斯坦福大学自然语言处理第七课“情感分析(Sentiment Analysis)”
课程地址:https://class.coursera.org/nlp/lecture/31
1. What is Sentiment Analysis?
情感分析(Sentiment analysis)又可以叫做
意见抽取(Opinion extraction)
意见挖掘(Opinion mining)
情感挖掘(Sentiment mining)
主观分析(Subjectivity analysis)等等。
比如对电影好坏的评价:

比如Google Product Search 上面对产品属性的评价,并展示褒贬程度:

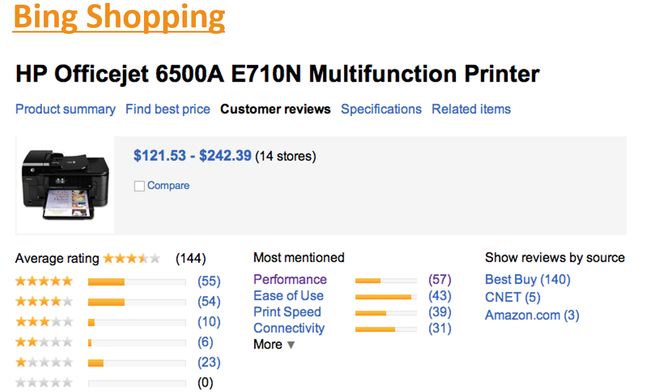
还比如Bing Shopping对上面同一台打印机的评价结果:
Twitter sentiment versus Gallup Poll of Consumer Confidence
通过Tewitter上和民意调查得来的数据的进行对比,发现两者对于消费者信心的统计结果有很大的相关性(correlation),相关度达到80%。

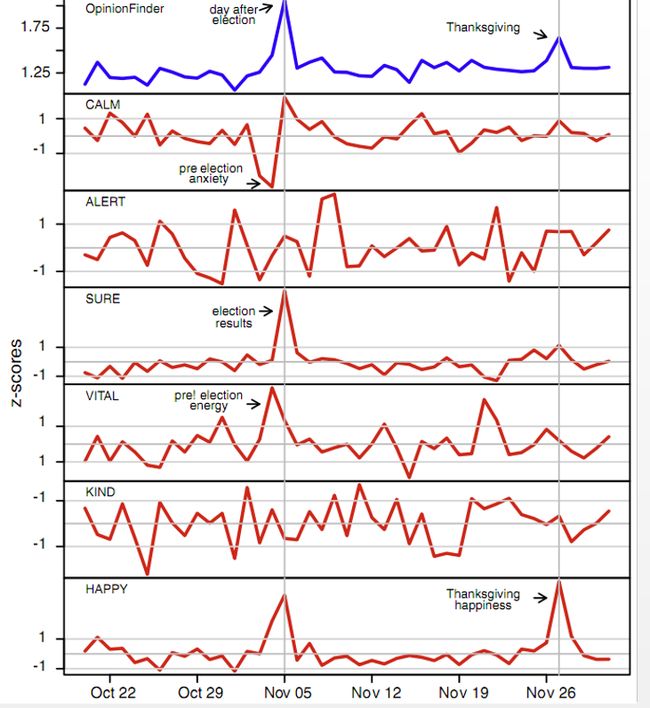
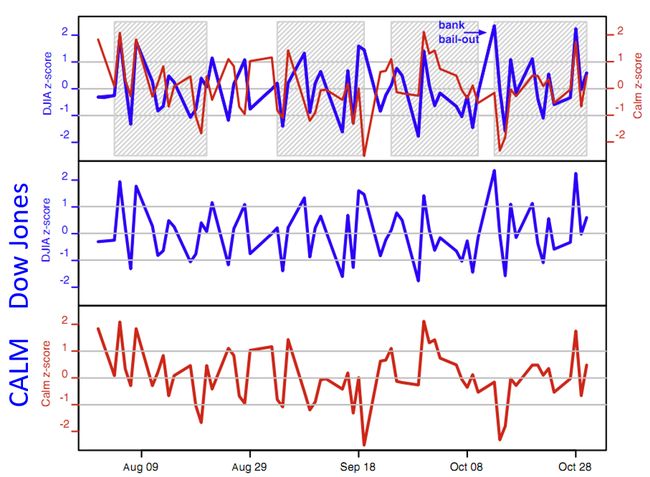
同样,利用Twitter上的公众情绪预测股票,发现:CLAM(平静)情绪的指数可以预测三天后道琼斯的指数。
Target Sentiment on Twitter(Twitter Sentiment App):用户可以输入产品关键字来查询其他网友对此产品的评价

