FLink 源码分析--(三)Time Window Join
文章目录
- 一、概述
- 1、FLink SQL 优势
- 2、FLink SQL 核心功能
- 3、FLink Join的分类
- 4、Join图示
- 二、创建Time Window Join Function
- 1、测试用例
- 2、StreamExecWindowJoinRule规则
- 3、StreamExecWindowJoin物理计划
- 三、RowTimeBoundedStreamJoin数据处理流程
一、概述
1、FLink SQL 优势
在介绍Time Window Join前,可以先看看Flink SQL相关的整体介绍和架构:

- 声明式:用户只需要表达我想要什么,至于怎么计算那是系统的事情,用户不用关心。
自动调优。查询优化器可以为用户的 SQL 生成最有的执行计划。用户不需要了解它,就能自动享受优化器带来的性能提升。- 易于理解:很多不同行业不同领域的人都懂 SQL,SQL 的学习门槛很低,用 SQL 作为跨团队的开发语言可以很大地提高效率。
- 稳定:SQL 是一个拥有几十年历史的语言,是一个非常稳定的语言,很少有变动。所以当我们升级引擎的版本时,甚至替换成另一个引擎,都可以做到兼容地、平滑地升级。
流与批的统一:Flink底层 runtime 本身就是一个流与批统一的引擎。而 SQL 可以做到 API 层的流与批统一。
2、FLink SQL 核心功能

从上图可以看到Aggregation和Join属于SQL中重要的一员,我们在业务场景中,也会经常用到聚合和Join
3、FLink Join的分类
FLink内部实现的Join有多种类型,分为:
1、Join算子(即普通的join,不区分condition里面的时间条件,左右两侧流数据可以长时间保存)
2、Join LETERAL(右表是一个自定义函数TableFunction实现的视图,遍历进行Join)
3、Join Temporal Table时态表(右表是通过registerTemporalTable注册,join的时候,右表返回指定时间范围内,最新的数据,例如计算汇率的场景)
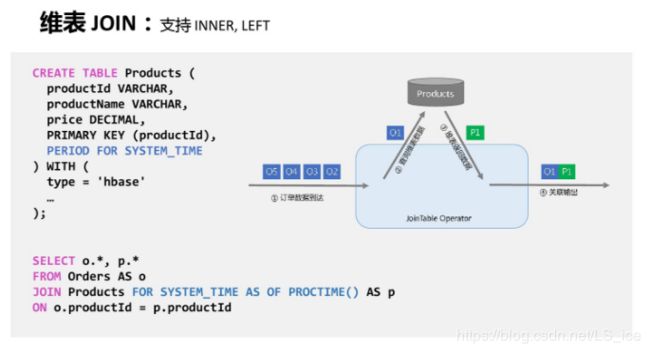
4、维表Join(分同步和异步两种方式,可以查询数据库数据,补全流中字段信息,例如补全订单用户名场景)
5、Time Window Join(也可以叫做Time Interval Join,即Join条件中,带有时间范围的双流Join,例如订单表和付款表进行补全的场景,付款有1小时时效信息)
4、Join图示
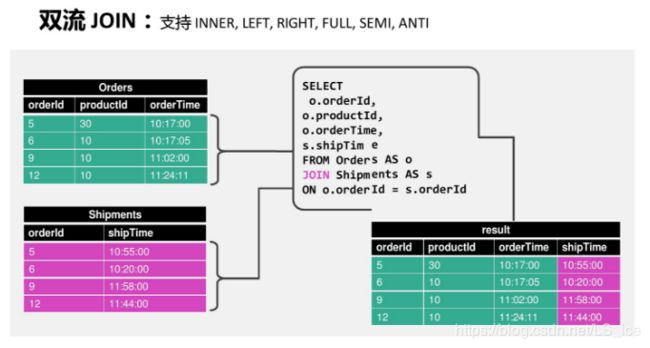
双流Join(条件中未带时间信息):
维表Join(SQL语句中具有FOR SYSTEM_TIME关键字):
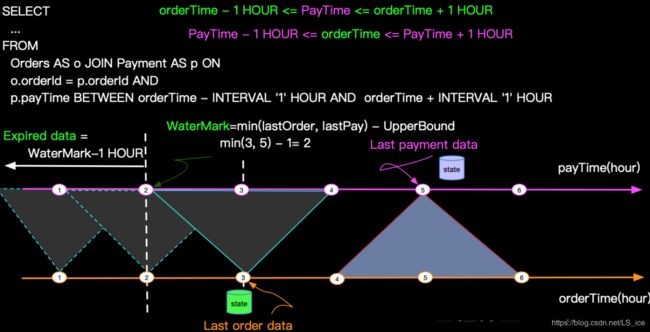
Time Window Join(条件上带有BETWEEN … AND时间表达式):
SELECT
o.orderId,
o.productName,
p.payType,
o.orderTime,
cast(payTime as timestamp) as payTime
FROM
Orders AS o JOIN Payment AS p ON
o.orderId = p.orderId AND
p.payTime BETWEEN orderTime AND
orderTime + INTERVAL ‘1’ HOUR
本文重点讨论Time Window Join,其余4种Join类型,后续我们有时间再逐一讨论。
二、创建Time Window Join Function
1、测试用例
在进行源码分析前,我们先引入FLink 1.9.0源码中提供的测试用例,本文后续章节也根据这个用例展开,并附带一些Debug调试数据,来加深对源码的理解:
源码中,WindowJoinITCase#testRowTimeLeftOuterJoin()测用例如下:
class WindowJoinITCase(mode: StateBackendMode) extends StreamingWithStateTestBase(mode) {
