计算机视觉(十二):Mask R-CNN
1 - 引言
Mask R-CNN是在Faster R-CNN架构为基础上改进的一种目标检测架构,并且能够有效的完成高质量的语义分割
Mask R-CNN主要结构如下图所示:

那我们就来一步步介绍Mask R-CNN的部分
2 - 特征提取方法
通过 ResNeXt-101+FPN 用作特征提取网络,达到 state-of-the-art 的效果。
之前我们学习了残差网络,现在我们来学习一下FPN的作用
2.1 - FPN
论文:feature pyramid networks for object detection
FPN (Feature Pyramid Networks )称为特征金字塔网络,因为低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而本文不一样的地方在于预测是在不同特征层独立进行的。
下图是4中特征融合的方式
(a)图像金字塔,即将图像做成不同的scale,然后不同scale的图像生成对应的不同scale的特征。这种方法的缺点在于增加了时间成本。有些算法会在测试时候采用图像金字塔。
(b)像SPP net,Fast RCNN,Faster RCNN是采用这种方式,即仅采用网络最后一层的特征。
(c)像SSD(Single Shot Detector)采用这种多尺度特征融合的方式,没有上采样过程,即从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。作者认为SSD算法中没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很有帮助的。
(d)本文作者是采用这种方式,顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的。

论文中除了介绍了这4中融合方法外,还将这两种特征融合进行了对比,如下图
都是由自顶向下进行特征融合,区别在于一个是经过多次上采样并融合特征,使用最后融合的特征来进行预测,而下面的网络则是在每一个特征层中独立进行预测

在论文中,FPN的模型结构如下图所示:

主要使用了两种技术手段
(1)Bottom-up pathway(自底向上):

其实就是网络的前向过程。在前向过程中,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。
(2)Top-down pathway and lateral connections(自顶向下和横向连接)

自顶向下的过程采用上采样(upsampling)进行,而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合(merge)。在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应(aliasing effect)。并假设生成的feature map结果是P2,P3,P4,P5,和原来自底向上的卷积结果C2,C3,C4,C5一一对应。
之后作者写了FPN在RPN和fast R-CNN上面的应用
- Feature Pyramid Networks for RPN
RPN网络是以主网络的某个卷积层输出的feature map作为输入,简单讲就是只用这一个尺度的feature map。但是现在要将FPN嵌在RPN网络中,生成不同尺度特征并融合作为RPN网络的输入。在每一个scale层,都定义了不同大小的anchor,对于P2,P3,P4,P5,P6这些层,定义anchor的大小为 3 2 2 , 6 4 2 , 12 8 2 , 25 6 2 , 51 2 2 32^2,64^2,128^2,256^2,512^2 322,642,1282,2562,5122,另外每个scale层都有3个长宽对比度:1:2,1:1,2:1。所以整个特征金字塔有15种anchor。
如下表Table1。网络这些结果都是基于ResNet-50。评价标准采用AR,AR表示Average Recall,AR右上角的100表示每张图像有100个anchor,AR的右下角s,m,l表示COCO数据集中object的大小分别是小,中,大。feature列的大括号{}表示每层独立预测。
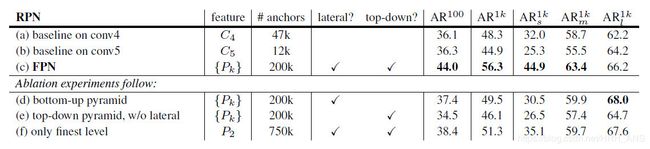
从(a)(b)(c)的对比可以看出FRN的作用确实很明显。另外(a)和(b)的对比可以看出高层特征并非比低一层的特征有效。
(d)表示只有横向连接,而没有自顶向下的过程,也就是仅仅对自底向上(bottom-up)的每一层结果做一个11的横向连接和33的卷积得到最终的结果,有点像Fig1的(b)。从feature列可以看出预测还是分层独立的。作者推测(d)的结果并不好的原因在于在自底向上的不同层之间的semantic gaps比较大。
(e)表示有自顶向下的过程,但是没有横向连接,即向下过程没有融合原来的特征。这样效果也不好的原因在于目标的location特征在经过多次降采样和上采样过程后变得更加不准确。
(f)采用finest level层做预测(参考Fig2的上面那个结构),即经过多次特征上采样和融合到最后一步生成的特征用于预测,主要是证明金字塔分层独立预测的表达能力。显然finest level的效果不如FPN好,原因在于PRN网络是一个窗口大小固定的滑动窗口检测器,因此在金字塔的不同层滑动可以增加其对尺度变化的鲁棒性。另外(f)有更多的anchor,说明增加anchor的数量并不能有效提高准确率。
- Feature Pyramid Networks for Fast RCNN

