强化学习之最基础篇(算法实现及基础案例学习)
本博客接着上一篇“强化学习之最基础篇”而来,是基于上一篇的博客进一步的探究,因为前一篇博客完全是对于基本概念的介绍以及基本算法的熟悉,这一篇便是偏应用,讲理论的算法加以实现,并且跑了一个小游戏从而感受一下强化学习的魅力。
背景:在PA公司实习期间,由于公司每周都会有分享会,大家轮着来分享自己的研究学习成果(我感觉其实很不错),然后就轮到了我,临危受命,老大让我这次分享强化学习,此前对此我一无所知,于是硬着头皮来了,就产生了上一篇的博客,上一篇分享之后老大又从工程方面想我发问,比如强化学习相对于传统的监督、半监督的优势在哪?它适合是什么样的数据集?怎样将强化学习应用于实际工作中?所以老大就是老大,处处都是从工程角度出发考虑问题,可以让我学习一波,就这样我开始了第二次小组每周分享会。
任务:实现强化学习算法,跑一个案例,分析强化学习的优势等等
废话说明:由于公司小组分享会是以ppt+讲解的形势呈现,所以本次博客内容主要来自于ppt截图(ps:我知道你对我很无奈),鉴于ppt内容过于简介,于是该解释之处我也有些许说明,总的来说此博客更像是本人的笔记,而非分享大家的博客,可能是我太懒吧,没去仔细整理,不过有问题还是可以探讨交流的,毕竟我也是菜鸟!;另外分享内容过于简单,内容较少,其实也就是一个DQN大致的介绍和基本的演示,并没有深度的算法分析和实现解析,让大家失望了,所以博客的结尾会有彩蛋(我的学习基本依赖于周志华老师的西瓜书(链接)以及莫烦大神的强化学习系列课程(链接),以下内容基本上来源于他们)。
开始吧!:
1、

2、

由于此次所演示案例使用算法为新的算法(前一次博客并未提及,于是在算法实现及案例分析之前先介绍一下基本的算法知识作为引入)
上一篇中大致介绍了Sarsa算法,我们可以看上图中的左侧的Sarsa算法,算法第6行状态值函数的估计和第4行动作的执行都是用了第5行产生的动作a’,也就是说状态值函数Q和动作执行是利用相同的动作来进行的,所以Sarsa也称为同策略学习算法。
不同于左侧的Sarsa算法,右侧的Q-learning算法在状态值函数Q的估计和动作的执行时是采用了不同的动作a进行的,具体的看算法第6行是用第5行产生的动作a(当前策略下最优的动作a)来进行状态值函数的估计,而算法第4行在执行动作时时重新计算出新的动作(当前策略加上ε-贪心算法)来执行,也就是说该算法在状态值函数的估计和动作执行时所采用的动作是不同的,因此Q-learning也称为异策略学习算法。
差异:我们可以看出两种算法其实基本类似,除了上面所提到的差别,那么这么做是为什么呢?(这里借用 莫烦大神的话,后面再说说他的niubility)从算法来看, 这就是他们两最大的不同之处了. 因为 Sarsa 是说到做到型, 所以我们也叫他 on-policy, 在线学习, 学着自己在做的事情. 而 Q learning 是说到但并不一定做到, 所以它也叫作 Off-policy, 离线学习. 而因为有了 maxQ, Q-learning 也是一个特别勇敢的算法.为什么说他勇敢呢, 因为 Q learning 机器人 永远都会选择最近的一条通往成功的道路, 不管这条路会有多危险. 而 Sarsa 则是相当保守, 他会选择离危险远远的, 拿到宝藏是次要的, 保住自己的小命才是王道. 这就是使用 Sarsa 方法的不同之处.
3、
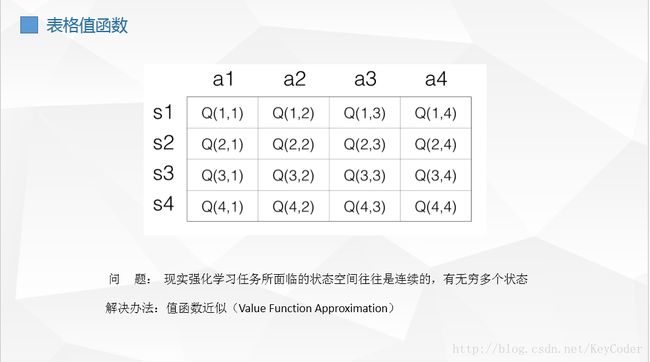
在上面的简单分析中,我们使用表格来表示Q(s,a),但是这个在现实的很多问题上是几乎不可行的,因为状态实在是太多。使用表格的方式根本存不下。我们是不可能通过表格来存储状态的。我们有必要对状态的维度进行压缩,解决办法就是 价值函数近似Value Function Approximation,于是它就可以对连续状态空间的值函数进行学习了。
4、

为什么叫近似?因为我们并不知道Q值的实际分布情况,本质上就是用一个函数来近似Q值的分布,所以,也可以说是也将更方便的进行Q-Learning中动作的选择与Q值更新
5、

DQN简单来说就是Q-learning+CNN
训练是一个最优化问题,最优化一个损失函数,目标是让损失函数最小化 ,即通过反向传播使用梯度下降的方法来更新神经网络的参数。所以,要训练Q网络,我们要能够为Q网络提供有标签的样本。
所以,我们把目标Q值作为标签不就完了?我们的目标不就是让Q值趋近于目标Q值吗?
大家回想一下Q-Learning算法,Q值的更新依靠什么?依靠的是利用Reward和Q计算出来的目标Q值。
6、

7、
cartpole视频播放链接
cartpole : 一个杆通过一个未被驱动的接头连接到一个手推车上,手推车沿一条无摩擦的轨道移动。系统通过施加+1或-1的力量来控制。钟摆开始直立,目标是防止它倒下。杆的每个时间步都提供+1的奖励。当杆子距离垂直方向超过15度时,情节结束,或者车子从中心移动超过2.4个单位。
8、
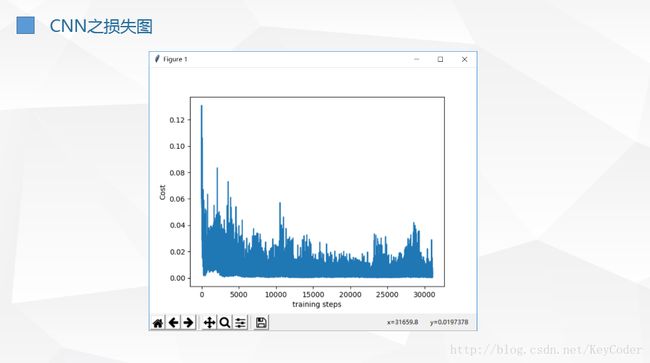
我们可以看到,不同于传统的监督学习等损失函数的曲线(平滑且损失不断递减,强化学习的损失函数是一个纠结的曲线,损失函数的波动很大,这正是因为强化学习在不断探索环境并根据感知到的环境来执行动作时所带来的损失波动(也会因为引入的动作执行随机性带来的损失函数值波动),也体现出了强化学习与监督学习、半监督学习等的区别
9、
mountaincar视频播放链接
mountaincar : 是一个动力不足的车辆必须在陡峭的山坡上行驶的问题。由于重力比汽车发动机强,即使在全油门时,汽车也不能简单地加速陡坡。汽车坐落在一个山谷中,必须学习如何在对面的山坡上行驶,才能在最右边的山顶上进入目标。该领域已被用作各种强化学习论文的测试平台。
山车问题虽然相当简单,但是通常被应用,因为它需要一个强化学习代理来学习两个连续变量:位置和速度。对于车辆的任何给定状态(位置和速度),代理人都有可能向左行驶,向右行驶或根本不使用发动机。在问题的标准版本中,agent在每一个没有达到目标的时间步骤都会收到负面报酬。在初始成功之前,agent没有关于目标的信息。
10、
分析类似于8
11、

补充
博客总结:博客分享过于简单,无奈自身水平有限,且接触时间过短,但是还是感受到了强化学习的魅力,相信自己只要认真专研还是可能有希望的(一个强化学习小白的自我鼓励,哈哈哈)
莫烦大神强化学习课程系列链接:
(莫烦大神是真大神,有自己的python学习课程,而且讲解有代码有视频,有留言会回复,所以后续感兴趣的伙伴可以关注一下他,毕竟我菜鸟带不动大家,下面是有关DQN的此次分享的链接)
什么是 DQN
DQN 算法更新 (Tensorflow)
DQN 神经网络 (Tensorflow)
DQN 思维决策 (Tensorflow)
OpenAI gym 环境库