@Test
def testRowTimeLeftOuterJoin(): Unit = {
val sqlQuery =
"""
|SELECT t1.key, t2.id, t1.id
|FROM T1 AS t1 LEFT OUTER JOIN T2 AS t2 ON
| t1.key = t2.key AND
| t1.rowtime BETWEEN t2.rowtime - INTERVAL '5' SECOND AND
| t2.rowtime + INTERVAL '6' SECOND AND
| t1.id <> 'L-5'
""".stripMargin
val data1 = new mutable.MutableList[(String, String, Long)]
// for boundary test
data1.+=(("A", "L-1", 1000L))
data1.+=(("A", "L-2", 2000L))
data1.+=(("B", "L-4", 4000L))
data1.+=(("B", "L-5", 5000L))
data1.+=(("A", "L-6", 6000L))
data1.+=(("C", "L-7", 7000L))
data1.+=(("A", "L-10", 10000L))
data1.+=(("A", "L-12", 12000L))
data1.+=(("A", "L-20", 20000L))
val data2 = new mutable.MutableList[(String, String, Long)]
data2.+=(("A", "R-6", 6000L))
data2.+=(("B", "R-7", 7000L))
data2.+=(("D", "R-8", 8000L))
data2.+=(("A", "R-11", 11000L))
val t1 = env.fromCollection(data1)
.assignTimestampsAndWatermarks(new Row3WatermarkExtractor2)
.toTable(tEnv, 'key, 'id, 'rowtime)
val t2 = env.fromCollection(data2)
.assignTimestampsAndWatermarks(new Row3WatermarkExtractor2)
.toTable(tEnv, 'key, 'id, 'rowtime)
tEnv.registerTable("T1", t1)
tEnv.registerTable("T2", t2)
val sink = new TestingAppendSink
val result = tEnv.sqlQuery(sqlQuery).toAppendStream[Row]
result.addSink(sink)
env.execute()
val expected = mutable.MutableList[String](
"A,R-6,L-1",
"A,R-6,L-2",
"A,R-6,L-6",
"A,R-6,L-10",
"A,R-6,L-12",
"B,R-7,L-4",
"A,R-11,L-6",
"A,R-11,L-10",
"A,R-11,L-12",
"B,null,L-5",
"C,null,L-7",
"A,null,L-20")
assertEquals(expected.toList.sorted, sink.getAppendResults.sorted)
}
}
这个用例比较简单,是一个Left Outer类型的Time Window Join,从sqlQuery 对应的SQL就可以看出,
同时,expected就是期望的测试结果(未排序)
2、StreamExecWindowJoinRule规则
具有BETWEEN…AND时间表达式的Join,默认会匹配到StreamExecWindowJoinRule,这个Rule规则,负责将FlinkLogicalJoin逻辑计划,转换为StreamExecWindowJoin物理计划:
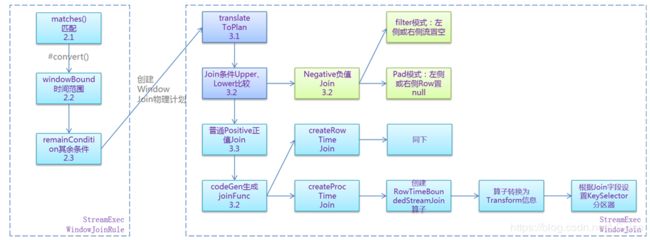
