Faster R-CNN——RPN网络+ROI池化 (目标检测)(two-stage)(深度学习)(NIPS 2015)
论文名称:《 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 》
论文下载:https://papers.nips.cc/paper/5638-faster-r-cnn-towards-real-time-object-detection-with-region-proposal-networks.pdf
论文代码:https://github.com/rbgirshick/py-faster-rcnn
 Faster RCNN 的网络结构(基于 VGG16)
Faster RCNN 的网络结构(基于 VGG16)
Faster 实现了端到端的检测,并且几乎达到了效果上的最优,速度方向的改进仍有余地。
一、网络结构:
对于提取候选框最常用的 SelectiveSearch 方法,提取一副图像大概需要 2s 的时间,改进的 EdgeBoxes 算法将效率提高到了 0.2s,但是这还不够。
本文发现候选框提取不一定要在原图上做,特征图上同样可以,低分辨率特征图意味着更少的计算量,基于这个假设提出的RPN(RegionProposal Network),完美解决了这个问题。
Faster R-CNN可以简单地看做“区域生成网络RPNs + Fast R-CNN”的系统,用区域生成网络代替Fast R-CNN中的Selective Search方法。
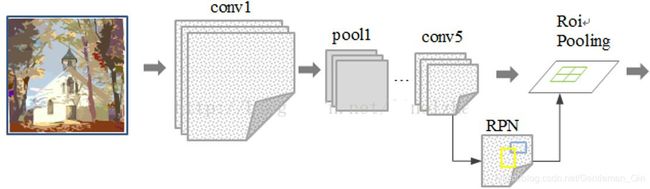 网络拓扑
网络拓扑
通过添加额外的 RPN 分支网络,将候选框提取合并到深度网络中,这正是 Faster-RCNN 里程碑式的贡献。
 Faster R-CNN网络结构
Faster R-CNN网络结构
RPN 网络的特点在于通过滑动窗口的方式实现候选框的提取,每个滑动窗口位置生成 9 个候选窗口(不同尺度、不同宽高),提取对应 9 个候选窗口(anchor)的特征,用于目标分类和边框回归,与 FastRCNN 类似。
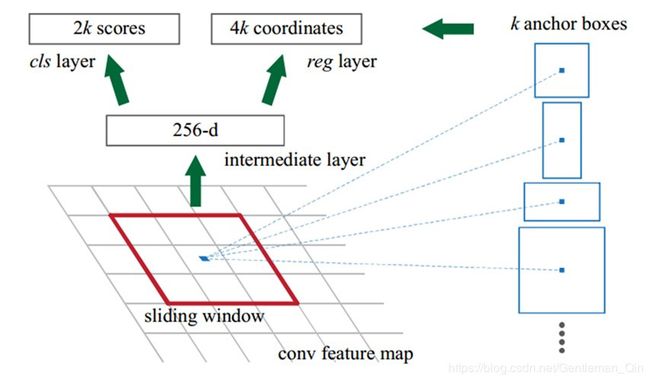 RPN网络结构
RPN网络结构
目标分类只需要区分候选框内特征为前景或者背景。
边框回归确定更精确的目标位置,基本网络结构如下图所示:
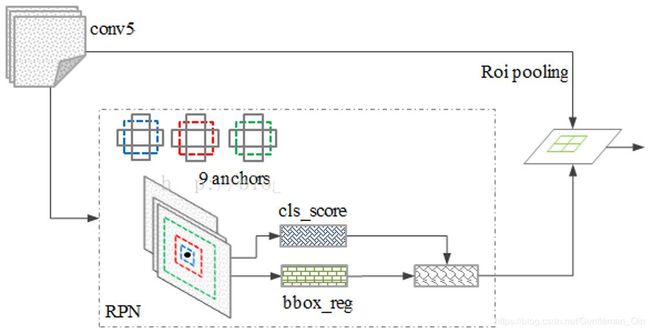 边框回归
边框回归
训练过程中,涉及到的候选框选取,选取依据:
1)丢弃跨越边界的 anchor;
2)与样本重叠区域大于 0.7 的 anchor 标记为前景,重叠区域小于 0.3 的标定为背景;
对于每一个位置,通过两个全连接层(目标分类 + 边框回归)对每个候选框(anchor)进行判断,并且结合概率值进行舍弃(仅保留约 300 个 anchor),没有显式地提取任何候选窗口,完全使用网络自身完成判断和修正。
二、亮点解析:
1、RoI Pooling:
在 Faster RCNN中使用 RoI Pooling,以便使生成的候选框region proposal映射产生固定大小的feature map,进行之后的分类和回归。通过下图解释RoiPooling的工作原理:
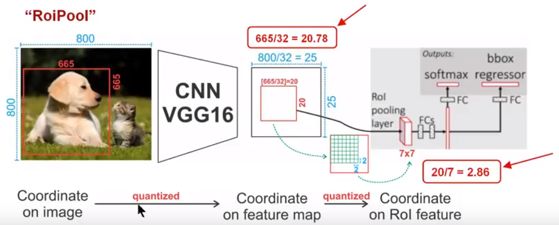
