视觉检测——ground truth的含义
机器学习包括有:
- 监督学习---(supervised learning)
- 无监督学习---(unsupervised learning)
- 半监督学习---(semi-supervised learning)
在监督学习中,数据是有标注的,以(x, t)的形式出现,其中x是输入数据,t是标注.
正确的t标注是ground truth, 错误的标记则不是。(也有人将所有标注数据都叫做ground truth).
而![]() 模型函数的数据则是由(x, y)的形式出现的。其中x为之前的输入数据,y为模型预测的值.
模型函数的数据则是由(x, y)的形式出现的。其中x为之前的输入数据,y为模型预测的值.
![]() x-输入数据 t-标注数据
x-输入数据 t-标注数据
![]() x-输入数据 y-模型预测数据
x-输入数据 y-模型预测数据
标注会和模型预测的结果作比较。
在损耗函数(loss function / error function)中会将y 和 t 作比较,从而计算损耗(loss / error)。 比如在最小方差中:

因此如果标注数据不是ground truth (t 产生偏差),那么loss的计算将会产生误差,从而影响到模型质量。
举例说明:
1.错误的标注
标注数据1 ( (84,62,86) ,1),其中x =(84,62,86), t = 1 。 //正确 ,数据1是ground truth
标注数据2 ( (84,162,86) , 1),其中x =(84,162,86), t = 1 //错误,数据2不是ground truth
预测数据1 y = -1
预测数据2 y = -1
运用上述公式计算:
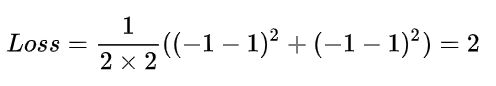
2.正确的标注
标注数据1 ( (84,62,86) ,1),其中x =(84,62,86), t = 1 //正确 ,数据1是ground truth
标注数据2 ( (84,162,86) , 1),其中x =(84,162,86), t = -1 //正确 ,数据2是ground truth
这里标注数据1和2都是ground truth。
预测数据1 y = -1
预测数据2 y = -1
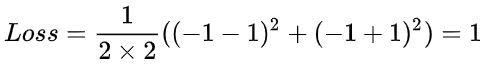
ground truth标注的错误,导致最后模型估计计算的差异。
此外ground truth标注的数据还是其他数据的参考模型,错误的标注会导致实验结果精确度很大的降低。
总结:
ground truth就是用于收集训练集的分类的参数的是否正确的标定参数。
主要用于统计模型中验证或推翻某种研究假设,术语也指收集准确客观的数据用于验证的过程。
就是建立一个统一的高精度的标准结果,用于比对实验数据。
他是一个评价标准。
参考:https://blog.csdn.net/wuruiaoxue/article/details/78761498