马氏距离(Mahalanobis distance)
转自:https://www.cnblogs.com/DPL-Doreen/p/8183909.html
转自:http://www.cnblogs.com/likai198981/p/3167928.html
转自:http://blog.csdn.net/luoleicn/article/details/6324266
以维基百科作为引用:
马氏距离是由印度统计学家马哈拉诺比斯(P. C. Mahalanobis)提出的,表示数据的协方差距离。它是一种有效的计算两个未知样本集的相似度的方法。与欧氏距离不同的是它考虑到各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的)并且是尺度无关的(scale-invariant),即独立于测量尺度。 对于一个均值为![]() ,协方差矩阵为Σ的多变量矢量
,协方差矩阵为Σ的多变量矢量![]() ,其马氏距离为
,其马氏距离为
![]()
马氏距离也可以定义为两个服从同一分布并且其协方差矩阵为Σ的随机变量![]() 与
与![]() 的差异程度:
的差异程度:
![]()
如果协方差矩阵为单位矩阵,马氏距离就简化为欧式距离;如果协方差矩阵为对角阵,其也可称为正规化的马氏距离。

其中σi是xi的标准差。
对于上述的马氏距离,本人研究了一下,虽然看上去公式很简单的,但是其中存在很多模糊的东西,为什么马氏距离是一种考滤到各种特性之间的联系并且是尺度无关的?为什么可以使用协方差矩阵的逆矩阵去掉单位而使之尺度无关。基于此,以下是个人的一些想法。
1、为什么要使变量去掉单位而使尺度无关
基于欧氏距离,两个点之间的长度为:
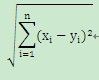
每个变量之间的变量之间的尺度都不一样,例如第一个变量的数量级是1000,而第二个变量的数量级是10,如v1=(3000,20),v2 = (5000,50),那么如果只有2维的点中,欧氏距离为:
![]()
由上面可以很容易看出,当两个变量都变成数量级为10的时候,第一个变量存在一个权重:10,因而如果不使用相同尺度的时候,不同尺度的变量就会在计算的过程中自动地生成相应的权重。因而,如果两个变量在现实中的权重是相同的话,就必须要先化成相同的尺度,以减去由尺度造成的误差,这就是标准化的由来。
如果化成相同尺度的方法就变成标准化方法了,标准化的方法有很多种,有些办法是使数据化成[0,1]之间,如min-max标准化,有些通过原始数据减去平均值再除标准差的方法,如z-score标准化,有些类似如上面的方法那样,化成相同的数量级的方法,如decimal scaling小数定标标准化。
2、为什么马氏距离是与尺度无关的?
根据上面1所描述,当计算两点的相似度(也可以说是距离的时候),第一步是首先标准化,化成与尺度无关的量,再计算它的距离。但是如果是单纯使每个变量先标准化,然后再计算距离,可能会出现某种错误,原因是可能在有些多维空间中,某个两个维之间可能是线性相关的,如下图所示(引用自:http://xgli0910.blog.163.com/blog/static/46962168201021932741868/):

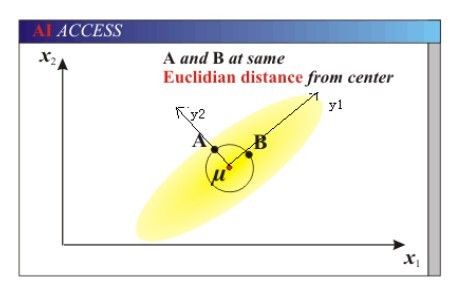
黄色部分为样品点,可以知道x1与x2是线性相关的,根据正态分布,对于中心点u,与A与B的标准距离应该是相同的,而马氏距离能做到这一点,但欧氏距离做不到,如下图所示:

由上图看到,如果使用欧氏距离,A点与B点距离中心点相同,但是又可以看出,A点处于样品集的边缘了,再外出一点就成异常点了。因此我们使用欧氏距离计算的时候,不能有效地区分出异常数据,看不出两变量之间的相似性与差异性,而上图中,A与B对于全体样品来说,差异性是够大的了。
为了解决这个问题,我们可以通过旋转坐标轴的方法,如下图所示:
可以看到y1与y2是线性无关的,因此我们可以通过对线性无关的分量进行标准化后,再求得距离是合理的。其实通过旋转坐标轴的方式,相当于对x进行相应的线性变换:Y = PX,使Y里面的各分变量变成线性无关的。设是随机向量X=[x1,x2,...xp]的协方差矩阵,它有特征值-特征向量对(λ1,e1), (λ2,e2),.....(λp,ep),其中λ1>=λ2>=....>=λp,则第i主成分由
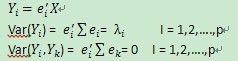
因此得到的新的变量Y里面的各分量是线性无关的,此时对于离中心点距离为某常数C形成的曲面是超椭球面。而yi的方差为λi,因而需要再把yi标准化,使之变成yi/λi,形成新的yi,这样生成的yi之间变成了与尺度无关的变量了,公式如下:

其中P是以特征向量为行向量的矩阵,根据正定距阵,特征向量互相正交。
现在来验证Y的协方差:
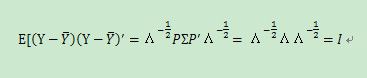
所以,对于旋转压缩后的Y的各分量之间线无关,而且已经标准化,与尺度无关,此时以Y分量为坐标轴形成的空间中,离中心距离为常数C的面为正圆球面。因而可以直接使用欧氏距离描述两点之间的相似度,也就是距离,因此有:

因此,当原坐标经过适当的变换之后,可以求出两点与尺度无关的距离,这也是使用马氏距离的原因。
总之,mahalanobis距离是基于样本分布的一种距离。物理意义就是在规范化的主成分空间中的欧氏距离。所谓规范化的主成分空间就是利用主成分分析对一些数据进行主成分分解。再对所有主成分分解轴做归一化,形成新的坐标轴。由这些坐标轴张成的空间就是规范化的主成分空间。换句话说,主成分分析就是把椭球分布的样本改变到另一个空间里,使其成为球状分布。而mahalanobis距离就是在样本呈球状分布的空间里面所求得的Euclidean距离。
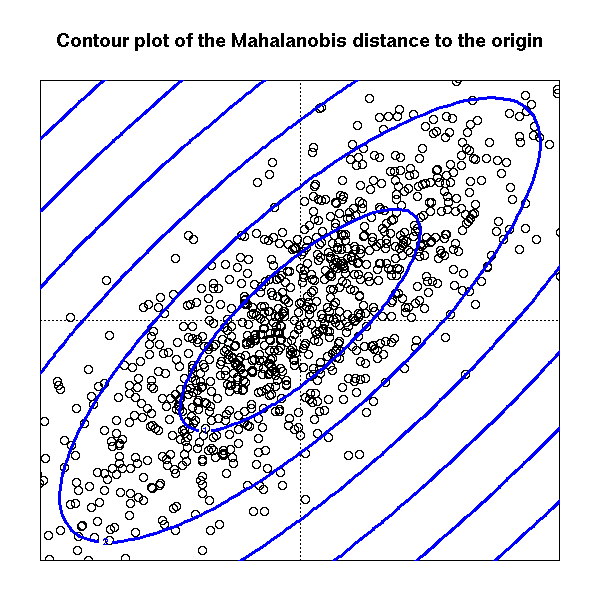
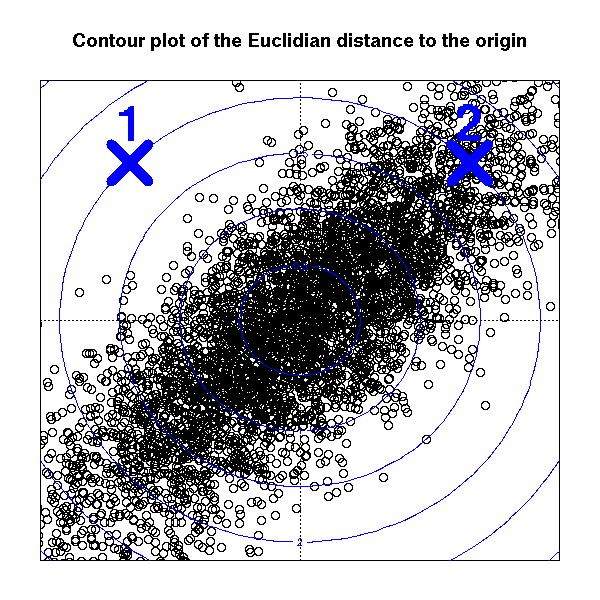
当然,上面的解释只是对椭球分布而言,对一般分布,只能消除分布的二阶相关性,而不能消除高阶相关性。