机器人学统计建模中的高斯分布(Gaussian distribution in robotics statistic model)
1.为什么是高斯分布?是什么让高斯分布变得有用而且重要呢?
a.描述高斯分布只需要俩个参数,它们是均值和方差,它们就是该分布的本质信息。(Only two parameters)
b.高斯分布具有一些很好的数学性质,例如:多个高斯分布的乘积可以形成另一个高斯分布。(Good mathematical properties)
c.中心极限定理告诉我们任何随机变量的样本均值的期望都收敛于高斯分布。(Central limit theorem)
以上说明高斯分布是一个为噪声和不确定性建模的合适选择。
2.最大似然估计(MLE)
似然(Likelihood)的定义:似然是当给定模型参数时,随机变量取到观测值的概率,下标 i i i 表示一次特定的观察,在 x x x的多个测量值中,这次观察结果被记为 x i x_{i} xi。
L i k e l i h o o d : p ( { x i } ∣ μ , σ ) Likelihood: p(\begin{Bmatrix}{x_{i}}\end{Bmatrix} | \mu, \sigma) Likelihood:p({xi}∣μ,σ),其中 { x i } \begin{Bmatrix}{x_{i}}\end{Bmatrix} {xi}为观测数据(observed data), μ , σ \mu, \sigma μ,σ为未知参数(unknown parameters) (代表着给定参数,观测到所有数据可能性,所以越大越好)
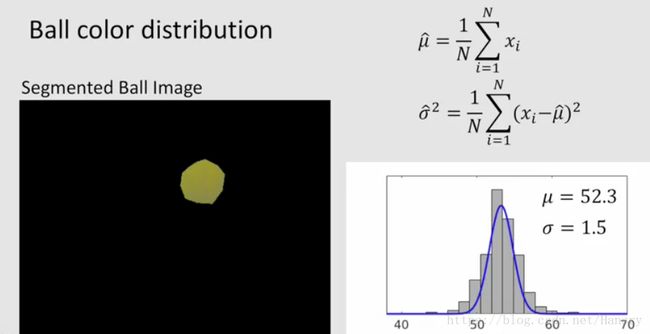
假如我们有一个小球,如下面图片所示,那我们怎么来用高斯模型(要求确定 μ , σ \mu, \sigma μ,σ)来描述其像素值的分布,可以用极大似然法的方法来估计。

怎么通过观察到的数据来估计高斯模型的均值和方差?
(1) 这里需要强调的是,我们拥有数据,而我们需要去估计的是模型的参数。我们对于给定观测数据时,能将似然函数最大化的参数很感兴趣。
如果用数学的方式来表达刚才讲的,我们可以这么写:
μ ^ , σ ^ = a r g m a x μ , σ ( { x i } ∣ μ , σ ) \hat{\mu},\hat{\sigma}=arg \ \underset{\mu,\sigma}{max}(\begin{Bmatrix}{x_{i}}\end{Bmatrix}| \mu,\sigma ) μ^,σ^=arg μ,σmax({xi}∣μ,σ)
其中 μ ^ , σ ^ \hat{\mu},\hat{\sigma} μ^,σ^ 表示对 μ , σ \mu,\sigma μ,σ的估计 。
我们需要最大化的似然函数是所有样本数据的联合概率,如果每个观测不是独立的,问题将很棘手。如果我们假设每一个观测之间都是相互独立的,联合似然概率就可以表达为关于每个样本的似然函数的乘积,公式如下所示:
p ( { x i } ∣ μ , σ ) = ∏ i = 1 N p ( x i ∣ μ , σ ) p(\begin{Bmatrix}{x_{i}}\end{Bmatrix}| \mu,\sigma )=\prod_{i=1}^{N} p(x_{i} | \mu,\sigma ) p({xi}∣μ,σ)=∏i=1Np(xi∣μ,σ)
在这种情况下,我们试着计算 μ \mu μ和 σ \sigma σ的极大似然估计。
由于对数具有单调递增的性质,所以我们最大化似然函数的时候,可以利用对数函数的性质,通过最大化对数似然函数就能找到参数值的极大似然估计,虽然函数值是不同的,但是使目标函数达到最大值的参数值却是一样的。
a r g m a x μ , σ ∏ i = 1 N p ( x i ∣ μ , σ ) = a r g m a x μ , σ l n { ∏ i = 1 N p ( x i ∣ μ , σ ) } = a r g m a x μ , σ ∑ i = 1 N l n p ( x i ∣ μ , σ ) arg\ \underset{\mu,\sigma}{max}\prod_{i=1}^{N} p(x_{i}| \mu,\sigma )\\=arg\ \underset{\mu,\sigma}{max} \ ln \begin{Bmatrix} \prod_{i=1}^{N} p(x_{i}| \mu,\sigma )\end{Bmatrix} \\=arg\ \underset{\mu,\sigma}{max}\sum_{i=1}^{N} \ ln \ p(x_{i}| \mu,\sigma ) arg μ,σmax∏i=1Np(xi∣μ,σ)=arg μ,σmax ln{∏i=1Np(xi∣μ,σ)}=arg μ,σmax∑i=1N ln p(xi∣μ,σ)
从上面公式中,利用对数函数的性质,我们将最大化似然函数转化为每个测量量的似然取对数后的和。
因此,问题就转换为找到 μ , σ \mu,\sigma μ,σ,使得每个测量量的似然的对数和最大。
(2) 这里值得注意的是,我们的所用的似然函数为高斯模型:
p ( x i ∣ μ , σ ) = 1 2 π σ e x p { − ( x i − μ ) 2 σ 2 } p(x_{i}|\mu, \sigma)=\frac{1}{\sqrt{2\pi}\ \sigma}exp \begin{Bmatrix}{- \frac{(x_{i}-\mu)}{2 \sigma^{2}}}\end{Bmatrix} p(xi∣μ,σ)=2π σ1exp{−2σ2(xi−μ)}
利用对数的形式,我们可以转换为:
$ln \ p(x_{i}|\mu, \sigma) \=ln \frac{1}{\sqrt{2\pi}\ \sigma}exp \begin{Bmatrix}{- \frac{(x_{i}-\mu)}{2 \sigma^{2}}}\end{Bmatrix} \= \begin{Bmatrix}{- \frac{(x_{i}-\mu)}{2 \sigma^{2}}-ln \sigma - ln \sqrt{2 \pi}}\end{Bmatrix} $
因此,
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
μ ^ , σ ^ = a r g m a x μ , σ ∑ i = 1 N { − ( x i − μ ) 2 σ 2 − l n σ − l n 2 π } = a r g m a x μ , σ ∑ i = 1 N { − ( x i − μ ) 2 σ 2 − l n σ } ( 其 中 − l n 2 π 不 影 响 结 果 , 所 以 将 其 去 掉 ) = a r g m i n μ , σ ∑ i = 1 N { ( x i − μ ) 2 σ 2 + l n σ } ( 将 其 转 化 为 最 小 化 问 题 , 尽 管 这 俩 个 问 题 是 等 价 的 , 但 是 最 小 化 是 优 化 问 题 的 标 准 形 式 ) \hat{\mu},\hat{\sigma} \\=arg \ \underset{\mu,\sigma}{max}\sum_{i=1}^{N} \ \begin{Bmatrix}{- \frac{(x_{i}-\mu)}{2 \sigma^{2}}-ln \sigma - ln \sqrt{2 \pi}}\end{Bmatrix} \\=arg \ \underset{\mu,\sigma}{max}\sum_{i=1}^{N} \ \begin{Bmatrix}{- \frac{(x_{i}-\mu)}{2 \sigma^{2}}-ln \sigma}\end{Bmatrix} ( 其中- ln \sqrt{2 \pi}不影响结果,所以将其去掉) \\=arg \ \underset{\mu,\sigma}{min}\sum_{i=1}^{N} \ \begin{Bmatrix}{\frac{(x_{i}-\mu)}{2 \sigma^{2}}+ln \sigma}\end{Bmatrix}(将其转化为最小化问题,尽管这俩个问题是等价的,但是最小化是优化问题的标准形式) μ^,σ^=arg μ,σmax∑i=1N {−2σ2(xi−μ)−lnσ−ln2π}=arg μ,σmax∑i=1N {−2σ2(xi−μ)−lnσ}(其中−ln2π不影响结果,所以将其去掉)=arg μ,σmin∑i=1N {2σ2(xi−μ)+lnσ}(将其转化为最小化问题,尽管这俩个问题是等价的,但是最小化是优化问题的标准形式)
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
我们令 J ( μ , σ ) = ∑ i = 1 N { ( x i − μ ) 2 σ 2 + l n σ } J(\mu,\sigma)=\sum_{i=1}^{N} \ \begin{Bmatrix}{\frac{(x_{i}-\mu)}{2 \sigma^{2}}+ln \sigma}\end{Bmatrix} J(μ,σ)=∑i=1N {2σ2(xi−μ)+lnσ},故优化问题变为$\hat{\mu},\hat{\sigma} =arg \ \underset{\mu,\sigma}{min}J(\mu,\sigma) $