(1)Conv layers使用的是VGG16,feat_stride=32(即表示,经过网络层后图片缩小为原图的1/32),原图800*800,最后一层特征图feature map大小:25*25;
(2)假定原图中有一region proposal,大小为665*665,这样,映射到特征图中的大小:665/32=20.78,即20.78*20.78,如果你看过Caffe的Roi Pooling的C++源码,在计算的时候会进行取整操作,于是,进行所谓的第一次量化,即映射的特征图大小为20*20;
(3)假定pooled_w=7,pooled_h=7,即pooling后固定成7*7大小的特征图,所以,将上面在 feature map上映射的20*20的 region proposal划分成49个同等大小的小区域,每个小区域的大小20/7=2.86,即2.86*2.86,此时,进行第二次量化,故小区域大小变成2*2;
(4)每个2*2的小区域里,取出其中最大的像素值,作为这一个区域的‘代表’,这样,49个小区域就输出49个像素值,组成7*7大小的feature map;
总结,通过上面可以看出,经过两次量化,即将浮点数取整,原本在特征图上映射的20*20大小的region proposal,偏差成大小为14*14的,这样的像素偏差势必会对后层的回归定位产生影响( 所以产生了替代方案,RoiAlign)。
2、RPN网络:
 RPN网络之前
RPN网络之前
前面5层:
(1)首先,输入图片大小是 224*224*3(这个3是三个通道,也就是RGB三种);
(2)然后 layer1 的卷积核维度是 7*7*3*96 (所以大家要认识到卷积核都是4维的,在caffe的矩阵计算中都是这么实现的);
(3)所以conv1得到的结果是110*110*96 (这个110来自于 (224-7+pad)/2 +1 ,这个pad是补零填充,也就是在图片的周围补充像素,这样做的目的是为了能够整除,除以2是因为2是图中的stride, 这个计算方法在上面建议的文档中有说明与推导的);
(4)然后做一次池化,得到pool1, 池化的核的大小是3*3,所以池化后图片的维度是55*55*96 ( (110-3+pad)/2 +1 =55 );
(5)然后接着就是再一次 layer2 卷积,这次的卷积核的维度是5*5*96*256 ,得到conv2:26*26*256;
(6)后面就是类似的过程,有些地方除法除不尽,作者做了填充,在caffe的prototxt文件中,可以看到每一层的pad的大小;
(7)最后作者取的是conv5的输出,也就是13*13*256送给RPN网络的;
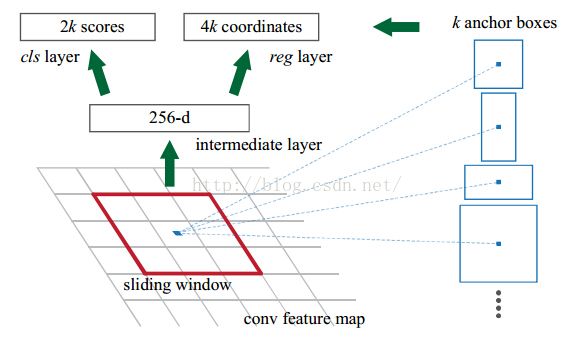 RPN网络(2类别分类,4坐标回归)
RPN网络(2类别分类,4坐标回归)
RPN的原理:
1、前面我们指出,这个conv feature map的维度是13*13*256的;
2、作者在文章中指出,以3*3的正方形anchor为例,它作为sliding window的大小是3*3的,那么如何得到这个1*256的向量呢? 这个很简单了,我们只需要一个3*3*256*256这样的一个4维的卷积核,就可以将每一个3*3的sliding window 卷积成一个1*256的向量;
作者这里画的示意图 仅仅是 针对一个sliding window的;在实际实现中,我们有很多个sliding window,且大小不一, 即9中anchor,所以得到的并不是一维的256-d向量,实际上还是一个3维的矩阵数据结构;可能写成for循环做sliding window大家会比较清楚,当用矩阵运算的时候,会稍微绕些;
3、然后就是k=9,所以cls layer就是18个输出节点了,每个anchor生成一个2*1的向量,9个就是18*1。那么在256-d和cls layer之间使用一个1*1*256*2的卷积核,就可以得到一个anchor在一个位置上的对应的cls layer,当然这个1*1*256*2的卷积核就是大家平常理解的全连接;所以全连接只是卷积操作的一种特殊情况(当卷积核的大小与图片大小相同的时候,其实所谓的卷积就是全连接了,因为卷积核没有做移动,所以其不包含图像中个像素的相互之间的位置关系,这一点和FC层是一致的);
4、reg layer也是一样了,reg layer的输出是36个,所以对应的卷积核是1*1*256*(36/9),这样就可以得到reg layer的输出了;
5、然后cls layer 和reg layer后面都会接到自己的损失函数上,给出损失函数的值,同时会根据求导的结果,给出反向传播的数据,这个过程读者还是参考上面给的文档,写的挺清楚的;
三、训练过程:
RPN与Fast-R-CNN共享卷积层,使用4-step交替训练法进行RPN和Fast R-CNN的训练。
从模型训练的角度来看,通过使用共享特征交替训练的方式,达到接近实时的性能,交替训练方式描述为:
1)根据现有网络初始化权值 w,训练 RPN;
2)用 RPN 提取训练集上的候选区域,用候选区域训练 FastRCNN,更新权值 w;
3)重复 1、2,直到收敛。
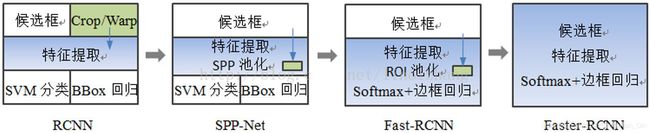
因为 Faster-RCNN,这种基于 CNN 的 real-time 的目标检测方法看到了希望,在这个方向上有了进一步的研究思路。至此,我们来看一下 RCNN 网络的演进,如下图所示:
四步交替训练:
(1)训练RPN,使用ImageNet预训练模型对RPN进行初始化,并进行端到端微调。
(2)使用由步骤1 RPN生成的候选框,通过Fast R-CNN训练单独的检测网络。 该检测网络也由ImageNet预训练模型初始化。
(3)使用检测网络初始化RPN训练,固定共享的卷积层,只微调RPN特有的层。 现在这两个网络共享卷积层。
(4)保持共享卷积层固定,微调Fast R-CNN独有的层。
四、测试过程:
(1)首先向CNN网络【ZF或VGG-16】输入任意大小图片;
(2)经过CNN网络前向传播至最后共享的卷积层,一方面得到供RPN网络输入的特征图,另一方面继续前向传播至特有卷积层,产生更高维特征图;
(3)供RPN网络输入的特征图经过RPN网络得到区域建议和区域得分,并对区域得分采用非极大值抑制【阈值为0.7】,输出其Top-N【文中为300】得分的区域建议给RoI池化层;
(4)第2步得到的高维特征图和第3步输出的候选框同时输入RoI池化层,提取对应候选框的特征;
(4)第4步得到的候选框特征通过全连接层后,输出该区域的分类得分以及回归后的bounding-box。
五、创新点:
- 用RPN网络来代替耗时的Selective Search方法来生成候选框,提高检测速度。
- RPN网络与检测网络共享卷积特征,使生成候选框的成本几乎降为零。
六、存在问题:
(1)仍然不能实时进行目标检测。
(2)还是没有一种简单得到候选框的方法。