无人驾驶之车道线检测(一)
车道检测(Advanced Lane Finding Project)
车道检测作为无人驾驶的基础技术,有必要单独进行研究下。我准备用两篇文章记录车道检测功能,本篇是基于传统算法进行车道检测,下篇将使用深度学习的算法进行分析。
占坑。。。。最近比较忙后续更新
先看几个流程图:
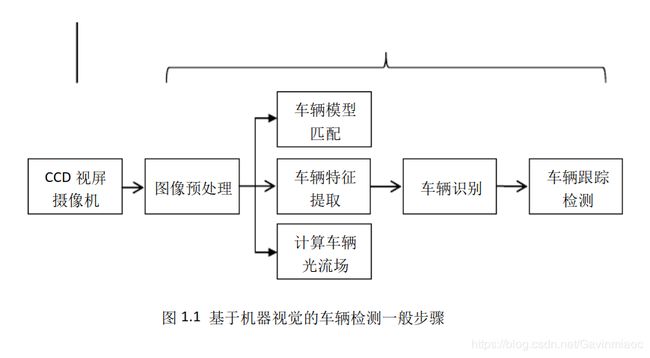

实现步骤:
- 使用提供的一组棋盘格图片计算相机校正矩阵(camera calibration matrix)和失真系数(distortion coefficients).
- 校正图片
- 使用梯度阈值(gradient threshold),颜色阈值(color threshold)等处理图片得到清晰捕捉车道线的二进制图(binary image).
- 使用透视变换(perspective transform)得到二进制图(binary image)的鸟瞰图(birds-eye view).
- 针对不同颜色的车道线,不同光照条件下的车道线,不同清晰度的车道线,根据不同的颜色空间使用不同的梯度阈值,颜色阈值进行不同的处理。并将每一种处理方式进行融合,得到车道线的二进制图。
- 提取二进制图中属于车道线的像素
- 对二进制图片的像素进行直方图统计,统计左右两侧的峰值点作为左右车道线的起始点坐标进行曲线拟合。
- 使用二次多项式分别拟合左右车道线的像素点(对于噪声较大的像素点,可以进行滤波处理,或者使用随机采样一致性算法进行曲线拟合)。
- 计算车道曲率及车辆相对车道中央的偏离位置。
- 效果显示(可行域显示,曲率和位置显示)。
摄像机标定
相信大家都多少听说过鱼眼相机,最常见的鱼眼相机是辅助驾驶员倒车的后向摄像头。也有很多摄影爱好者会使用鱼眼相机拍摄图像,最终会有高大上的大片效果,如下图所示。

图片来源:优达学城(Udacity)无人驾驶工程师课程
使用鱼眼相机拍摄的图像虽然高大上,但存在一个很大的问题——畸变(Distortion)。如上图所示,走道上的栏杆应该是笔直延伸出去的。然而,栏杆在图像上的成像却是弯曲的,这就是图像畸变,畸变会导致图像失真。
使用车载摄像机拍摄出的图像,虽然没有鱼眼相机的畸变这么夸张,但是畸变是客观存在的,只是人眼难以察觉。使用有畸变的图像做车道线的检测,检测结果的精度将会受到影响,因此进行图像处理的第一步工作就是去畸变。
为了解决车载摄像机图像的畸变问题,摄像机标定技术应运而生。
摄像机标定是通过对已知的形状进行拍照,通过计算该形状在真实世界中位置与在图像中位置的偏差量(畸变系数),进而用这个偏差量去修正其他畸变图像的技术。
原则上,可以选用任何的已知形状去校准摄像机,不过业内的标定方法都是基于棋盘格的。因为它具备规则的、高对比度图案,能非常方便地自动化检测各个棋盘格的交点,十分适合标定摄像机的标定工作。如下图所示为标准的10x7(7行10列)的棋盘格。

OpenCV库为摄像机标定提供了函数cv2.findChessboardCorners(),它能自动地检测棋盘格内4个棋盘格的交点(2白2黑的交接点)。我们只需要输入摄像机拍摄的完整棋盘格图像和交点在横纵向上的数量即可。随后我们可以使用函数cv2.drawChessboardCorners()绘制出检测的结果。
棋盘格原图如下所示:

图片出处:https://github.com/udacity/CarND-Advanced-Lane-Lines/blob/master/camera_cal/calibration2.jpg
使用OpenCV自动交点检测的结果如下:

获取交点的检测结果后,使用函数cv2.calibrateCamera()即可得到相机的畸变系数。
我们使用cv2.calibrateCamera()进行标定,这个函数会返回标定结果、相机的内参数矩阵、畸变系数、旋转矩阵和平移向量。
为了使摄像机标定得到的畸变系数更加准确,我们使用车载摄像机从不同的角度拍摄20张棋盘格,将所有的交点检测结果保存,再进行畸变系数的的计算。
我们将读入图片、预处理图片、检测交点、标定相机的一系列操作,封装成一个函数,如下所示:
1.计算摄像机畸变系数
#################################################################
# Step 1 : Calculate camera distortion coefficients
#################################################################
def getCameraCalibrationCoefficients(chessboardname, nx, ny):
# prepare object points, like (0,0,0), (1,0,0), (2,0,0) ....,(6,5,0)
objp = np.zeros((ny * nx, 3), np.float32)
objp[:,:2] = np.mgrid[0:nx, 0:ny].T.reshape(-1,2)
# Arrays to store object points and image points from all the images.
objpoints = [] # 3d points in real world space
imgpoints = [] # 2d points in image plane.
images = glob.glob(chessboardname)
if len(images) > 0:
print("images num for calibration : ", len(images))
else:
print("No image for calibration.")
return
ret_count = 0
for idx, fname in enumerate(images):
img = cv2.imread(fname)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img_size = (img.shape[1], img.shape[0])
# Finde the chessboard corners
ret, corners = cv2.findChessboardCorners(gray, (nx, ny), None)
# If found, add object points, image points
if ret == True:
ret_count += 1
objpoints.append(objp)
imgpoints.append(corners)
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints,
img_size, None, None)
print('Do calibration successfully')
return ret, mtx, dist, rvecs, tvecs调用之前封装好的函数,获取畸变参数。
nx = 9
ny = 6
ret, mtx, dist, rvecs, tvecs = getCameraCalibrationCoefficients('camera_cal/calibration*.jpg', nx, ny)随后,使用OpenCV提供的函数cv2.undistort(),传入刚刚计算得到的畸变参数,即可将畸变的图像进行畸变修正处理。
#################################################################
# Step 2 : Undistort image
#################################################################
def undistortImage(distortImage, mtx, dist):
return cv2.undistort(distortImage, mtx, dist, None, mtx)以畸变的棋盘格图像为例,进行畸变修正处理
# Read distorted chessboard image
test_distort_image = cv2.imread('./camera_cal/calibration4.jpg')
# Do undistortion
test_undistort_image = undistortImage(test_distort_image, mtx, dist)筛选图像
从我们作为输入的视频可以看出,车辆会经历颠簸、车道线不清晰、路面颜色突变,路边障碍物阴影干扰等复杂工况。因此,需要将这些复杂的场景筛选出来,确保后续的算法能够在这些复杂场景中正确地检测出车道线。
使用以下代码将视频中的图像数据提取,进行畸变修正处理后,存储在名为original_image的文件夹中,以供挑选。
video_input = 'project_video.mp4'
cap = cv2.VideoCapture(video_input)
count = 1
while(True):
ret, image = cap.read()
if ret:
undistort_image = undistortImage(image, mtx, dist)
cv2.imwrite('original_image/' + str(count) + '.jpg', undistort_image)
count += 1
else:
break
cap.release()
在original_image文件夹中,挑选出以下6个场景进行检测。这6个场景既包含了视频中常见的正常直道、正常弯道工况,也包含了具有挑战性的阴影、明暗剧烈变化的工况。如果后续的高级车道线检测算法能够完美处理以上六种工况,那将算法应用到视频中,也会得到完美的车道线检测效果。可见,如开篇所讲,本文完全是基于传统图像处理算法进行车道检测的,其依赖于高度定义化,手工特征提取和启发式方法,通常是需要后后处理技术,而这往往使得计算量大,不利于道路场景多变下的应用扩展。
透视变换
在完成图像的畸变修正后,就要将注意力转移到车道线。与《无人驾驶技术入门(十四)| 初识图像之初级车道线检测》中技术类似,这里需要定义一个感兴趣区域。很显然,我们的感兴趣区域就是车辆正前方的这个车道。为了获取感兴趣区域,我们需要对自车正前方的道路使用一种叫做透视变换的技术。
“透视”是图像成像时,物体距离摄像机越远,看起来越小的一种现象。在真实世界中,左右互相平行的车道线,会在图像的最远处交汇成一个点。这个现象就是“透视成像”的原理造成的。
以立在路边的交通标志牌为例,它在摄像机所拍摄的图像中的成像结果一般如下下图所示