在优化过程中,
1.我们先对 μ \mu μ求偏导,并令其等于0,得到 μ ^ \hat{\mu} μ^: ∂ J ∂ μ = 0 → u ^ \frac{\partial J}{\partial \mu}=0 \rightarrow \hat{u} ∂μ∂J=0→u^
2. 用 μ ^ \hat{\mu} μ^代替 μ \mu μ再对 σ \sigma σ求偏导,令其等于0,得到 σ ^ \hat{\sigma} σ^: ∂ J ( u ^ , σ ) ∂ σ = 0 → σ ^ \ \frac{\partial J(\hat{u}, \sigma)}{\partial \sigma}=0 \rightarrow \hat{\sigma} ∂σ∂J(u^,σ)=0→σ^
最后得到一个很简单的结果(具体详细推导这里省略):
μ ^ = 1 N ∑ i = 1 N x i \hat{\mu}=\frac{1}{N}\ \sum_{i=1}^{N} x_{i} μ^=N1 ∑i=1Nxi, 样本的均值
σ ^ 2 = 1 N ∑ i = 1 N ( x i − μ ^ ) 2 \hat{\sigma}^{2}=\frac{1}{N}\ \sum_{i=1}^{N} (x_{i}-\hat {\mu})^{2} σ^2=N1 ∑i=1N(xi−μ^)2, 样本的方差
通过以上推导,我们就可以确定小球像素的分布了。
3.多变量高斯分布(Multivariate Guassian)
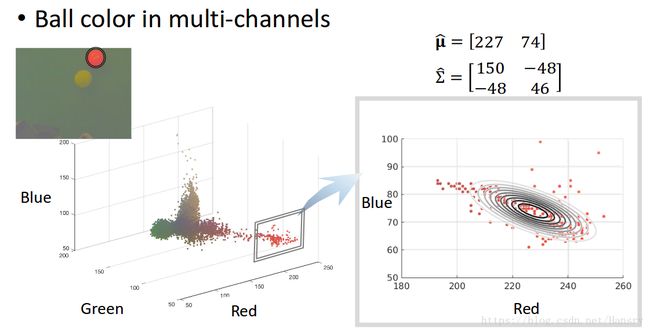
多变量高斯分布使用了多个变量,因此它能够使用更丰富的特征对目标建模,让我们重新思考之前的小球颜色的例子,在那个例子中,我们使用单变量 μ \mu μ,然而颜色本身可以从多个维度来描述,例如,彩色照片经常通过三个颜色通道定义红、绿、蓝。

如果我们在3D图中画出所有像素的RGB值,就能得到如下的色彩分布:
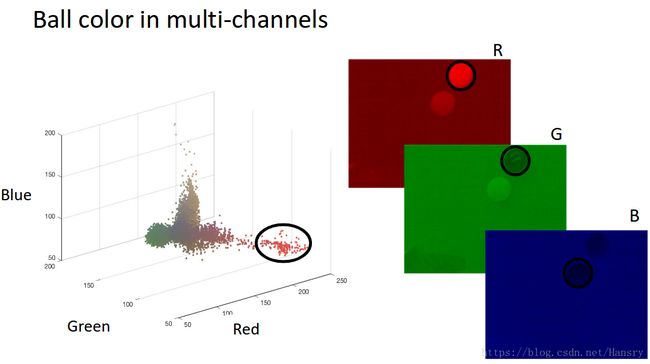
现在考虑使用RGB三通道模型来对红球色彩进行建模。让我们来讨论下在这个例子中高斯分布是怎么工作的。
数学上,多变量高斯分布表示为指数形式(exponential)和比例因子相乘的形式,
p ( x ) = 1 ( 2 π ) D / 2 ∣ ∑ ∣ 1 / 2 e x p { − 1 2 ( x − μ ) T ∑ − 1 ∗ ( x − μ ) } p(x)=\frac{1}{(2\pi)^{D/2}|\sum|^{1/2}}exp\begin{Bmatrix}{-\frac{1}{2}(x-\mu)^{T}\sum^{-1}*(x-\mu)}\end{Bmatrix} p(x)=(2π)D/2∣∑∣1/21exp{−21(x−μ)T∑−1∗(x−μ)}
其中:
D表示维度的数量,如果为RGB,那么D=3。
x \mathbf{x} x 表示样本变量,同时也是一个向量(元素代表各个维度样本的值),我希望获得它们的概率模型。
我们希望得到在高斯分布(Gaussian distribution) x \mathbf{x} x 的概率。
μ \mathbf{\mu} μ 表示均值,同时也是向量。
∑ \mathbf{\sum} ∑ 表示协方差矩阵(covariance matrix),是一个方阵(square matrix)。对于协方差矩阵,由俩个部分组成:对角的项(Diagonal terms)和非对角的项(off-diagonal terms)。对于RGB三个通道的图片,其协方差矩阵是3x3的一个矩阵,如下所示:
∑ = [ σ x 1 2 σ x 1 σ x 2 σ x 1 σ x 3 σ x 2 σ x 1 σ x 2 2 σ x 2 σ x 3 σ x 3 σ x 1 σ x 3 σ x 2 σ x 3 2 ] \sum = \begin{bmatrix} \sigma_{x_{1}}^{2} & \sigma_{x_{1}}\sigma_{x_{2}} & \sigma_{x_{1}}\sigma_{x_{3}} \\\ \sigma_{x_{2}}\sigma_{x_{1}} & \sigma_{x_{2}}^{2} & \sigma_{x_{2}}\sigma_{x_{3}}\\\ \sigma_{x_{3}}\sigma_{x_{1}} & \sigma_{x_{3}}\sigma_{x_{2}} & \sigma_{x_{3}}^{2} \end{bmatrix} ∑=⎣⎡σx12 σx2σx1 σx3σx1σx1σx2σx22σx3σx2σx1σx3σx2σx3σx32⎦⎤