(a)(b)(c)的对比证明在基于区域的目标卷积问题中,特征金字塔比单尺度特征更有效。(c)(f)的差距很小,作者认为原因是ROI pooling对于region的尺度并不敏感。因此并不能一概认为(f)这种特征融合的方式不好,博主个人认为要针对具体问题来看待,像上面在RPN网络中,可能(f)这种方式不大好,但是在Fast RCNN中就没那么明显。
总结
FPN(Feature Pyramid Networks)算法,是一种特征融合算法,将高层的特征与底层的信息融合,得到融合特征,并提取该特征进行预测,可以达到更好的预测效果。
3 - 区域选择方法
3.1 - RPN(Region Proposal Networks)
从Mask R-CNN的结构上我们可以看到选取候选框的方法沿用了Faster R-CNN所采用的RPN网络,下面就研究一下RPN的原理实现

RPN主要可以包括三步:
(1) 输入图片经卷积网络(如 VGGNet 和 ResNet)处理后, 会输出最后一个卷积层的 feature maps;

(2)在 feature maps 上进行滑窗操作(sliding window). 滑窗尺寸为 n × n n×n n×n, 如 3 × 3 3×3 3×3.
对于每个滑窗, 会生成 9 个 anchors, anchors 具有相同的中心 c e n t e r = x a , y a c e n t e r = x a , y a , center=x_a,y_acenter=x_a,y_a, center=xa,yacenter=xa,ya, 但 anchors 具有 3 种不同的长宽比(aspect ratios) 和 3 种不同的尺度(scales), 计算是相对于原始图片尺寸的, 如下图:
对于每个 anchor, 计算 anchor 与 ground-truth bounding boxes 的重叠部分(overlap) 值 p ∗ p^∗ p∗ - IoU(intersection over union ):
- 如果 IoU > 0.7, 则 p ∗ = 1 p^∗=1 p∗=1;
- 如果 IoU < 0.7, 则 p ∗ = − 1 p^∗=-1 p∗=−1;
- 其他, 则 p ∗ = 0 p^∗=0 p∗=0;
(3) 从 feature maps 中提取 3×3 的空间特征(上图中红色方框部分), 并将其送入一个小网络. 该网络具有两个输出任务分支: classification(cls) 和 regression(reg).
regression 分支输出预测的边界框bounding-box: (x, y, w, h).
classification 分支输出一个概率值, 表示 bounding-box 中是否包含 object (classid = 1), 或者是 background (classid = 0), no object.

3.1.1 Anchors
在每个滑动窗口位置,我们同时预测多个region proposals,其中每个位置的最大可能建议的数量表示为k。所以reg层有4k输出来编码k个box的坐标(可能是一个角的坐标(x,y)+width+height),cls层输出2k的分数来估计每个proposal是object的概率或者不是的概率。这k个proposals是k个参考框的参数化,我们把这些proposals叫做Anchors(锚点)。锚点位于问题的滑动窗口中,并与比例和纵横比相关联。默认情况下,我们使用3个尺度和3个纵横比,在每个滑动位置上产生k=9个锚点。对于W H大小的卷积特性图(通常为2,400),总共有WH*k个锚点
分析
首先我们需要知道anchor的本质是什么,本质是SPP(spatial pyramid pooling)思想的逆向。而SPP本身是做什么的呢,就是将不同尺寸的输入resize成为相同尺寸的输出。所以SPP的逆向就是,将相同尺寸的输出,倒推得到不同尺寸的输入。
接下来是anchor的窗口尺寸,这个不难理解,三个面积尺寸( 12 8 2 , 25 6 2 , 51 2 2 128^2,256^2,512^2 1282,2562,5122),然后在每个面积尺寸下,取三种不同的长宽比例( 1 : 1 , 1 : 2 , 2 : 1 1:1,1:2,2:1 1:1,1:2,2:1).这样一来,我们得到了一共9种面积尺寸各异的anchor。示意图如下:

并且论文中Anchors还具有两个特性
- 平移不变性
我们的方法的一个重要特性是是平移不变性,锚点本身和计算锚点的函数都是平移不变的。如果在图像中平移一个目标,那么proposal也会跟着平移,这时,同一个函数需要能够在任何位置都预测到这个proposal。我们的方法可以保证这种平移不变性。作为比较,the MultiBox method使用k聚类方法生成800个锚点,这不是平移不变的。因此,MultiBox并不保证当一个对象被平移式,会生成相同的proposal。
平移不变性也减少了模型的尺寸,当锚点数k=9时MultiBox有一个(4+1)*800维全连接的输出层,而我们的方法有一个(4+2)*9维的卷积输出层。因此,我们输出层的参数比MultiBox少两个数量级(原文有具体的数,感觉用处不大,没有具体翻译)。如果考虑到feature projection层,我们的建议层仍然比MultiBox的参数少了一个数量级。我们希望我们的方法在像PASCAL VOC这样的小数据集上的风险更小
- 多尺度

(a.建立了图像和特征图的金字塔,分类器在所有的尺度上运行。b. 具有多个尺寸/大小的过滤器金字塔在feature map上运行。c. 我们在回归函数中使用了参考框的金字塔。)
第一种方法是基于图像/特征金字塔,例如,在DPM和基于cnn方法的方法。这些图像在多个尺度上进行了调整,并且为每个尺度计算特征图(占用或深度卷积特性)(图1(a))。这种方法通常很有用,但很耗费时间。第二种方法是在feature map上使用多个尺度(和/或方面比率)的滑动窗口。例如,在DPM中,不同方面比率的模型分别使用不同的过滤大小(如5 7和7 5)进行单独训练。如果这种方法用于处理多个尺度,它可以被认为是一个过滤器金字塔(图1(b))。第二种方法通常是与第一种方法共同使用的
相比而言,我们基于锚点的方法建立在锚点金字塔上,这更节省成本。我们的方法对多个尺度和纵横比的锚点框进行了分类和回归。它只依赖于单一尺度的图像和feature map,并使用单一大小的过滤器(feature map上的滑动窗口)。我们通过实验展示了这个方案对处理多个尺度和大小的影响(表8)。

3.1.2 损失函数
为了训练RPNs,我们将一个二进制类标签(是否是object)分配给每个锚点。会给这两种锚点设置成正标签:1)跟真值框的交并比最高的。2)跟真值框的交并比大于0.7的。因此,一个真值框可以对应多个正标签的锚点。通常第二个条件足以确定正样本,我们还用第一种情况的原因是,有的时候第二种情况找不到正样本。如果一个锚点跟所有真值框的交并比小于0.3,那马我们就把它设为负样本。正负样本之间的这些样本对训练没有贡献。
有了这些定义,我们在fast R-CNN的多任务损失之后最小化一个目标函数,一张图片的损失函数定义为:

i是每个小批量中锚点的序号, p i p_i pi是锚点的概率, p i ∗ p_i^* pi∗是标签(0或1),t是预测框的参数, t ∗ t^* t∗是标定框的参数, L c l s L_{cls} Lcls是分类损失函数, L r e g L_{reg} Lreg是回归损失函数
3.1.3 训练RPN
RPN可以通过反向传播和随机梯度下降来端到端训练。我们遵循以图像为中心的采样策略,开始训练这个网络。每个小批次都来自同一张照片,照片包含许多正负锚点示例。对所有锚点的损失函数进行优化是可行的,但这将偏向于负样本,因为它们多。相反,我们在一个图像中随机抽取256个锚点来计算一个小批的损失函数,其中采样的正和负锚点的比例是1:1。如果一个图像中有少于128个正的样本,我们用负样本填充。
我们随机地初始化所有的新层,方法是用标准偏差0.01的零均值高斯分布来初始化权重。通常,所有其他层(共享卷积层)都是通过预先培训练一个用于ImageNet分类的模型来初始化的。我们对ZF网络的所有层进行调优,并对VGG网络的conv3_1层进行调优,以节省内存。我们对60 k小批量的学习速率为0.001,在PASCAL VOC数据集上的下一个20 k小批量的学习速率是0.0001。我们使用0.9的步长和0.0005的重量衰减。用Caffe实现的。
4 - ROI Align
ROI Align 是在Mask-RCNN这篇论文里提出的一种区域特征聚集方式, 很好地解决了ROI Pooling操作中两次量化造成的区域不匹配(mis-alignment)的问题。实验显示,在检测测任务中将 ROI Pooling 替换为 ROI Align 可以提升检测模型的准确性。
那么在学习ROI Align之前,首先要学习ROI Pooling的相关知识
4.1 ROI Pooling
目标检测architecture通常可以分为两个阶段:
(1)region proposal:给定一张输入image找出objects可能存在的所有位置。这一阶段的输出应该是一系列object可能位置的bounding box。这些通常称之为region proposals或者 regions of interest(ROI),在这一过程中用到的方法是基于滑窗的方式和selective search。
(2)final classification:确定上一阶段的每个region proposal是否属于目标一类或者背景。
这个architecture存在的一些问题是:
产生大量的region proposals 会导致performance problems,很难达到实时目标检测。
在处理速度方面是suboptimal。
无法做到end-to-end training。
这就是ROI pooling提出的根本原因,ROI pooling层能实现training和testing的显著加速,并提高检测accuracy。该层有两个输入:
从具有多个卷积核池化的深度网络中获得的固定大小的feature maps;
一个表示所有ROI的N*5的矩阵,其中N表示ROI的数目。第一列表示图像index,其余四列表示其余的左上角和右下角坐标;
ROI pooling具体操作如下:
根据输入image,将ROI映射到feature map对应位置;
将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同);
对每个sections进行max pooling操作;
这样我们就可以从不同大小的方框得到固定大小的相应 的feature maps。值得一提的是,输出的feature maps的大小不取决于ROI和卷积feature maps大小。ROI pooling 最大的好处就在于极大地提高了处理速度。
说了这么多概念,还是看一个动态图比较清晰,具体过程如下:

说明:在此案例中region proposals 是 5 ∗ 7 5*7 5∗7大小的,在pooling之后需要得到 2 ∗ 2 2*2 2∗2的,所以在 5 ∗ 7 5*7 5∗7的特征图划分成 2 ∗ 2 2*2 2∗2的时候不是等分的,行是5/2,第一行得到2,剩下的那一行是3,列是7/2,第一列得到3,剩下那一列是4。
4.2 - ROI Pooling的局限性
ROI Pooling存在两次量化过程
- 将候选框边界量化为整数点坐标值。
- 将量化后的边界区域平均分割成 k ∗ k k * k k∗k 个单元(bin),对每一个单元的边界进行量化。
事实上,经过上述两次量化,此时的候选框已经和最开始回归出来的位置有一定的偏差,这个偏差会影响检测或者分割的准确度。在论文里,作者把它总结为“不匹配问题(misalignment)。
下面我们用直观的例子具体分析一下上述区域不匹配问题。如 图 所示,这是一个Faster-RCNN检测框架。输入一张 800 ∗ 800 800*800 800∗800的图片,图片上有一个 665 ∗ 665 665*665 665∗665的包围框(框着一只狗)。图片经过主干网络提取特征后,特征图缩放步长(stride)为32。因此,图像和包围框的边长都是输入时的1/32。800正好可以被32整除变为25。但665除以32以后得到20.78,带有小数,于是ROI Pooling 直接将它量化成20。接下来需要把框内的特征池化 7 ∗ 7 7*7 7∗7的大小,因此将上述包围框平均分割成 7 ∗ 7 7*7 7∗7个矩形区域。显然,每个矩形区域的边长为 2.86 2.86 2.86,又含有小数。于是ROI Pooling 再次把它量化到2。经过这两次量化,候选区域已经出现了较明显的偏差(如图中绿色部分所示)。更重要的是,该层特征图上 0.1 0.1 0.1个像素的偏差,缩放到原图就是 3.2 3.2 3.2个像素。那么 0.8 0.8 0.8的偏差,在原图上就是接近 30 30 30个像素点的差别,这一差别不容小觑。