Why sentiment analysis?
- Movie: is this review positive or negative?
- Products: what do people think about the new iPhone?
- Public sentiment: how is consumer confidence? Is despair increasing?
- Politics: what do people think about this candidate or issue?
- Prediction: predict election outcomes or market trends from sentiment
电影产品预测,民意政治倾向等等…
Sentiment analysis is the detection of attitudes
分析用户对人或物品的态度(attitudes:enduring, affectively colored beliefs, dispositions towards objects or persons)
分析主体包括:
- Holder (source) of attitude :谁有这个属性
- Target (aspect) of attitude :评价的对象
- Type of attitude :有哪些方面
- From a set of types
Like, love, hate, value, desire, etc. - Or (more commonly) simple weighted polarity:
positive, negative, neutral, together with strength
- From a set of types
- Text containing the attitude :文本是单句还是整句
Sentence or entire document
由简单到复杂的情感分析:
- Simplest task:
- Is the attitude of this text positive or negative? 简单的极性
- More complex:
- Rank the attitude of this text from 1 to 5 评分等级
- Advanced:
- Detect the target, source, or complex attitude types 对象,来源及复杂的态度等。
2. Sentiment Analysis: A baseline algorithm基准算法
本节讲解对电影评论进行情感分类(sentiment classification)的一个实例
引用的论文:
Bo Pang, Lillian Lee, and Shivakumar Vaithyanathan. 2002. Thumbs up? Sentiment Classification using Machine Learning Techniques. EMNLP-2002, 79—86.
Bo Pang and Lillian Lee. 2004. A Sentimental Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts. ACL, 271-278
任务的目的:极性判断(Polarity detection):
Is an IMDB movie review positive or negative?
并且可在此网站http://www.cs.cornell.edu/people/pabo/movie-review-data下载实验数据
下面是截取的一小段数据,我们看到可以通过里面的一些关键词来判断这段影评的极性:

基准算法(Baseline Algorithm)的几个步骤
1 . Tokenization标记:
- Deal with HTML and XML markup 文本解析
- Twitter mark-up (names, hash tags)处理哈希tags
- Capitalization (preserve for words in all caps)保留大写字母前的标点
- Phone numbers, dates 过滤时间
- Emoticons 表情符号很重要
2 . Feature Extraction 特征提取
通常我们会利用否定句(negation)来做处理,并且通常来说整个文本作为特征,效果会比单纯的形容词好。

但是在处理否定句的时候,像上面的两个句子虽然有很明显的极性差别,但是却只有一个词的差别,为了更好的处理这种情况,我们一般在否定词到标点之间的每一个之间都加NOT_

3 . Classification using different classifiers 用不同的分类器进行分类
- Naïve Bayes 朴素贝叶斯
- MaxEnt 最大熵模型
- SVM 支持向量机
详述一下朴素贝叶斯:
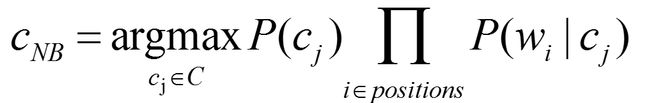
上式可以得出最有可能的分类等于最大化先验概率和似然概率的乘积
先验概率就是出现该词的文档占全部文档的概率
似然函数可以想象成所有文本中这个单词出现在每个当前文档中的频率和
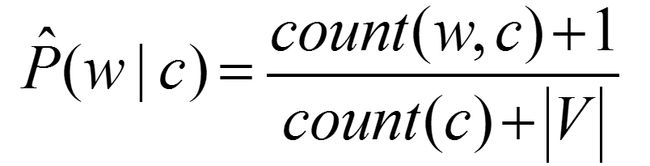
我们加入拉普拉斯平滑来处理零概率的问题,因为当在文本处理时,一个词在训练集中没有出现过,那么他的概率为零,在连乘的过程中导致整个文本出现的概率也是零,这是不合理的。没出现不代表没可能。
Binarized (Boolean feature) Multinomial Naïve Bayes
在进行特征提取时,我们更关心的是句子中极性词是否出现,而不是出现的次数,所以我们引入了二值多项式贝叶斯(不知道翻译的对不对 : ))来进行分类