对角线代表变量 x 1 、 x 2 、 x 3 x_{1}、x_{2}、x_{3} x1、x2、x3各自的独立方差,非对角项 σ x 1 σ x 2 \sigma_{x1}\sigma_{x2} σx1σx2、 σ x 2 σ x 3 \sigma_{x2}\sigma_{x3} σx2σx3 等代表了俩个变量的相关性。相关性部分代表了一个变量相对于另一个变量的相关程度。
∣ ∑ ∣ |\mathbf{\sum}| ∣∑∣ 代表协方差矩阵的行列式。
让我们来用蓝色的球举一个例子,我们现在正在处理3维变量RGB,变量的向量包含了我们在红色、绿色、蓝色通道的样本像素值。因此,其均值将是3x1的向量,协方差矩阵将会是3x3的矩阵。
p ( x ) p(\mathbf{x}) p(x)是指某个样本像素(向量,为 x \mathbf{x} x)在假设我们知道了小球RGB模型的均值和方差的条件下从小球RGB模型(三维高斯模型)抽出的概率。

对于2D的情况,我们令 x = [ x y ] T \mathbf{x}=[x \ y]^{T} x=[x y]T、 μ = [ 0 0 ] T \mathbf{\mu}=[0 \ 0]^{T} μ=[0 0]T、KaTeX parse error: Expected & or \\ or \cr or \end at position 32: …atrix} 1 & 0 \\\̲ ̲0 & 1 \\ \end{…, 则如下所示,其中,当从上面往下看的时候,我们会发现其等高线上的概率是一样的。由于协方差是个对角矩阵且对角线上的值是一样的,所以等高线是一个圆。
最里面的圆代表着概率的峰值,外面的圆代表这概率较小的区域

以下列举几种当参数变化时高斯分布的变化情况:
- 均值发生变化:x维度均值变大,y维度均值变小
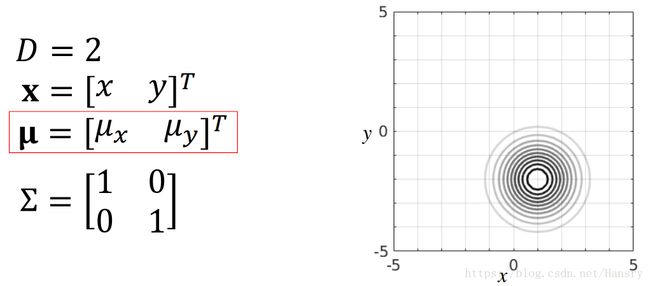
- 协方差矩阵中随机变量的独立方差的值发生变化: σ 2 \sigma^{2} σ2变大
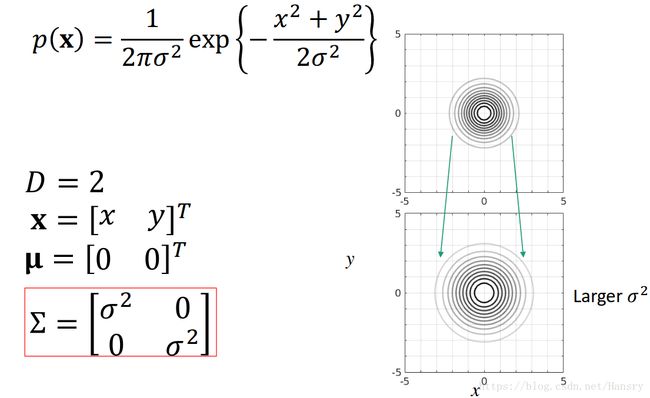
- 当协方差矩阵中非对角线上的值不同时,即俩个随机变量具有相关性(这时侯模型的有些性质在2D投影其实是看不到的)。其中分为 σ x σ y > 0 \sigma_{x}\sigma_{y}>0 σxσy>0 和 σ x σ y < 0 \sigma_{x}\sigma_{y}<0 σxσy<0。
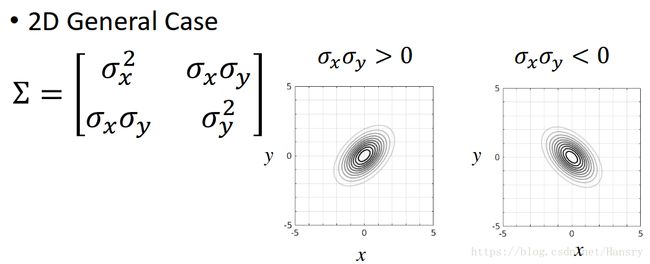
其中 ∑ \sum ∑有俩个特殊的性质:
1.协方差矩阵必须是特殊的正定对称矩阵,这意味着协方差矩阵的元素是关于对角线对称的,因此, ∑ \sum ∑的特征值(eigen value)必须为正的。
2.即使 ∑ \sum ∑矩阵有非0的相关项,我们总可以找到一种坐标变换让分布的形状变成对称的。我们可以使用特征值分解算法,来将协方差进行矩阵分解进而得到这些变换。 ∑ \sum ∑可以被分解成 U D U T UDU^{T} UDUT的形式,其中 D D D是对角矩阵。
4.多变量高斯分布下的最大似然估计(MLE of Multivariate Gausssian)
如何从观测数据计算和估计多维高斯模型的参数。
多维高斯模型拥有俩个参数: μ \mu μ 和 ∑ \sum ∑
Likelihood(似然): 是一个给定的参数未知的模型产生这个观测数据{ x i x_{i} xi}(请注意这里是 x i x_{i} xi的集合)的概率。
根据上面一维高斯函数的推导,同样的,我们可以利用其思想,最后得到 (详细推导):
μ ^ = 1 N ∑ i = 1 N x i \hat{\mathbf{\mu}}=\frac{1}{N} \ \sum_{i=1}^{N} \mathbf{x_{i}} μ^=N1 ∑i=1Nxi
∑ ^ = 1 N ∑ i = 1 N ( x i − μ ^ ) ( x i − μ ^ ) T \hat{\mathbf{\sum}}=\frac{1}{N}\sum_{i=1}^{N}(\mathbf{x_{i}-\hat{\mu}})(\mathbf{x_{i}-\hat{\mu}})^{T} ∑^=N1∑i=1N(xi−μ^)(xi−μ^)T
回到小球的例子,我们可以得到其更加具体的分布,如下图所示,红色和蓝色随机变量呈现的是负相关关系。
5. 高斯混合模型(Gaussians mixture model, GMM)
高斯混合模型的优点和缺点?