4.3 ROI Align的主要思想和具体方法
为了解决ROI Pooling的上述缺点,作者提出了ROI Align这一改进的方法(如图)。ROI Align的思路很简单:取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作,。值得注意的是,在具体的算法操作上,ROI Align并不是简单地补充出候选区域边界上的坐标点,然后将这些坐标点进行池化,而是重新设计了一套比较优雅的流程,如图所示:
- 遍历每一个候选区域,保持浮点数边界不做量化。
- 将候选区域分割成 k ∗ k k * k k∗k个单元,每个单元的边界也不做量化。
- 在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。


这里对上述步骤的第三点作一些说明:这个固定位置是指在每一个矩形单元(bin)中按照固定规则确定的位置。比如,如果采样点数是1,那么就是这个单元的中心点。如果采样点数是4,那么就是把这个单元平均分割成四个小方块以后它们分别的中心点。显然这些采样点的坐标通常是浮点数,所以需要使用插值的方法得到它的像素值。在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。
事实上,ROI Align 在遍历取样点的数量上没有ROIPooling那么多,但却可以获得更好的性能,这主要归功于解决了misalignment的问题。值得一提的是,我在实验时发现,ROI Align在VOC2007数据集上的提升效果并不如在COCO上明显。经过分析,造成这种区别的原因是COCO上小目标的数量更多,而小目标受misalignment问题的影响更大(比如,同样是0.5个像素点的偏差,对于较大的目标而言显得微不足道,但是对于小目标,误差的影响就要高很多)。
4.4 ROI Align的反向传播
常规的ROI Pooling的反向传播公式如下:

这里, x i x_i xi代表池化前特征图上的像素点; y r j y_{rj} yrj代表池化后的第r个候选区域的第j个点; i ∗ ( r , j ) i^*(r,j) i∗(r,j)代表点 y r j y_{rj} yrj像素值的来源(最大池化的时候选出的最大像素值所在点的坐标)。由上式可以看出,只有当池化后某一个点的像素值在池化过程中采用了当前点Xi的像素值(即满足 i = i ∗ ( r , j ) i=i^*(r,j) i=i∗(r,j)),才在 x i x_i xi处回传梯度。
类比于ROIPooling,ROIAlign的反向传播需要作出稍许修改:首先,在ROIAlign中,是一个浮点数的坐标位置(前向传播时计算出来的采样点),在池化前的特征图中,每一个与 x i ∗ ( r , j ) x_i^*{(r,j)} xi∗(r,j)横纵坐标均小于1的点都应该接受与此对应的点 y r j y_{rj} yrj回传的梯度,故ROI Align 的反向传播公式如下:

上式中,d(.)表示两点之间的距离,Δh和Δw表示 x i x_i xi 与 x i ∗ ( r , j ) x_i^*(r,j) xi∗(r,j) 横纵坐标的差值,这里作为双线性内插的系数乘在原始的梯度上。
5 - Head 层
在ROI Pooling 之后是Head层作为最后的输出分类,网络使用的损失函数为误差分类+检测分类+分割分类,正好对应下图所示
![]()

mask 层结构如下图所示,提供的mask 结构可以和多种RCNN框架结合,提高泛化能力。

6 - 总结
从阅读Mask R-CNN的论文来看,Mask R-CNN所使用的技术还是很多的,模型结构也十分复杂,但是可以发现这篇论文继承了之前R-CNN、Fast R-CNN、Faster R-CNN的成果。主要相对于Faster R-CNN的创新点在于改进了ROI Pooling 和添加了一个mask 分支。