双流Join对应的Rule和physical物理计划分别为:StreamExecWindowJoinRule、StreamExecWindowJoin,对应分析如下:
a)、StreamExecWindowJoinRule主要是在#convert方法中,将逻辑计划FlinkLogicalJoin转化为StreamExecWindowJoin物理计划,其中涉及到提取join条件和时间范围
b)、StreamExecWindowJoin物理计划用来创建Join Function、Operator及Transform信息,对应有Process Time 、Event Time 及负值FlatMap几类Join Function
Rule这里我们重点关注下如何创建物理算子:
class StreamExecWindowJoinRule
extends ConverterRule(
....,
"StreamExecWindowJoinRule") {
override def convert(rel: RelNode): RelNode = {
val join: FlinkLogicalJoin = rel.asInstanceOf[FlinkLogicalJoin]
val joinRowType = join.getRowType
val left = join.getLeft
val right = join.getRight
def toHashTraitByColumns(
columns: util.Collection[_ <: Number],
inputTraitSet: RelTraitSet): RelTraitSet = {
...
}
...
val (windowBounds, remainCondition) = WindowJoinUtil.extractWindowBoundsFromPredicate(
join.getCondition,
left.getRowType.getFieldCount,
joinRowType,
join.getCluster.getRexBuilder,
tableConfig)
new StreamExecWindowJoin(
rel.getCluster,
providedTraitSet,
newLeft,
newRight,
join.getCondition,
join.getJoinType,
joinRowType,
windowBounds.get.isEventTime,
windowBounds.get.leftLowerBound,
windowBounds.get.leftUpperBound,
windowBounds.get.leftTimeIdx,
windowBounds.get.rightTimeIdx,
remainCondition)
}
}
关注下windowBounds, remainCondition两个变量的值,这里贴下调试数据和说明,就一目了然了:
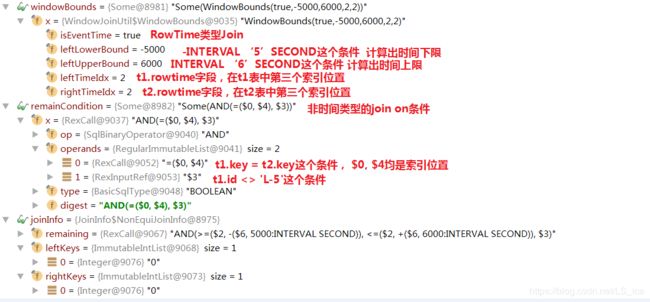
3、StreamExecWindowJoin物理计划
StreamExecWindowJoin物理计划的核心就是#translateToPlanInternal(),他负责将:
val leftPlan = getInputNodes.get(0).translateToPlan(tableEnv)
.asInstanceOf[StreamTransformation[BaseRow]]
val rightPlan = getInputNodes.get(1).translateToPlan(tableEnv)
.asInstanceOf[StreamTransformation[BaseRow]]
leftPlan 和rightPlan 这两个左右两侧的Transformation,进行Join转换,生成join对应的Transformation,即TwoInputTransformation,由于我们SQL中指定的是rowtime join,这里会直接走到#createRowTimeJoin()这个分支代码上来:
class StreamExecWindowJoin(
...)