如何从数学上描述高斯混合模型?
在实际中,一个随机变量的分布不一定是只有一个峰值且对称的,这时候我们可以用多个高斯分布来代表这样一个随机变量的分布。若只用一个高斯分布来表示,则结果可能不会满意,如下图所示:
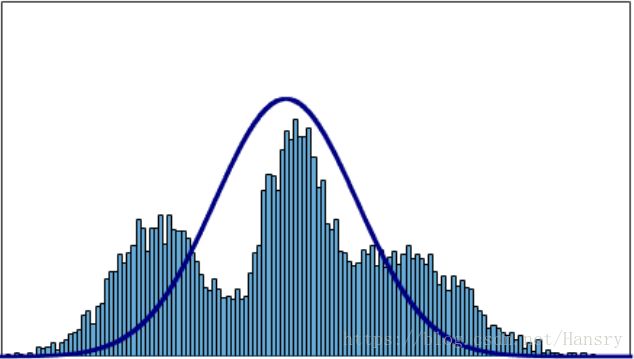
多个高斯分布相加得到一个新的分布:
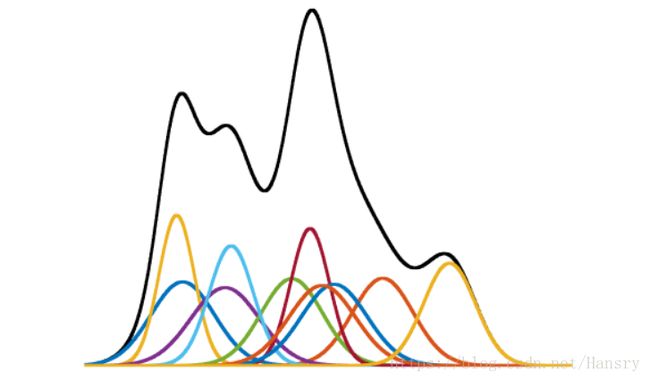
首先,我们令 g 代表一个有某均值和协方差的单纯高斯模型的密度函数,则混合高斯模型(GMM)可以被写成:
p ( x ) = ∑ k = 1 K w k g k ( x ∣ u k , ∑ k ) p(x)=\sum_{k=1}^{K}w_{k}g_{k}(x|u_{k},\sum_{k}) p(x)=∑k=1Kwkgk(x∣uk,∑k),
其中 g k ( x ∣ u k , ∑ k ) g_{k}(x|u_{k},\sum_{k}) gk(x∣uk,∑k)代表参数为 ( μ k , ∑ k ) (\mu_{k},\sum_{k}) (μk,∑k)的单纯高斯分布。
混合高斯模型由这些有不同参数的高斯模型的加权求和,其中 w k w_{k} wk都是正的,且他们的和为1,即 ∑ k = 1 K w k = 1 , w k > 0 。 \sum_{k=1}^{K}w_{k}=1, w_{k}>0。 ∑k=1Kwk=1,wk>0。
这保证了混合高斯模型的密度函数积分仍然为1,理论上可以用多个高斯分布表示任意形状的分布。
但是混合高斯模型也有以下的缺点:
- 参数变多:
μ = { μ 1 , μ 2 , . . . , μ k } \mathbf{\mu=\begin{Bmatrix}{\mu_{1},\mu_{2},...,\mu_{k}}\end{Bmatrix}} μ={μ1,μ2,...,μk}
∑ = { ∑ 1 , ∑ 2 , . . . , ∑ k } \mathbf{\sum=\begin{Bmatrix}{\sum_{1},\sum_{2},...,\sum_{k}}\end{Bmatrix}} ∑={∑1,∑2,...,∑k}
w \mathbf{w} w
K \mathbf{K} K - 参数没有解析解
- 过拟合
6. 利用期望最大化算法估计混合高斯模型参数(GMM Parameter Estimation via EM)
不同于纯高斯模型,对于混合高斯模型,我们很难求出令人满意的解析解(analytics solution)。相反,通过期望最大化迭代算法(Expectation Maximization)可以得到局部的优化解。
純高斯模型只有俩个参数, u u u 和 ∑ \sum ∑, 而混合高斯模型多个 μ \mu μ、 ∑ \sum ∑、 w w w 和 高斯模型的个数 K K K。
在接下来的计算中,我们令 w = 1 K w=\frac{1}{K} w=K1,这可以让我们把重心放在怎样估计均值和方差矩阵的参数。
简单回顾一下,最大似然估计(maximum likelihood estimation)意味着我们要寻找模型的参数来使得模型最可能产生观察到的数据。
对于最大似然估计,从前面可得:
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
μ ^ , Σ ^ = a r g m a x μ , Σ ∏ i = 1 N p ( x i ∣ μ , Σ ) = a r g m a x μ , Σ l n { ∏ i = 1 N p ( x i ∣ μ , Σ ) } = a r g m a x μ , Σ ∑ i = 1 N l n p ( x i ∣ μ , Σ ) \hat{\mu},\hat{\Sigma}\\= arg\ \underset{\mu,\Sigma}{max}\prod_{i=1}^{N} p(x_{i}| \mu,\Sigma )\\=arg\ \underset{\mu,\Sigma}{max} \ ln \begin{Bmatrix} \prod_{i=1}^{N} p(x_{i}| \mu,\Sigma )\end{Bmatrix} \\=arg\ \underset{\mu,\Sigma}{max}\sum_{i=1}^{N} \ ln \ p(x_{i}| \mu,\Sigma ) μ^,Σ^=arg μ,Σmax∏i=1Np(xi∣μ,Σ)=arg μ,Σmax ln{∏i=1Np(xi∣μ,Σ)}=arg μ,Σmax∑i=1N ln p(xi∣μ,Σ)