所以我们在执行算法的过程中,只需要将每个text文本中重复的词去掉,只取一个单词实例就足够了,剩下的计算还和上面的贝叶斯相同。
另外需注意,Binarized (Boolean feature) Multinomial Naïve Bayes不同于Multivariate Bernoulli Naïve Bayes,MBNB在文本情感分析上的效果并不好。另外课中也提到可以用交叉验证的方式进行训练验证。
What makes reviews hard to classify?
情感分析的难点:
- 例如表达含蓄,语义微妙的句子使人很难理解

- 或者是先扬后抑的风格(Thwarted Expectations)以及句子顺序的影响,也是增加了分析难度。

3.Sentiment Lexicons 情感词典
在实际情感分析的过程中,通常依赖情感词典来提取特征,情感词典中包含了词的多种极性。
下面罗列了一些比较流行的词典:
The General Inquirer http://www.wjh.harvard.edu/~inquirer/homecat.htm
LIWC (Linguistic Inquiry and Word Count) http://www.liwc.net/ 分类较多,褒贬,猜疑。

MPQA Subjectivity Cues Lexicon http://www.cs.pitt.edu/mpqa/subj_lexicon.html

Bing Liu Opinion Lexicon http://www.cs.uic.edu/~liub/FBS/opinion-lexicon-English.rar
SentiWordNet http://sentiwordnet.isti.cnr.it/ 标注了极性的可能性

下面是不同词典之间的差别,可以看出SentiWordNet和其他的词典还是有些出入,我们可以根据此来关注词语歧义的问题。
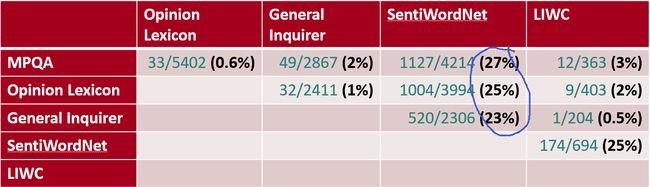
Analyzing the polarity of each word in IMDB
当我们拿到一个词我们如何判断他在每个类别中出现的概率呢?以IMDB影评为例
Potts, Christopher. 2011. On the negativity of negation. SALT 20, 636-659. 论文中写到通过给词语打分的形式来对应频率,比如给单词(“bad”) 打分 1-star, 2-star, 3-star…
但是!我们不能用单纯的原始计数(raw counts)方法来进行打分,如下图
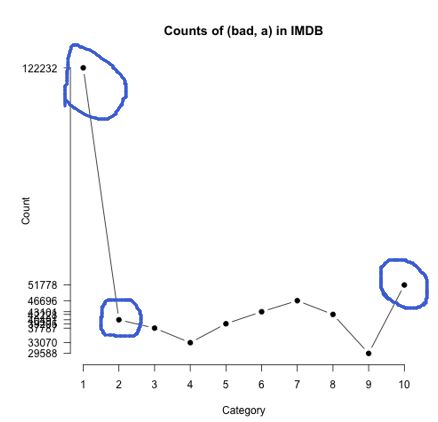
bad显然是一个消极词,但是10星的频率却出现的比2星的还多,这会产生很大的干扰,所以我们不能采用之中原始计数的方法,而是似然函数
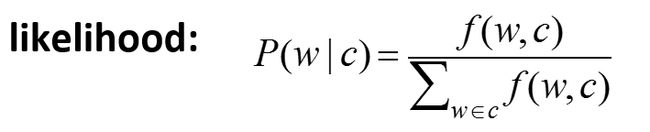
同时,有的单词会出现多次,有的会出现少次,为了方便比较,我们引入了尺度似然(scale likehood)

所以我们可以通过计算scale likehood来对单词进行打分,判断单词的极性:
那么像no,not,never这些否定词是否会跟消极词有关呢?Potts 在实验中利用上面的方法得到了下图:

可以看出,这些否定词同样可以作为单词极性的一个判断依据。
4. Learning Sentiment Lexicons
很多情况下,有时我们需要一些专业领域的或者已有词典库不具备的情感词典,这时我们就需要构建我们自己的情感词典。
通常我们采用的方法为半监督的bootstrap方法
具体步骤为:
- Use a small amount of information
- A few labeled examples
- A few hand-built patterns
- To bootstrap a lexicon
即使用少部分已经标注好的实例来半监督的不断填充整个词典
下面通过两篇论文来学习如何构建我们自己的情感词典:
Vasileios Hatzivassiloglou and Kathleen R. McKeown. 1997. Predicting the Semantic Orientation of Adjectives. ACL, 174–181
第一篇是Hatzivassiloglou和McKeown的文章,思想很好理解:连接词为“and”的两个词极性相同,反之,连接词为“but”的两个词极性相反。