extends BiRel(cluster, traitSet, leftRel, rightRel)
... {
private def createRowTimeJoin(
leftPlan: StreamTransformation[BaseRow],
rightPlan: StreamTransformation[BaseRow],
returnTypeInfo: BaseRowTypeInfo,
joinFunction: GeneratedFunction[FlatJoinFunction[BaseRow, BaseRow, BaseRow]],
leftKeys: Array[Int],
rightKeys: Array[Int]
): StreamTransformation[BaseRow] = {
val leftTypeInfo = leftPlan.getOutputType.asInstanceOf[BaseRowTypeInfo]
val rightTypeInfo = rightPlan.getOutputType.asInstanceOf[BaseRowTypeInfo]
val rowJoinFunc = new RowTimeBoundedStreamJoin(
flinkJoinType,
leftLowerBound,
leftUpperBound,
0L,
leftTypeInfo,
rightTypeInfo,
joinFunction,
leftTimeIndex,
rightTimeIndex)
val ret = new TwoInputTransformation[BaseRow, BaseRow, BaseRow](
leftPlan,
rightPlan,
"Co-Process",
new KeyedCoProcessOperatorWithWatermarkDelay(rowJoinFunc, rowJoinFunc.getMaxOutputDelay)
.asInstanceOf[TwoInputStreamOperator[BaseRow,BaseRow,BaseRow]],
returnTypeInfo,
getResource.getParallelism
)
// set KeyType and Selector for state
val leftSelector = KeySelectorUtil.getBaseRowSelector(leftKeys, leftTypeInfo)
val rightSelector = KeySelectorUtil.getBaseRowSelector(rightKeys, rightTypeInfo)
ret.setStateKeySelectors(leftSelector, rightSelector)
ret.setStateKeyType(leftSelector.getProducedType)
ret
}
}
这里我们看下调试数据(有分析说明):

joinFunction这个变量是代码生成的,对刚接触的读者来说,可能有点困惑,这里简单介绍下,他的核心目标就是对输入的in1、in2两侧Row数据,按照我们设置的SQL Join判断逻辑,构造joinedRow,并collect到下游算子:
JoinedRow joinedRow = new org.apache.flink.table.dataformat.JoinedRow()
BaseRow in1 = (org.apache.flink.table.dataformat.BaseRow) _in1;
BaseRow in2 = (org.apache.flink.table.dataformat.BaseRow) _in2;
if (result$63) {
joinedRow.replace(in1,in2);
c.collect(joinedRow);
}
new RowTimeBoundedStreamJoin(…)就是创建Function最终的逻辑,下一章节我们分析下RowTimeBoundedStreamJoin这个Function
三、RowTimeBoundedStreamJoin数据处理流程
- RowTimeBoundedStreamJoin和ProcTimeBoundedStreamJoin均为TimeBoundedStreamJoin的子类
- RowTimeBoundedStreamJoin和ProcTimeBoundedStreamJoin分别定义了RowTime和ProcTime字段时间的获取规则
- 真正的数据join处理逻辑在TimeBoundedStreamJoin这个Function里,处理左、右侧数据流程图:
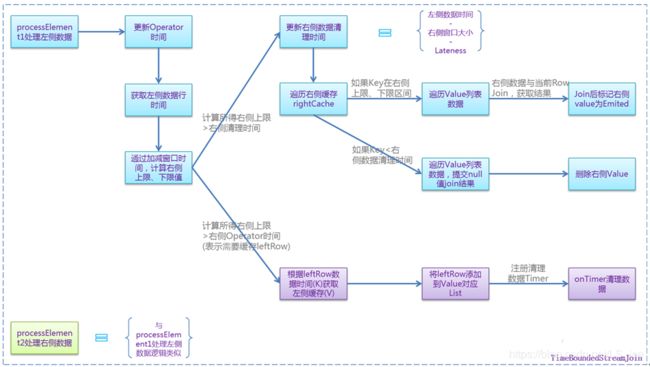
Join的核心处理逻辑,可以处理左侧数据函数#processElement1()为例进行分析:
1、左侧数据到来,拿右侧的状态数据进行遍历,判断是否达到join条件
2、遍历右侧数据时,还会判断右前对侧数据rightTime是否达到了清理的条件,走清理逻辑
3、rightOperatorTime < rightQualifiedUpperBound表示右侧的计算进度,比当前左侧输入数据的上限值慢,需要缓存左侧进度
abstract class TimeBoundedStreamJoin extends CoProcessFunction {
public void processElement1(BaseRow leftRow, Context ctx, Collector out) throws Exception {
joinCollector.setInnerCollector(out);
updateOperatorTime(ctx);
long timeForLeftRow = getTimeForLeftStream(ctx, leftRow);
long rightQualifiedLowerBound = timeForLeftRow - rightRelativeSize;
long rightQualifiedUpperBound = timeForLeftRow + leftRelativeSize;
