Hadoop大数据批处理 -Map/Reduce
Map/reduce基础
逻辑函数: Mappers and Reducers.
• 开发者编写map和reduce 函数,然后提交Jar给Hadoop集群
• Hadoop 处理分发Map 和 Reduce任务跨集群.
• 批处理
MapReduce的守护者 Daemons
•JobTracker (Master)
- 管理MapReduce 工作, 分配任务到不同节点,管理任务失败。
•TaskTracker (Slave)
- 创建独立的Map 和reduce任务
- 将任务状态报告给JobTracker
下面以计算单词个数为案例看看Map/Reduce如何工作:
假设有如下语句将输入Hadoop处理:
"Hadoop uses MapReduce"
"There is a Map phase"
"There is a Reduce phase"
经过Map处理后,也就是对分割成一个个单词如下:
(hadoop, 1)
(uses, 1)
(mapreduce, 1)
(there, 1)
(is, 1)
(a, 1)
(map, 1)
(phase, 1)
(there, 1)
(is, 1)
(a, 1)
(reduce, 1)
(phase, 1)
经过Sort排序, Shuffle洗牌,打散在一起阶段,送入Reducer进行处理,结果如下:
reducers将分三个数据块(HDFS):
0-9, a-l段包含:
(a, [1,1]),
(hadoop, [1]),
(is, [1,1])
字母m-q段包含:
(map, [1]),
(mapreduce, [1]),
(phase, [1,1])
字母r-z段包含:
(reduce, [1]),
(there, [1,1]),
(uses, 1)
注意,由于输入三段话语句中“there”存在两次
“phase”也是两次,经过Reducer统计后,结果output如下:

Map和Reduce的工作职责总结如下:

Map是一种分解,将一个输入分解为多个Key/Value形式的(K,v)数据,而Reduce则是对这些(k,v)数据进行合并统计。
下面图片展示数据进入Hadoop集群后的动态处理过程:
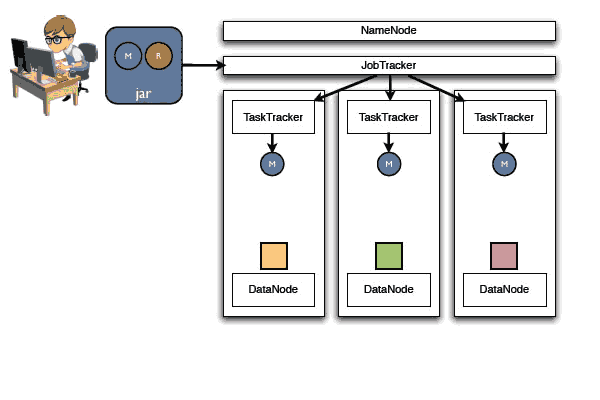
第一步,我们编制的Map和reduce代码打包成jar上传到Namenode,被JobTracker分发到服务器中,注意红蓝绿代码HDFS数据块已经准备好,这些是input输入数据。
第二步进入Map阶段:

Map阶段读取输入数据,然后进行分解成(k,v)数据,同时可以在本地保存这些数据,这里有保存在内存还是文件系统两种区别,当然使用缓存性能要高。如下:

下面进入洗牌打散阶段,注意图中红箭头,一些(k,v) 将根据其Key值在不同节点之间进行调整:

下面进入reduce阶段,Reducers们线程开始启动处理:

reducers们将合并打散的输入(k,v)数据,输出结果到HDFS,如图:
