极简笔记 Deformable Convolutional Networks
极简笔记 Deformable Convolutional Networks
论文地址:https://arxiv.org/abs/1703.06211
文章核心是提出deformable convolution和deformable roi pooling两种结构模块,使得卷积能够自由形变,打破了方形卷积的形状约束,增强了卷积对于物体几何形变的适应性。
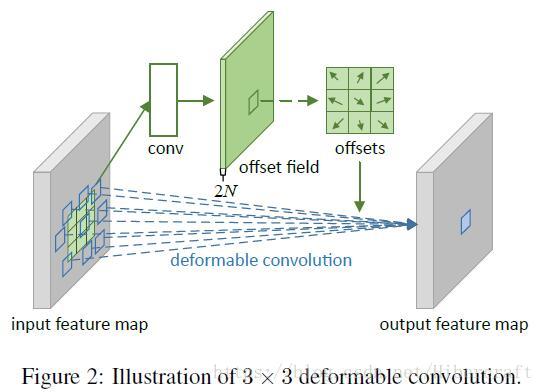
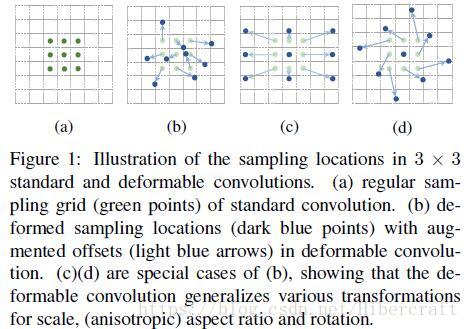
先讲deformable convolution,如上图,就是卷积层多出一个分支预测原始卷积核中各个bin对应的卷积位置的offset。这个offset经常是个小数,所以卷积位置的实际取值在是feature map周围像素点的线性插值。用公式表示就是,对于任意位置 p0 p 0 ,它的卷积结果就是:
其中 pn p n 属于卷积核内的相对坐标集合 R={(−1,−1),(−1,0),...,(1,0),(1,1)} R = { ( − 1 , − 1 ) , ( − 1 , 0 ) , . . . , ( 1 , 0 ) , ( 1 , 1 ) } , △pn △ p n 就是fc层预测的offset。因为要考虑插值,所以函数 x(p) x ( p ) 表示 p p 位置的差值结果( p p 可以是小数)
这个地方 q q 表示用于插值产生 p p 的邻近的一堆点(就是正常的线性插值,对 p p 周边一些点根据x,y轴距离乘相应的权重)。在反向传播的时候,对offset的求导会涉及这个bin周围的四个像素点的像素值,麻烦一点但是也能算,从 ∂y(p0)∂△p0x ∂ y ( p 0 ) ∂ △ p 0 x 和 ∂y(p0)∂△p0y ∂ y ( p 0 ) ∂ △ p 0 y 一步步推过来就好。
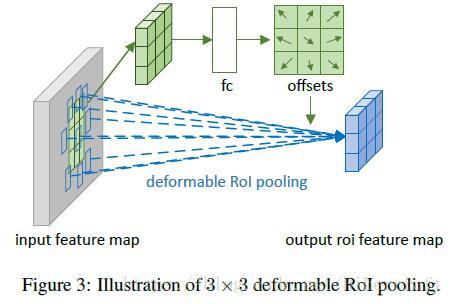
接下来讲deformable roi pooling,如上图,还是一样的操作,把一个尺寸为 w×h w × h 的图pooling成 k×k k × k 。对于pooling核中第 (i,j) ( i , j ) 的输出bin (0≤i,j<k) ( 0 ≤ i , j < k ) :
其中第 (i,j) ( i , j ) bin的跨度为 ⌊iwk⌋≤px<⌈(i+1)wk⌉ ⌊ i w k ⌋ ≤ p x < ⌈ ( i + 1 ) w k ⌉ , ⌊jwk⌋≤py<⌈(j+1)wk⌉ ⌊ j w k ⌋ ≤ p y < ⌈ ( j + 1 ) w k ⌉ , nij n i j 表示这个跨度里面有多少个像素点。函数 x(∙) x ( ∙ ) 和之前一样,注意这里 △pij=γ△p^ij∘(w,h) △ p i j = γ △ p ^ i j ∘ ( w , h ) ,fc层预测的是归一化的 △p^ij △ p ^ i j ,需要对应乘宽高, γ γ 是predefined约束来调整offset的量级,文章取值为 γ=0.1 γ = 0.1
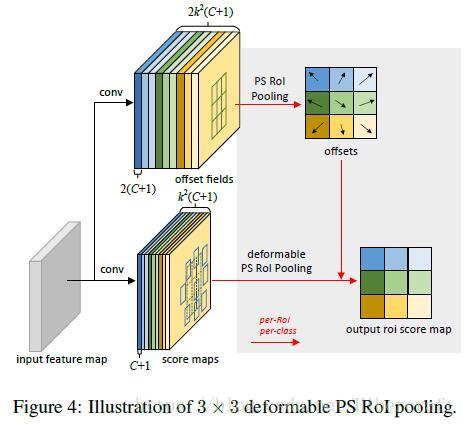
没完,文章接着提了更强的Position-Sensitive (PS) RoI Pooling,如上图,把分类信息也加在pooling层里面了,上图 C C 表示类别数(+1是背景), k k 就是pooling的尺寸,等于说每一个 (i,j) ( i , j ) 对应 C+1 C + 1 类channel,然后deformable roi pooling(密集恐惧症要犯了。。。)
在实验时候,文章将backbone network最后几层改成了deformable conv + deformable pooling的形式,这些新加offset部分初始为0,学习率设为对应层的学习率乘上系数 β β ( β=1 β = 1 为默认取值,fc层的 β=0.01 β = 0.01 )
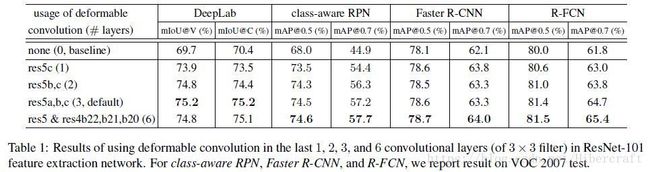
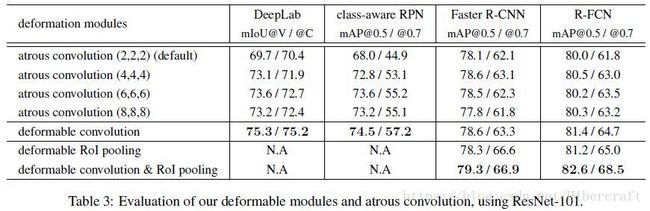
文章后面的实验以及对比都是在为了说明deformable conv/pooling是一种更加general的卷积形式,常用于增加感受野的atrous conv就是它的一种特例。在对比试验中,不同网络和任务对应的最优atrous conv选择不同,但是使用deformable conv之后都是效果最好的。作者还对比了增加deformable部分后网络的参数量和计算量,都只增加了一点点却有明显的性能提升,说明deformable模块是有效的而不是依靠增加模型复杂度来提高性能的。

最后让我们try to understand deformable module,如上图,deformable conv/pooling收敛后的采样点更加与物体位置相关,offset在训练时会偏向于对象强响应的位置,能够更高效地利用对象特征而不是背景特征,在分类、分割、检测上都会有帮助。
个人感觉分类、检测的任务用deformable做有点杀鸡用牛刀,deformable module应该能够处理更加复杂的任务。总之这是一篇非常solid研究,期待后续进展。