boolean emitted = false;
if (rightExpirationTime < rightQualifiedUpperBound) {
rightExpirationTime = calExpirationTime(leftOperatorTime, rightRelativeSize);
Iterator>>> rightIterator = rightCache.iterator();
while (rightIterator.hasNext()) {
Map.Entry>> rightEntry = rightIterator.next();
Long rightTime = rightEntry.getKey();
if (rightTime >= rightQualifiedLowerBound && rightTime <= rightQualifiedUpperBound) {
List> rightRows = rightEntry.getValue();
boolean entryUpdated = false;
for (Tuple2 tuple : rightRows) {
joinCollector.reset();
joinFunction.join(leftRow, tuple.f0, joinCollector);
emitted = emitted || joinCollector.isEmitted();
if (joinType.isRightOuter()) {
if (!tuple.f1 && joinCollector.isEmitted()) {
// Mark the right row as being successfully joined and emitted.
tuple.f1 = true;
entryUpdated = true;
}
}
}
if (entryUpdated) {
// Write back the edited entry (mark emitted) for the right cache.
rightEntry.setValue(rightRows);
}
}
if (rightTime <= rightExpirationTime) {
if (joinType.isRightOuter()) {
List> rightRows = rightEntry.getValue();
rightRows.forEach((Tuple2 tuple) -> {
if (!tuple.f1) {
// Emit a null padding result if the right row has never been successfully joined.
joinCollector.collect(paddingUtil.padRight(tuple.f0));
}
});
}
// eager remove
rightIterator.remove();
} // We could do the short-cutting optimization here once we get a state with ordered keys.
}
}
// Check if we need to cache the current row.
if (rightOperatorTime < rightQualifiedUpperBound) {
// Operator time of right stream has not exceeded the upper window bound of the current
// row. Put it into the left cache, since later coming records from the right stream are
// expected to be joined with it.
List> leftRowList = leftCache.get(timeForLeftRow);
if (leftRowList == null) {
leftRowList = new ArrayList<>(1);
}
leftRowList.add(Tuple2.of(leftRow, emitted));
leftCache.put(timeForLeftRow, leftRowList);
if (rightTimerState.value() == null) {
// Register a timer on the RIGHT stream to remove rows.
registerCleanUpTimer(ctx, timeForLeftRow, true);
}
} else if (!emitted && joinType.isLeftOuter()) {
// Emit a null padding result if the left row is not cached and successfully joined.
joinCollector.collect(paddingUtil.padLeft(leftRow));
}
}
}
这段代码较长,且里面一些变量都涉及到了时间,如果只从变量的字面意思不同容易理解,这里可以简单的记住几个值:
rightQualifiedLowerBound、rightQualifiedUpperBound就是数据时间,例如6000L加上或减去窗口设置的大小,例如5000L,得到的上下限值
rightTime右侧数据时间,与t2表中rowtime那个字段一致,例如11000L
rightOperatorTime右侧的处理进度,RowTime模式下是watermark水位线,实现在RowTimeBoundedStreamJoin#updateOperatorTime()
最后,建议可以多调试下这个例子,分析TimeBoundedStreamJoin处理数据时的逻辑
推荐一篇文章Apache Flink 漫谈系列(12) - Time Interval(Time-windowed) JOIN,这篇文章把Time Window Join的思想也分析得比较透彻,结合本文的源码分析,可以从多方面加深理解。