elasticsearch支持的方式来输入,如Restful接口等,处理过后的数据也只能索引入Elasicsearch中,而不能输出到其他地方。
Logstash:支持多种数据源,包括各种Beats,Mysql,kafka等,不仅可以作为服务端接收Client通过TCP,UDP,HTTP等方式推送过来的数据,也可以主动从数据库,消息队列等处拉取数据。数据输出功能也非常强大,可以输出到消息队列,对象存储,HDFS等。
2.2 数据缓冲
Ingest Node:Elasticsearch本身并没有提供数据缓冲策略,数据输入端需要自行解决ES拒绝写入请求的情况。而Ingest Node作为ES索引文档的一部分也没有数据缓冲策略。
Logstash:提供队列机制,可以防止数据丢失和承受一定的负载尖刺。另外,还支持多种队列,可以根据业务实际情况选择合适的队列。
2.3 数据处理
Ingest Node:支持超过20多种processors,这些processors覆盖了Logstash的常用场景。限制是只能在单个数据的上下文执行,另外不能调用外部的系统,如文件,数据库等
Logstash:支持大量的processors,用户甚至可以自己的需要编写plugins,也可以调用包括磁盘文件,数据库,ES等外部资源。另外Logstash支持根据条件过滤和丢弃数据。
2.4 配置和使用
Ingest Node:通过ES接口创建Pipeline, 并存入Elasticsearch中,无监控和可视化管理界面
Logstash:主要通过配置文件来定义Pipeline,支持条件控制流和多pipeline,并提供有监控和可视化Pipeline管理功能,对于性能调优和问题定位非常有帮助。Kibana中的Logstash pipeline管理界面如下图:
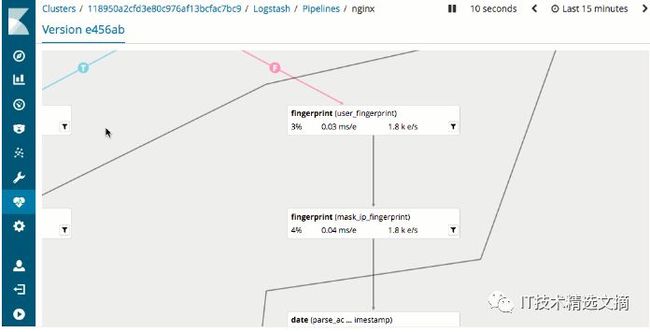
Kibana Pipeline管理
3、分析
(1)输入方面,虽然Logstash支持更多的输入方式,但是Ingest Node也可以通过与Beats,甚至Logstash配合来解决不同数据源的输入问题。
(2)输出方面,由于Ingest Node 作为Elasticsearch索引文档过程的一部分,因此除非对源码进行改造,否则无法将数据导出到其他地方。因此如果有将处理过后的数据导出到其他地方的需求,建议使用Logstash。
(3)数据缓冲方面,Ingest Node 可以通过在文档输入前接入Kafka等消息队列来解决。另外在实际使用中,即使Logstash自身有队列机制,一般也会在Logstash前增加Kafka来更好的缓冲数据传输压力。
(4)数据处理方面,IgnestNode支持Logstash的大多数常用场景,如果在使用前可以明确所有使用场景,确定Ignest Node可以满足需求,可以使用IgnestNode,如果IgnestNode不能满足要求,则需要采用Logstash。
(5)配置和使用方面,在这方面Logstash有明显优势,灵活的配置方式,可视化监控和pipeline管理,在复杂系统中有着重要的帮助作用。
(6)性能和架构方面,Ignest作为Elasticsearch集群的一部分,当数据处理逻辑相对简单时,可以简化数据采集和处理架构。但是当数据处理相对逻辑复杂时,Ingest Node数据处理过程可能影响节点的性能。这时一般采用专用Ingest Node的方式解决,而引入专用Ingest Node会使Elasticsearch集群的结构变得复杂,这与Ingest Node简化数据采集和处理架构的优势背道而驰。而Logstash是处于Elasticsearch前的专用数据采集和处理模块,当性能出现瓶颈时可以通过横向扩展的方式来提高处理能力,在架构上更为清晰。
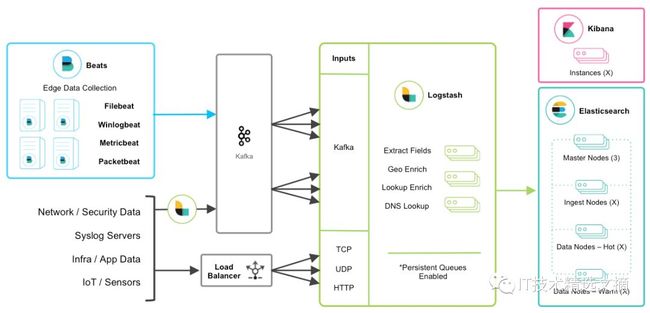
(7)Ingest Node与Logstash的联用,Ingest Node是Elasticsearch集群的一部分,而Logstash处于Elasticsearch的前端,在结构上两者完全可以配合使用。PS:Ignest Node一个用法是为数据添加时间戳,以便更精确地记录文档索引时间,在耗时计算时有一定用处。Ingest Node与Logstash联用的Elastic Stack架构图如下:
4、结论和建议
通过上面的比较和分析不难发现,Ignest Node 在功能上基本为 Logstash 的子集, 在数据处理逻辑简单,没有其他额外输出端的时候,可以简化系统架构,实现快速部署。但是当处理逻辑复杂,多输入源和多输出源的场景下,Logstash的功能强大和灵活更为合适。
在实际使用中可以根据自己的业务特点来选择Ingest Node或Logstash。
(1)如果是将Elastic Stack使用在特定场景下,且数据处理逻辑相对简单,可以考察Ignest Node是否满足需求,优先使用Ignest Node实现系统的快速部署。
(2)当需要搭建的是一个通用的Elastic Stack平台,需要支持多种输入源,输出源,数据处理逻辑也相对复杂时,建议采用Logstash, 利用Logstash的功能强大,灵活,可扩展等特性,保证系统的功能性和稳定性。
(3)如果在系统搭建初期,需求不明确,由于Ignest Node和Logstash可以联用,因此可以先使用Ingest Node来搭建系统,当功能无法满足时,再在Elasticsearch前面增加Logstash。
Ingest Node和Logstash虽然在功能上有很多重叠,但是仍有各自的特点,在实际的业务场景中,可以根据业务需要灵活选择。