这种bootstrap的方法共有四步:
Step1:
选取1336个形容词的种子集,其中包含肯定的和否定的词

Step2:
利用种子集进行扩充, 填充与此形容词相关联的情感词,比如我们可以利用google搜索,只要有一定出现频率的相关词,我们都可以收录下来。
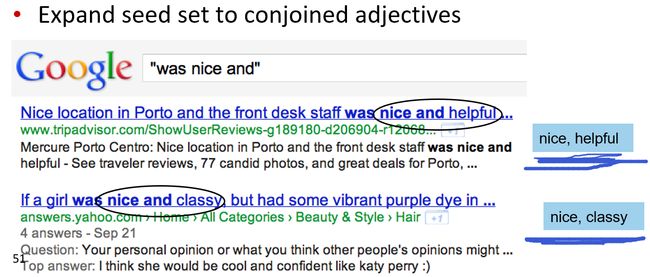
Step3:
接下来我们可以计算两个词的相似性,可以通过计算两个词之间出现and和but频率,出现and多就相近,出现but多就不相关。而后我们可以利用任何分类方法将词语集分类。
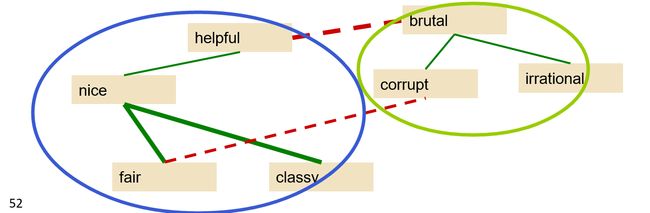
#### Step4:
最终输出,形成我们的情感词典(但是也会存在一些错误)

第二篇论文:Turney Algorithm
Turney (2002): Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews
上一篇论文很好的算出的单个词的极性,但是我们更想得到的是短语和单词同时存在的情感词典。就用到了Turney 算法,另一种半监督的bootstrap算法。
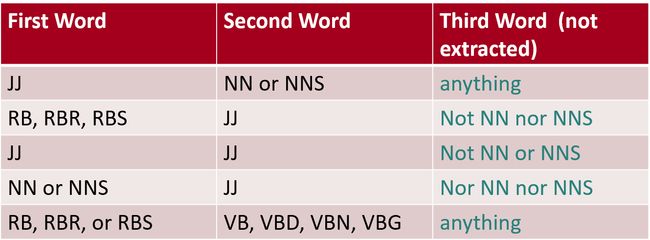
Step1:Extract a phrasal lexicon from reviews 提取关键短语
我们通过一些规则提取出文中的短语,比如第一行的 形容词 + 名词/复数名词 + 任何单词 提取出 两词的短语
Step2:Learn polarity of each phrase 计算词条的极性
和上面的算法类似,我们只需要计算短语的共现关系(co-occurence),
比如积极的词我们会发现通常和excellent一起出现
Positive phrases co-occur more with “excellent”
消极的会和poor等一起出现。但是怎么计算
Negative phrases co-occur more with “poor”
所以我们该如何计算他们之间的共现程度呢?
于是引入点互信息(Pointwise Mutual Information)这个概念
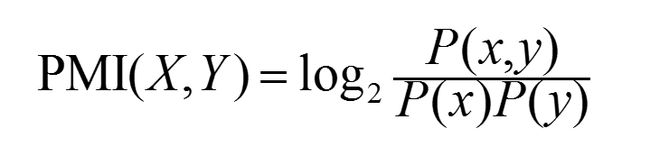
联合概率 / 独立的两个概率乘积
转化为两个词之间就是:

分母分子概率的计算公式
p(word) = (word)出现次数 / N
p(word) = (word1 NEAR word2)出现的次数 / N
所以PMI也可以写成:
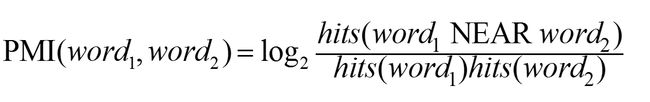
有了PMI我们就可以计算短语之间的极性(并不局限于excellent,poor)了,容易得到极性公式:

之后我们可以看一下统计结果,分别来自于用户好评和差评的统计:
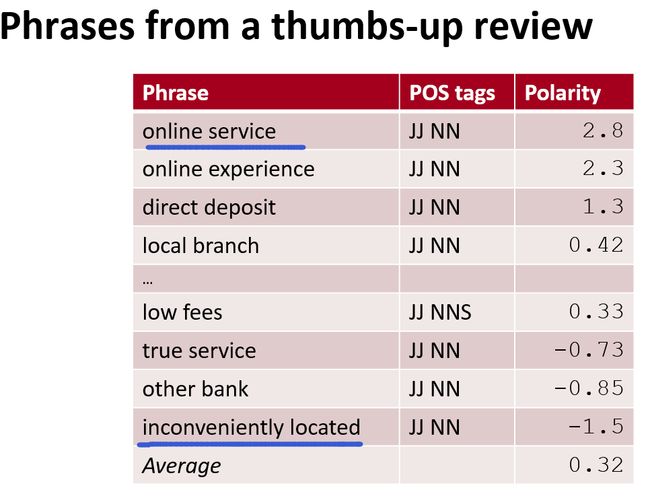
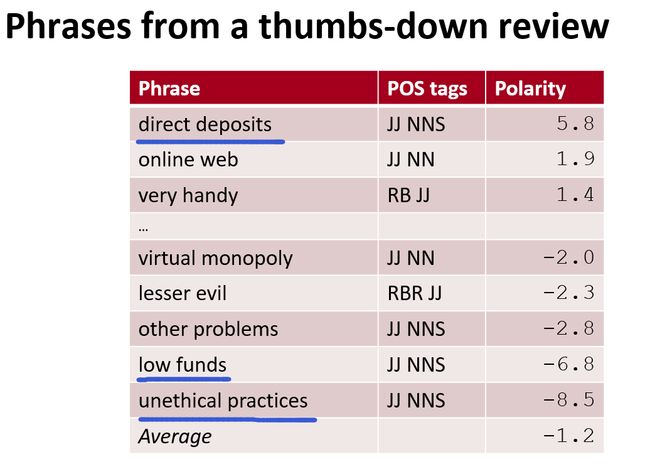
可以看到极性划分的还不错
Turney 算法的结果:
一共410个评论。170(41%)negative,240(59%)postive。
算法的准确率达到了74%
Step3:Rate a review by the average polarity of its phrases 最后一步:用平均极性值来估计评论的情感倾向。
还有一种方法就是实用WordNet:
简单来讲就是把上面的找共现词换成在积极的或者消极的感情词集后面加入同义词和反义词,不断重复,最后过滤掉不良的例子,得出情感词的极性。
论文:S.M. Kim and E. Hovy. 2004. Determining the sentiment of opinions. COLING 2004
M. Hu and B. Liu. Mining and summarizing customer reviews. In Proceedings of KDD, 2004

总结词典学习算法:
优点:
- 适用特定领域
- 具有不错的鲁棒性
思想:
- 以一个词条集开始(‘good’‘poor’)
- 寻找其他具有相似极性的词
- 使用 “and”,“but”
- 使用临近词
- 使用WordNet的同义词和反义词
5.Other Sentiment Tasks 其他的任务
在情感分析中,找到情感词的属性,对象尤为重要。我们通常采用的一是频率词+规则来提取属性,图中的就利用great来提取出情感的对象。二是通过已有属性来来判断对象是什么,比如菜单,装修,实物判断出餐厅。


还有就是S.Blair-Goldensohn提出的一种通用的对象训练器
论文:S. Blair-Goldensohn, K. Hannan, R. McDonald, T. Neylon, G. Reis, and J. Reynar. 2008. Building a Sentiment Summarizer for Local Service Reviews. WWW Workshop
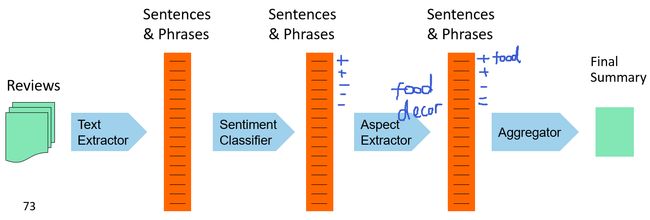

我们需注意的是通常我们是假设每个分类都是等概率的:
- 如果他们不相等
- 就不能用准确性来估计
- 需要引入F-scores来解决
- 严重的不平衡会影响分类器的表现
- 通常的两个解决方案:
- 训练集重采样
- 随机降采样(Random undersampling)
- Cost-sensitive learning算法
其他与情感分析类似的工作:情绪,性格等等

总结
1. 情感分析通常就是转换为分类问题
2.特点:
- 否定词很重要
- 使用全部词汇做分类
- 情感词典非常重要
- 已建好的词典
- 自己利用半监督的bootstrap方法构建