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
由于 p ( x ) = ∑ k = 1 K w k g k ( x ∣ u k , ∑ k ) p(x)=\sum_{k=1}^{K}w_{k}g_{k}(x|u_{k},\sum_{k}) p(x)=∑k=1Kwkgk(x∣uk,∑k)
故得到: μ ^ , Σ ^ = a r g m a x μ , Σ ∑ i = 1 N l n { 1 K ∑ k = 1 K g k ( x i ∣ u k , Σ k ) } \hat{\mu},\hat{\Sigma} =arg\ \underset{\mu,\Sigma}{max}\sum_{i=1}^{N} \ ln \begin{Bmatrix}{\frac{1}{K}\sum_{k=1}^{K}g_{k}(x_{i}|u_{k},\Sigma_{k})}\end{Bmatrix} μ^,Σ^=arg μ,Σmax∑i=1N ln{K1∑k=1Kgk(xi∣uk,Σk)} (不能再继续简化了,因为在log函数中对純高斯模型进行了求和,所以不能通过求导来求得最小值)。
在特定的条件下,我们可以通过EM算法来得到合理的结果,首先就求解高斯混合模型(GMM)参数,引入EM。
- 对 μ 、 Σ \mu、\Sigma μ、Σ进行初始化猜测。
- 新的变量 Z Z Z,我们称之为潜在变量(latent variable)
**首先我们需要先估计需要求解的参数。**对于这类非凸优化(non-convex optimization)的复杂问题,有许多的次优解(suboptimal solutions),我们称之为局部最小值(local minimum)。同时,初始化的值将会影响到最后的结果,因此初始值对该问题而言是十分重要的。
接着我们讨论潜在变量 Z Z Z。潜在变量Z为关于第K个高斯模型的第 i i i个数据点的潜在变量,定义为第k个高斯模型在该数据点处的相对比。本质上, Z Z Z表明了第i个点是由第k个高斯模型产生的概率。 表达如下:
z k i = g k ( x i ∣ u k , Σ k ) ∑ k = 1 K g k ( x i ∣ u k , Σ k g ) z_{k}^{i}=\frac{g_{k}(x_{i}|u_{k},\Sigma_{k})}{\sum_{k=1}^{K}g_{k}(x_{i}|u_{k},\Sigma_{k}g)} zki=∑k=1Kgk(xi∣uk,Σkg)gk(xi∣uk,Σk)
让我们来探讨下在1维情况下的例子,其中K=2。在一维情况下,我们有一系列点,其中有俩个高斯模型g1和g2,且g1在 x i x_{i} xi处的概率为 p 1 p_{1} p1, g2在 x i x_{i} xi处的概率为 p 2 p_{2} p2, 则我们可以计算 z 1 i z_{1}^{i} z1i和 z 2 i z_{2}^{i} z2i, 分别代表在第i点中,属于g1和g2模型的概率。
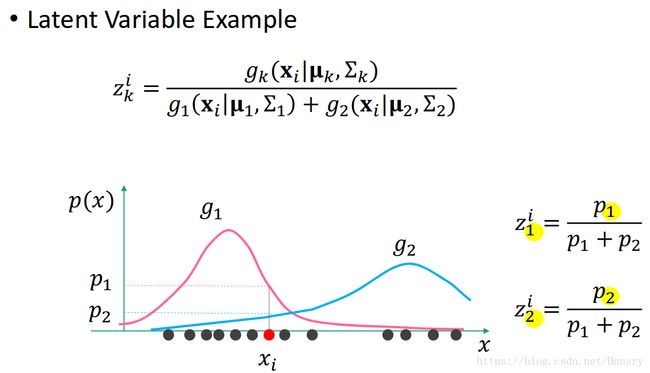
现在,给定所有数据点关于所有模型的潜在变量,我们可以重新定义带权的均值和协方差矩阵,该权重指的是Z。如果一个数据点属于第k个高斯模型的概率很小,则这个点对计算第k个模型的参数的贡献就越小。
=============================================================
u ^ k = 1 z k ∑ i = 1 N z k i x i \hat{\mathbf{u}}_{k}=\frac{1}{z_{k}}\sum_{i=1}^{N}z_{k}^{i}\mathbf{x}_{i} u^k=zk1∑i=1Nzkixi