在这幅图像上,原本应该是正八边形的标志牌,成像成为一个不规则的八边形。
通过使用透视变换技术,可以将不规则的八边形投影成规则的正八边形。应用透视变换后的结果对比如下:

透视变换的原理:首先新建一幅跟左图同样大小的右图,随后在做图中选择标志牌位于两侧的四个点(如图中的红点),记录这4个点的坐标,我们称这4个点为src_points。图中的4个点组成的是一个平行四边形。
由先验知识可知,左图中4个点所围成的平行四边形,在现实世界中是一个长方形,因此在右边的图中,选择一个合适的位置,选择一个长方形区域,这个长方形的4个端点一一对应着原图中的src_points,我们称新的这4个点为dst_points。
得到src_points,dst_points后,我们就可以使用OpenCV中计算投影矩阵的函数cv2.getPerspectiveTransform(src_points, dst_points)算出src_points到dst_points的投影矩阵和投影变换后的图像了。
使用OpenCV库实现透视变换的代码如下:
#################################################################
# Step 3 : Warp image based on src_points and dst_points
#################################################################
# The type of src_points & dst_points should be like
# np.float32([ [0,0], [100,200], [200, 300], [300,400]])
def warpImage(image, src_points, dst_points):
image_size = (image.shape[1], image.shape[0])
# rows = img.shape[0] 720
# cols = img.shape[1] 1280
M = cv2.getPerspectiveTransform(src, dst)
Minv = cv2.getPerspectiveTransform(dst, src)
warped_image = cv2.warpPerspective(image, M,image_size, flags=cv2.INTER_LINEAR)
return warped_image, M, Minv
同理,对于畸变修正过的道路图像,我们同样使用相同的方法,将我们感兴趣的区域做透视变换。
如下图所示,我们选用一张在直线道路上行驶的图像,沿着左右车道线的边缘,选择一个梯形区域,这个区域在真实的道路中应该是一个长方形,因此我们选择将这个梯形区域投影成为一个长方形,在右图横坐标的合适位置设置长方形的4个端点。最终的投影结果就像“鸟瞰图”一样。

使用以下代码,通过不断调整src和dst的值,确保在直线道路上,能够调试出满意的透视变换图像。
test_distort_image = cv2.imread('test_images/test4.jpg')
# 畸变修正
test_undistort_image = undistortImage(test_distort_image, mtx, dist)
# 左图梯形区域的四个端点
src = np.float32([[580, 460], [700, 460], [1096, 720], [200, 720]])
# 右图矩形区域的四个端点
dst = np.float32([[300, 0], [950, 0], [950, 720], [300, 720])
test_warp_image, M, Minv = warpImage(test_undistort_image, src, dst)最终,我们把筛选出的6幅图统一应用调整好的src、dst做透视变换。有点费力啊老兄!
提取车道线
在《无人驾驶技术入门(十四)| 初识图像之初级车道线检测》中,我们介绍了通过Canny边缘提取算法获取车道线待选点的方法,随后使用霍夫直线变换进行了车道线的检测。在这里,我们也尝试使用边缘提取的方法进行车道线提取。
需要注意的是,Canny边缘提取算法会将图像中各个方向、明暗交替位置的边缘都提取出来,很明显,Canny边缘提取算法在处理有树木阴影的道路时,会将树木影子的轮廓也提取出来,这是我们不愿意看到的。
因此我们选用Sobel边缘提取算法。Sobel相比于Canny的优秀之处在于,它可以选择横向或纵向的边缘进行提取。从投影变换后的图像可以看出,我们关心的正是车道线在横向上的边缘突变。
封装一下OpenCV提供的cv2.Sobel()函数,将进行边缘提取后的图像做二进制图的转化,即提取到边缘的像素点显示为白色(值为1),未提取到边缘的像素点显示为黑色(值为0)。
def absSobelThreshold(img, orient='x', thresh_min=30, thresh_max=100):
# Convert to grayscale
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# Apply x or y gradient with the OpenCV Sobel() function
# and take the absolute value
if orient == 'x':
abs_sobel = np.absolute(cv2.Sobel(gray, cv2.CV_64F, 1, 0))
if orient == 'y':
abs_sobel = np.absolute(cv2.Sobel(gray, cv2.CV_64F, 0, 1))
# Rescale back to 8 bit integer
scaled_sobel = np.uint8(255*abs_sobel/np.max(abs_sobel))
# Create a copy and apply the threshold
binary_output = np.zeros_like(scaled_sobel)
# Here I'm using inclusive (>=, <=) thresholds, but exclusive is ok too
binary_output[(scaled_sobel >= thresh_min) & (scaled_sobel <= thresh_max)] = 1
# Return the result
return binary_output横向的Sobel边缘提取算法,无法很好地处理路面阴影、明暗交替的道路工况。
无法使用边缘提取的方法提取车道线后,我们开始将颜色空间作为突破口。
在以上6个场景中,虽然路面明暗交替,而且偶尔会有阴影覆盖,但黄色和白色的车道线是一直都存在的。因此,我们如果能将图中的黄色和白色分割出来,然后将两种颜色组合在一幅图上,就能够得到一个比较好的处理结果。
一幅图像除了用RGB(红绿蓝)三个颜色通道表示以外,还可以使用HSL(H色相、S饱和度、L亮度)和Lab(L亮度、a红绿通道、b蓝黄)模型来描述图像,三通道的值与实际的成像颜色如下图所示。

我们可以根据HSL模型中的L(亮度)通道来分割出图像中的白色车道线,同时可以根据Lab模型中的b(蓝黄)通道来分割出图像中的黄色车道线,再将两次的分割结果,去合集,叠加到一幅图上,就能得到两条完整的车道线了。
使用OpenCV提供的cv2.cvtColor()接口,将RGB通道的图,转为HLS通道的图,随后对L通道进行分割处理,提取图像中白色的车道线。
使用OpenCV提供的cv2.cvtColor()接口,将RGB通道的图,转为Lab通道的图,随后对b通道进行分割处理,提取图像中黄色的车道线。
根据以上试验可知,L通道能够较好地分割出图像中的白色车道线,b通道能够较好地分割出图像中的黄色车道线。即使面对树木阴影和路面颜色突变的场景,也能尽可能少地引入噪声。
最后,我们使用以下代码,将两个通道分割的图像合并。
hlsL_binary = hlsLSelect(test_warp_image)
labB_binary = labBSelect(test_warp_image)
combined_binary = np.zeros_like(hlsL_binary)
combined_binary[(hlsL_binary == 1) | (labB_binary == 1)] = 1以上仅仅是车道线提取的方法之一。除了可以通过HSL和Lab颜色通道,这种基于规则的方法,分割出车道线外,还可以使用基于深度学习的方法。它们目的都是为了能够稳定地将车道线从图像中分割出来。
车道线检测
在检测车道线前,需要粗定位车道线的位置。为了方便理解,这里引入一个概念——直方图。
以下面这幅包含噪点的图像为例,进行直方图的介绍

我们知道,我们处理的图像的分辨率为1280*720,即720行,1280列。如果我将每一列的白色的点数量进行统计,即可得到1280个值。将这1280个值绘制在一个坐标系中,横坐标为1-1280,纵坐标表示每列中白色点的数量,那么这幅图就是“直方图”,如下图所示:

图片出处:优达学城(Udacity)无人驾驶工程师学位
将两幅图叠加,效果如下:

图片出处:优达学城(Udacity)无人驾驶工程师学位
找到直方图左半边最大值所对应的列数,即为左车道线所在的大致位置;找到直方图右半边最大值所对应的列数,即为右车道线所在的大致位置。
使用直方图找左右车道线大致位置的代码如下,其中leftx_base和rightx_base即为左右车道线所在列的大致位置。
跟踪车道线
视频数据是连续的图片,基于连续两帧图像中的车道线不会突变的先验知识,我们可以使用上一帧检测到的车道线结果,作为下一帧图像处理的输入,搜索上一帧车道线检测结果附近的点,这样不仅可以减少计算量,而且得到的车道线结果也更稳定,如下图所示。

图中的细黄线为上一帧检测到的车道线结果,绿色阴影区域为细黄线横向扩展的一个区域,通过搜索该区域内的白点坐标,即可快速确定当前帧中左右车道线的待选点。
最终视频处理如下:
nx = 9
ny = 6
ret, mtx, dist, rvecs, tvecs = getCameraCalibrationCoefficients('camera_cal/calibration*.jpg', nx, ny)
src = np.float32([[580, 460], [700, 460], [1096, 720], [200, 720]])
dst = np.float32([[300, 0], [950, 0], [950, 720], [300, 720]])
video_input = 'project_video.mp4'
video_output = 'result_video.mp4'
cap = cv2.VideoCapture(video_input)
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter(video_output, fourcc, 20.0, (1280, 720))
detected = False
while(True):
ret, image = cap.read()
if ret:
undistort_image = undistortImage(image, mtx, dist)
warp_image, M, Minv = warpImage(undistort_image, src, dst)
hlsL_binary = hlsLSelect(warp_image)
labB_binary = labBSelect(warp_image, (205, 255))
combined_binary = np.zeros_like(sx_binary)
combined_binary[(hlsL_binary == 1) | (labB_binary == 0)] = 1
left_fit = []
right_fit = []
ploty = []
if detected == False:
out_img, left_fit, right_fit, ploty = fit_polynomial(combined_binary, nwindows=9, margin=80, minpix=40)
if (len(left_fit) > 0 & len(right_fit) > 0) :
detected = True
else :
detected = False
else:
track_result, left_fit, right_fit, ploty, = search_around_poly(combined_binary, left_fit, right_fit)
if (len(left_fit) > 0 & len(right_fit) > 0) :
detected = True
else :
detected = False
result = drawing(undistort_image, combined_binary, warp_image, left_fitx, right_fitx)
out.write(result)
else:
break
cap.release()
out.release()
不过每个相机的畸变参数需要重新标定,不是换个视频就能直接使用这套代码里面的参数,需要调整。效果不会差,因为中国的高速路况比这个视频里的路况要好。
注:上述大部分参考知乎大神陈光的文章,如果有转载请注明出处,侵删!!
其他
车辆检测功能可参考这里
更多资料详见这里:车道线检测最全资料集锦
还有这里:基于摄像头的车道线检测方法一览
参考文献:
1.https://blog.csdn.net/weixin_38746685/article/details/81613065
2.https://blog.csdn.net/xxxy502/article/details/81018106
3.https://blog.csdn.net/xxxy502/article/details/81018859
4.https://zhuanlan.zhihu.com/p/54866418
5.https://zhuanlan.zhihu.com/c_147309339
6.https://github.com/yang1688899/CarND-Advanced-Lane-Lines
7.https://wenku.baidu.com/view/69dbf2a0f61fb7360b4c6577.html