编译原理根据项目集规范族构造LR(0)分析表
上回把文法的LR(0)项目集规范族搞了半天,革命进行了一半。
鼓捣了半天整了一堆项目集规范族出来,总是有用的呀,接下来就是在那堆的基础上构造分析表了,构造好分析表就能分析输入串了。本文主要讲LR(0)分析表的构造和输入串分析过程。
我这个菜鸡都觉得是通!俗!易!懂!的!!
憋说话往下看->
多的不扯,博(cai)主(ji)我使用的是清华大学出版社的《编译原理第二版》,第二版哦,不知道第三版的小伙伴内容是不是一样的,页数好像不一样我记得。在LR分析这一章的第二节后面,就是有项目集规范族那张图那儿,我们还是以那个文法为主题讲。
为了方便我直接为大家列好啦~
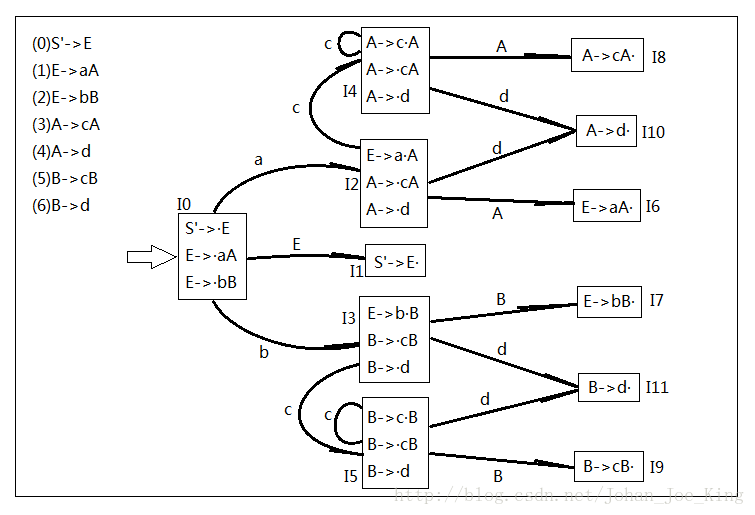
OK,这是上回我们构造好的项目集规范族,在构造分析表之前我们先画好分析表。
先写好ACTION和GOTO两个列标题,然后在ACTION下面写一排文法的所有的终结符,别忘了还有#,GOTO下面写文法中除了S'以外的所有的非终结符。

OK,接下来是这样的,书上也有详细的关于分析表构造算法的解释,说白了,其意思应该是这样的:
1、找项目集规范族有S'->A·这种形状的那个状态Ik,就是第k个状态,则把分析表第k行的#列标上acc
2、按顺序(我一般是按状态序号顺序)分析状态的项目和GOTO函数,主要就是看每个项目的点后面的符号。
(1)要是是个终结符,看输入这个终结符后去的哪个状态,比如当前是状态I0,对于第二个项目E->·aA,输入a以后去了状态I2,那就在分析表中第0行的a列写上S2,意思就是状态Ik输入Vt后去了Ij状态。
(2)要是是个非终结符,这个更好理解,比如从状态Ik输入这个非终结符以后去了状态Ij,那就在GOTO表的第k行第Vn列写j。
3、你会发现有的项目的点是在最后,这就是分析表里面那些小r的来历了。先看这个项目所在的状态,再看点前面的规则是文法里面的第几个规则,比如说状态I10的A->d·里面的A->d就是文法的第4条规则,那就在分析表的第10行所有的终结符列包括#列写上r4,就是ACTION列的一行写满。即状态Ik的项目来自于文法的第j条规则,则分析表的第k行都是rj。
我们具体试试吧:
1、先找acc,以免高兴过头了忘记。状态I1里面有S'->E·,所以acc在第1行。

2、按顺序开始看I0,第一个项目点后面是非终结符E,输入E前往状态I1,所以GOTO表的第0行第E列写1。第二个项目点后面是a,输入a以后前往I2,则ACTION表第0行第a列写S2。第三个项目点后面是b,输入b后前往I3,则ACTION表第0行第b列写S3。

3、状态I1有acc了,不管了。跳过看I2。同理,输入A的时候改GOTO表,输入c和d的时候改ACTION表,而且都是写S形式的。你会发现一直到I5都是这样。

4、状态I6,这是个点在最后面的项目,看前面的规则,是文法的第1个规则,那第6行就写一行r1。状态I7,点前面的规则是文法的第2条规则,则第7行写一行r2。同理到状态I11。

到这里该文法的LR(0)分析表就!构!造!完!了!
是不是很心累,要是看书看不懂听课犯糊涂更心累!别问我为啥知道......
顺便说说这个表又是拿来干嘛的吧,搞了半天当然是有用的有实际价值的是符合社会发展所需要求的。
输入串的分析过程,在实际的分析程序里面还有两个重要的辅助英雄角色,状态栈和符号栈。要是做题的话就写在草稿纸上吧,考试的时候应该也不会让你分析超长的串。分析前先往状态栈压一个0进去,符号栈压一个#进去,输入串最后加个#。
比如我要分析bccd,书上也有例子。
当前输入串bccd#,即将输入b,看状态栈顶,是0,去看分析表,第0行第b列是S3,不是r什么什么。好,把角标3压状态栈,b压符号栈,输入串少一个。
当前为ccd#,即将压c,状态栈顶为3,看分析表第3行第c列,是S5,好,5和c分别压栈。
当前为cd#,即将压c,状态栈顶为5,看分析表第5行第c列,是S5,好,5和c分别压栈。
当前为d#,即将压d,状态栈顶为5,看分析表第5行第d列,是S11,好,11和d分别压栈。
当前为#,即将压#,状态栈顶为11,看分析表第11行第#列,是r6。好,历史走到了转折点。赶紧去看文法的第6条规则,把符号栈顶归约为B,状态栈顶11弹出。然后再看状态栈顶5和符号栈顶B,GOTO表第5行第B列是9,记得在分析过程这一步的GOTO写9,然后把9压状态栈。这里要分清栈操作的先后顺序。
当前为#,即将压#,状态栈顶为9,看分析表第9行第#列,是r5,好,同上一个步骤找规则归约掉然后压栈,然后找GOTO表把新状态压栈。
重复上面的操作。
最后一步是这样的,状态栈顶为1,即将压#,分析表第1行第#列为acc,至此分析结束,bccd是该文法的产生式。
如果是错误串呢?
你放心,早做不下去了,崩了。
菜鸡写篇博客挺不容易的
如果内容有误请小伙伴们在下方评论区指出