Σ ^ k = 1 z k ∑ i = 1 N z k i ( x i − u k ^ ) ( x i − u ^ k ) T \hat{\mathbf{\Sigma}}_{k}=\frac{1}{z_{k}}\sum_{i=1}^{N}z_{k}^{i}\mathbf{(x_{i}-\hat{u_{k}})(x_{i}-\hat{u}_{k})}^{T} Σ^k=zk1∑i=1Nzki(xi−uk^)(xi−u^k)T
z k = ∑ i = 1 N z k i z_{k}=\sum_{i=1}^{N} z_{k}^{i} zk=∑i=1Nzki (这三条公式说明怎么通过潜在变量Z来更新 μ \mu μ 和 Σ \Sigma Σ)
综合之前讨论的东西,我们可以迭代的计算参数和潜在变量,直到其值收敛为止。以下是计算的步骤:
1.初始化参数 μ 、 Σ \mu、\Sigma μ、Σ。
2. 使用初始化的参数 μ 、 Σ \mu、\Sigma μ、Σ来计算潜在变量Z。
3. 一旦Z被更新,我们就保持Z不变用来更新 μ Σ \mu \ \Sigma μ Σ。
4. 重复2.3步,直到参数的改变量变得很小为止。
7. 期望最大化(Expectation Maximization)
需要有一定的概率和凸优化基础。
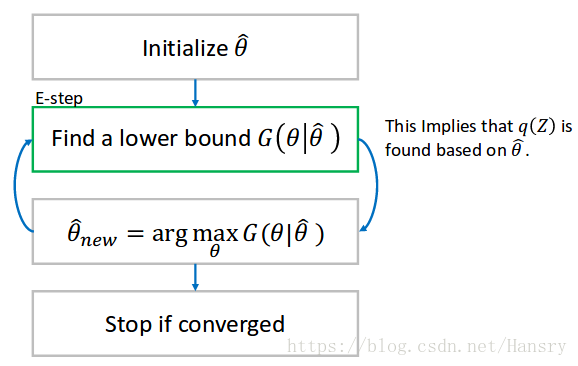
让我们把EM算法看作是对目标函数下界的最大化过程。
EM算法的主要思想可以用 Jensen 不等式解释,考虑一个如下图的2维图所示的凸函数,我们在定义域中取俩点 x 1 x_{1} x1和 x 2 x_{2} x2以及他们的中点 x 1 + x 2 2 \frac{x_{1}+x_{2}}{2} 2x1+x2。
现在我们将比较俩个值,首先是中点的函数值 f ( x 1 + x 2 2 ) f(\frac{x_{1}+x_{2}}{2}) f(2x1+x2), 是曲线上的一个点,第二个是俩点函数值的平均值 f ( x 1 ) + f ( x 2 ) 2 \frac{f(x_{1})+f(x_{2})}{2} 2f(x1)+f(x2), 落在 f x 1 fx_{1} fx1 和 f x 2 fx_{2} fx2 俩个点的连线上。
可以清楚的看到,直线在函数曲线的上方,因此 f ( x 1 ) + f ( x 2 ) 2 \frac{f(x_{1})+f(x_{2})}{2} 2f(x1)+f(x2) 永远大于 f ( x 1 + x 2 2 ) f(\frac{x_{1}+x_{2}}{2}) f(2x1+x2)。

我们可以一般化这个想法, f ( a 1 x 1 + a 2 x 2 ) ⩽ a 1 f ( x 1 ) + a 2 f ( x 2 ) f(a_{1}x_{1}+a_{2}x_{2}) \leqslant a_{1}f(x_{1})+a_{2}f(x_{2}) f(a1x1+a2x2)⩽a1f(x1)+a2f(x2), 这个不等式在任意大于0的权值下都成立。其中 a 1 + a 2 = 1 , a 1 ⩾ 0 , a 2 ⩾ 0 a_{1}+a_{2}=1, a_{1}\geqslant0, a_{2}\geqslant0 a1+a2=1,a1⩾0,a2⩾0。
事实上,它同样适用于正权值下多个点的情况,可得 f ( ∑ a i x i ) ⩽ ∑ a i f ( x i ) f(\sum a_{i}x_{i}) \leqslant \sum a_{i}f(x_{i}) f(∑aixi)⩽∑aif(xi), 其中 ∑ a i = 1 , a i ⩾ 0 \sum a_{i}=1, a_{i} \geqslant 0 ∑ai=1,ai⩾0。
甚至在多维的情况下,只要我们的函数是凸的。如果函数是凹的,我们只需要翻转这个函数,即 f ( ∑ a i x i ) ⩾ ∑ a i f ( x i ) f(\sum a_{i}x_{i}) \geqslant \sum a_{i}f(x_{i}) f(∑aixi)⩾∑aif(xi)。
由于我们接下来要处理的是对数函数,且它是凹函数,故有
