实习项目之(二)APP热点标签分析
APP热点标签分析
项目角色: 核心研发 开发组人员: 1
工作内容:
通过hive数据仓库,hivesql语句和udf/udaf/udtf对海量数据完成统计分析,找到热度标签,通过热度标签能够提高APP的下载量和使用量
一、主要过程基本点
1.数据仓库工作的四大法宝,四层项目目录要建好
(1)config:设定配置参数,这个里面只是涉及到了hive的参数设定
文件名称(set_env.sh)
内容:
![]()
(2)create:创建表使用的sql语句的存储文件
1.建立相应的输入输出表

标准格式兄弟
(3)deal:
1.加载到初始表的语句

2.加载到结果表即output表的sh文件
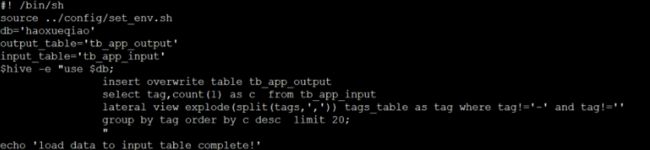
3.定义一个main.sh来依次执行这些sh文件
首先,上面的两个过程已经分别验证并通过
接下来,看看总的执行脚本咋写
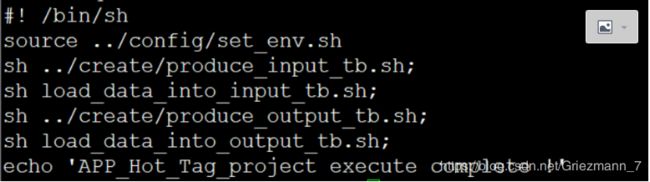
小项目,也好写,总而言之一句话,建表导数据完了!
二、遇到的问题
1.移动文件
![]()
![]()
为啥第一次显示权限不够,第二次加上./就行了呢
结论:要不就啥都不加,要加不能加个/上去
/ 根目录
~代表你的/home/用户明目录
2.sh文件中第一行 #! /bin/sh和 #! /bin/bash的区别
(1) sh 一般设成 bash 的软链 (symlink)
(2) 在一般的 linux 系统当中(例外如 FreeBSD,OpenBSD 等),使用 sh 调用执行脚本相当于打开了bash 的 POSIX 标准模式
(3) 也就是说 /bin/sh 相当于 /bin/bash --posix
所以,它们之间的各种差异都是来自 POSIX 标准模式 和 bash 的差异,比如 用 : 截取字符串,不能用 let , 遇错中断 等等,在使用时需要注意。
3.加载本地数据到hive表中
load data local inpath inpathname overwrite into table tbname;
4.向输出表输出数据(即将一个表的查询结果输出到另一个表中)
insert into tb outputtb
select tag,count(1) as rank from inputtb lateral view explode(split(tags,','))
tags_table as tag where tag!=' ' and tag!='-' group by tag order by
rank desc limit 20;
count(1)的用法:
索性扩充一下:SQL里的count(*)、count(1)、count(column_name)的区别
1、主要区别
1)count(*)所有行进行统计,包含值为null的行。
2)count(column)会对指定列具有的行数进行统计,除去值为NULL的行。
3)count(1)与count(*) 的效果是一样的。
2、性能问题
1)In any case,SELECT COUNT(*) FROM tablename is the best choice.
2)尽量减少SELECT COUNT(*) FROM tablename WHERE COL = 'value' 这种查询。
3)最好不要使用SELECT COUNT(COL) FROM tablename WHERE COL2='value' 这种查询。
注意:
如果表没有主键,那么count(1)比count(*)快。
如果表只有一个字段,count(*)最快。
5.关于sql中的drop、truncate、delete的区别
1、drop删除的是整个表,而delete和truncate删除的是表中的数据
2、delete删除的数据会在log日志中保存,truncate删除的数据不会在log日志中保存
3、删除速度:drop>truncate>delete
4、truncate只能删除table中的数据,而delete既可以删除table中的数据,也可以删除索引
5、对于foreign key约束的引用表,不能使用truncate table,而应该使用不带where子句的delete语句
此外需要注意的是:hive中没有delete操作、update也没有
----把自己做过的项目又整体回顾了一遍,真好
---------后续待继续学习补充,

Aupa Atleti!
---------------------------谨以此博客作为自己的学习记录,如有发现问题之处,欢迎指正。