【论文笔记】Relation Classification via Multi-Level Attention CNNs
一、概要
该paper发于ACL2016上,主要提出了一个基于多Attention机制CNN网络的实体关系抽取方法,其中Attention机制主要是:Input Attention Mechanism和Convolutional Max-pooling Attention Mechanism。在不依赖于外部先验知识和特征的情况下,就已经能够得到高于当前最好方法的结果。
二、模型方法
2.1 模型结构
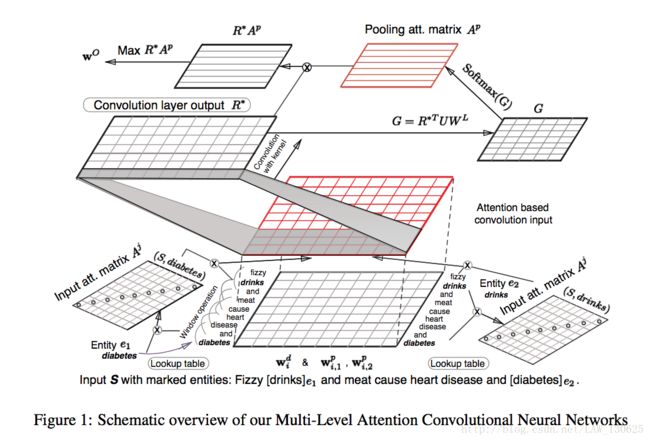
2.2 Input Representation
对于一个句子S=(w1,w2,…,wn),以及其中的两个实体e1(wp)和e2(wt),1<=p,t<=n,均将其转为词向量;并且根据每个词与实体的相对位置,也转为word position embeddings ,很明显,每个词与两个实体有两个相对位置,所以每个词有两个word position embeddings,所以,每个词的Input Representation由三部分组成,如句子中第i个词的Embedding可以表示为 WiM=[(Wdi)T,(Wpi,1)T,(Wpi,2)T] ,其中右边第一项为word embedding,第二和第三个分别为该词语实体e1和e2相对位置的word position embeddings。
同时为了充分得到上下文的信息,对于上面得到的使用滑窗的方法座位最终的Input Representation,即: zi=[(WMi−(k−1)/2)T,...,(WMi+(k−1)/2)T] ,其中k为滑窗大小。
2.3 Input Attention Composition
根据2.2得到的word和entity Embedding,可以通过计算每个word与entity的內积以衡量它们的相近程度,即: Aji,i=f(ej,wI) ,其中f()为內积函数,最终由softmax函数:
到这里已经获得词与两个实体的相关程度的量了,那么这两个量就可以作为Input Attention了,具体怎么使用呢?可以通过平均的方法,即: ri=zia1i+a2i2 ,其中z为上文得到的Input Representation,也可以通过串联的方法,即 ri=[(zia1i),(zia2i)] ,另外也可通过求差值的方法,所以最终的Input是 R=[r1,r2,...,rn] 。
2.4 Convolutional Max-Pooling with Attention
这时CNN就上场了,设卷积核 Wf 的大小为 dc∗k(dw+2dp) ,其中 dc 为卷积操作的大小, k(dw+2dp) 为之前word和word position embedding串联和k个滑窗的大小。可以得到:
这时使用到Attention-Based Pooling了,通过:
其中U是一个在网络中学习的权值矩阵, WL 是关于labels一个矩阵,根据实体类别种类class_num和卷积核个数filter_num在网络中学习而得,后面的代价函数还会用到。最终得到的attention pooling matrix Ap 定义为:
那么最终输出为:
2.5 代价函数
该论文提出使用 δθ(S,y) 衡量句子S的输出与上文提到的W^{L}中正确label对应向量的相关程度方法,具体为:
在相减前均使用L2正则化,该作者还出输出与错误标签对应的 Wy′ 的相关程度,并找到一个最小值,然后最大化它,很符合我们的直觉,那么最终的代价函数为:
其中 β 为正则化系数。至此,模型结构就是这样。
三、实验和结果
实验数据取自SemEval-2010 Task 8 dataset 。在Wikipedia上使用 word2vec skip-gram model训练词向量。作者在双attention model Att-Pooling- CNN模型上取得F1值为88%。
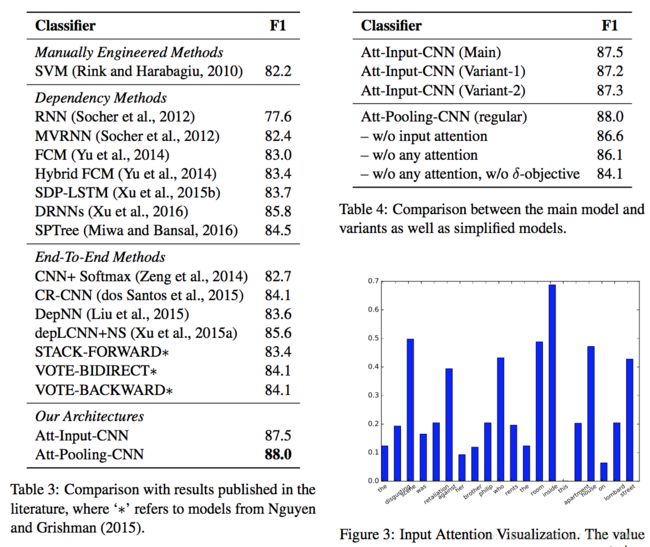
作者还分析了一些错误分类的实体关系,以及训练时Att-Input-CNN and Att-Pooling-CNN的特性,如下图:


四、结论与思考
作者认为其提出的全新模型性能优于目前他人提出的模型或者利用先验知识得到的结果,并且认为此类模型在特定任务的的实体关系分类也能取到很好地效果。
五、个人思考:
①Input Representation部分k个相邻的词组成一个输入,设计的Input Attention知识针对一个word,而不是相邻的k个word;
②该模型在Max-Pooling with Attention的设计上没有体现出其合理之处,文中缺少其解释或者intuition,可能还有更好的设计方法;
参考文献:
①Linlin Wang, Zhu Cao.Relation Classification via Multi-Level Attention CNNs.http://iiis.tsinghua.edu.cn/~weblt/papers/relation-classification.pdf
②代码链接:https://github.com/FrankWork/acnn