( 1 ) l n ( ∑ a i x i ) ⩾ ∑ a i l n x i (1) \ ln(\sum a_{i}x_{i}) \geqslant \sum a_{i}ln \ x_{i} (1) ln(∑aixi)⩾∑ailn xi。
现在我们引入我们永远都无法确切知道的潜在变量(latent variable),潜在变量在一些特定的应用中是清楚的,例如前面提到的混合高斯模型的参数估计。我们需要在所有变量上取潜在变量的边缘概率(What we are going to do with this latent variable is to take the marginal probability over the variable)。
( 2 ) p ( X ∣ θ ) = ∑ Z p ( X , Z ∣ θ ) (2) p(X|\theta) = \sum_{Z} p(X,Z|\theta) (2)p(X∣θ)=∑Zp(X,Z∣θ)
在之前,我们考虑概率的对数:
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
l n p ( X ∣ θ ) = l n ∑ Z p ( X , Z ∣ θ ) ( 对 数 形 式 的 似 然 , l o g − l i k e l i h o o d ) = l n ∑ Z q ( Z ) p ( X , Z ∣ θ ) q ( Z ) ( q ( Z ) 是 Z 有 效 的 概 率 分 布 ) ⩾ ∑ Z q ( Z ) l n p ( X , Z ∣ θ ) q ( Z ) ( 下 界 , l o w e r b o u n d ) ln \ p(X|\theta) \\= ln \ \sum_{Z} p(X,Z|\theta)\ (对数形式的似然, log-likelihood) \\=ln \ \sum_{Z} q(Z) \frac{p(X,Z|\theta)}{q(Z)}(q(Z)是Z有效的概率分布) \\ \geqslant \ \sum_{Z} q(Z) \ ln \ \frac{p(X,Z|\theta)}{q(Z)} (下界, lower bound) ln p(X∣θ)=ln ∑Zp(X,Z∣θ) (对数形式的似然,log−likelihood)=ln ∑Zq(Z)q(Z)p(X,Z∣θ)(q(Z)是Z有效的概率分布)⩾ ∑Zq(Z) ln q(Z)p(X,Z∣θ)(下界,lowerbound)
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
正如我们无法直接最大化概率和的对数,但是我们可以利用函数的下界,对于它我们是可以计算的。获得下界意味着找到了潜在变量(latent variable) Z的一个分布 q ( Z ) q(Z) q(Z)。
假设我们有一个初始猜测的参数 θ 0 \theta_{0} θ0,并且我们通过利用猜测的参数 θ 0 \theta_{0} θ0得到了 q q q, 进而得到了下界 g g g。
$3(a) \ ln \ p(X|\theta) \geqslant \ \sum_{Z} q(Z) \ ln \ \frac{p(X,Z|\theta)}{q(Z)} $
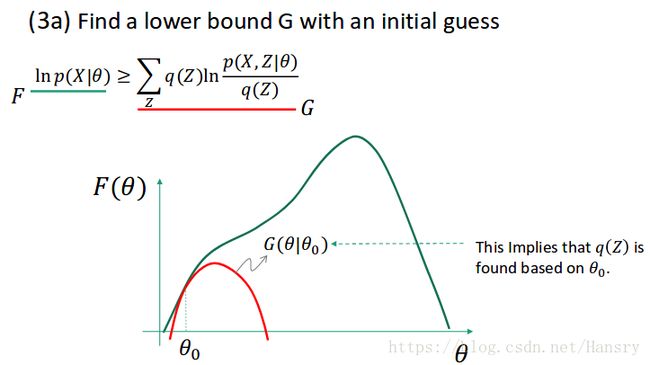
正如前面提到的,对数形式的概率可以被看做是参数的函数。假设f 和 g 是如图所示的 θ \theta θ 的函数,f 和 g并不一样,但是它们在 θ 0 \theta_{0} θ0 附件有一些局部的相似性。别忘记我们是要求一个参数的最大似然估计,给定下界G,我们可以找到一个更好的参数 θ ∗ \theta^{*} θ∗, 这仍然不是F的最大值,但是它比之前的估计更优。

由于找到了 θ ∗ \theta^{*} θ∗,我们可以更新 θ \theta θ 的值,再重新找到新的下界,通过下界,通过求出下界的最大值是后的参数 θ \theta θ 进而又再次求出 θ ∗ \theta^{*} θ∗。

不断更新,最后收敛为止:
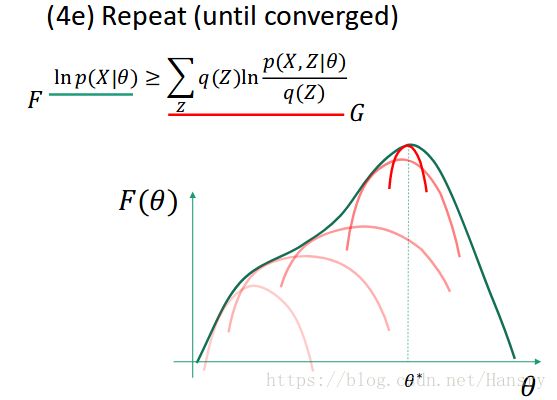
所以,EM 算法是一个相当强大的算法,其算法流程如下所示: