内存泄露导致线上服务器疯狂FullGC的排查解决过程
前言,线上的是一台java服务,启动参数如下所示:
-Xmx5g -Xms5g -Xmn3g -Xss256k -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -XX:+PrintClassHistogram -XX:PretenureSizeThreshold=2145728 -XX:ErrorFile=$LOG_DIR/systemError.log -Xloggc:$LOG_DIR/gc.log这个服务已经在线上运行了很久并没有出现什么问题.
1月9号下午的时候,我们的同事突然告诉我,线上的一台服务器在疯狂的FullGC,如图所示:
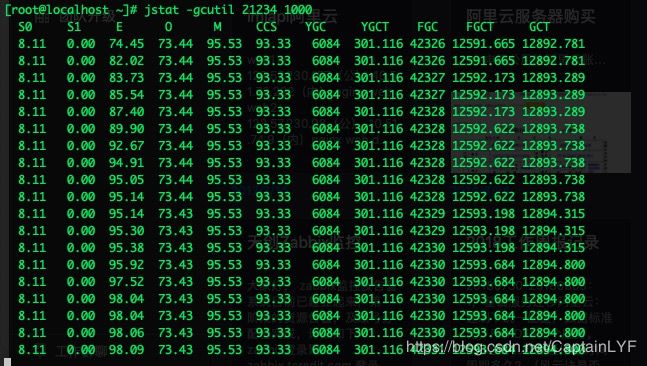
可以看到,FullGC的次数简直就是瞎眼可见地增长,比MinorGc的频率还快,但是同时每次GC完并没有释放任何内存空间。我们的启动参数又指定了老年代使用内存超过70%触发CMS收集器的GC,所以这就形成了一个死循环:GC -->清理完空间并没有变化 -->继续GC。而这时FGC的此时已经超过了42000多次,就算按照2S一次来算,这种死循环也已经运行了超过20个小时!
于是,第一时间我们想到是发生了内存泄露,就赶紧先把当前堆栈的信息dump出来,使用命令:
jmap -dump:format=b,live,file=/data/temp/wtf.hprof 21234
将dump出来的文件下载下来,在本地用JProfiler工具分析:
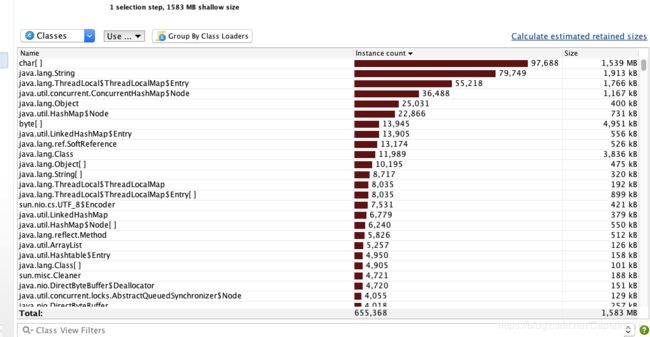
可以看到几乎所有的内存都是被char[]占用了,于是继续查看char[]的引用链:
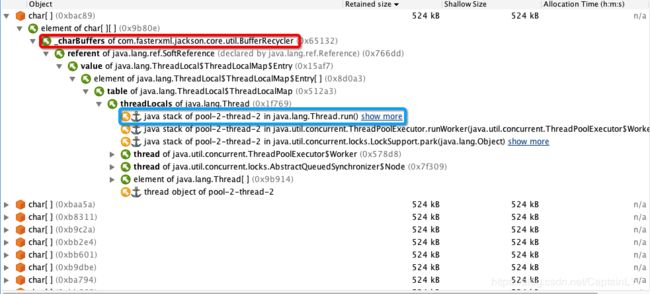
几乎所有的char[]都是被BufferRecycle(红色标注部分)直接引用的,而最终引用链都指向了线程池中的一个线程(蓝色标准部分)。图中我们看到这些cahr[]非常的大,达到了524KB,而像这样的char[]还有将近2600多个!所占用的内存大小约1.3G,是造成这次事故的根本原因。于是我们就开始逐步分析,先分析为什么BufferRecycle会有这么多char数组。于是我们翻看了Jackson源码,最终发现了问题所在:
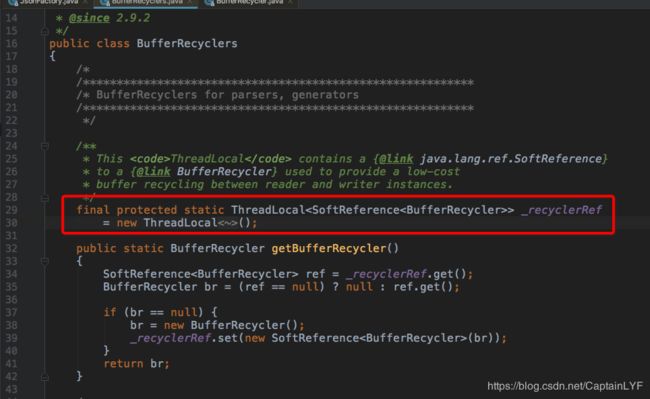
在Jackson将对象转Json时,会默认的从BufferRecyclers中获取BufferRecycle,而BufferRecycle里面存的就是Json字符串的char数组,代码可以去查看com.fasterxml.jackson.databind.ObjectMapper 的writeValueAsString()方法的第一句。
解释一下就是说,默认情况下Jackson在转Json时,会在BufferRecycle类中创建char[]用于存储字符串。而且会将这个BufferRecycle绑定到当前线程上(通过SoftReference),当下一次转Json时,就可以直接获取到BufferRecycle中的char[],这样可以减少char[]的创建。
到这里,我们就已经明确了出现问题的原因:我们在代码中使用了线程池,但是线程池大小设置的不合理,两个静态线程池的大小加起来是4000个。而每个线程都会至少调用一次jackson的转json方法(用于打印日志或者存储数据之类),这样就使得这4000个线程池上都绑定了这样一个BufferRecycle,而线程池的线程是可以复用的,不会被销毁的(项目中所有的线程池都是静态的,不会调用shutdown方法),就这样导致了内存泄露。
那为什么我们的服务没有崩溃呢?也是由于以下两点原因:
1. 线程的数量虽然大,但是也还有限制,在当时的情况下已经达到了巅峰,已经不会再增长了。
2.这些char[]其实是通过软引用(SoftReference)关联到线程上的,在GC的时候是允许被回收掉的,但是软引用的回收有自己的算法(跟空闲内存,上次GC时间,系统参数SoftRefLRUPolicyMSPerMB相关,clock - timestamp > freespace * SoftRefLRUPolicyMSPerMB 当返回为true的时候才会被回收),所以即便在GC的时候也会有软引用不能被清理掉。这就导致了每次GC释放的空间实在有限。
清楚了原因也就明确了解决办法:
1.修改线程池大小,将原来的4000个改为了较为合理的100个(关于合理的线程池大小可以去网上搜)
2.防止jackson使用缓存,添加配置:
objectMapper.getFactory().configure(JsonFactory.Feature.USE_THREAD_LOCAL_FOR_BUFFER_RECYCLING,false);
3.立即清理软引用,在启动参数中添加,这样在GC的时候可以立即将软引用清除掉
+XX:SoftRefLRUPolicyMSPerMB=0
至此,就将线上的问题排查出来并解决了。感慨一下,在问题刚报出来的时候,关于问题出现的原因完全没有头绪,对于JProfiler这样的工具使用的也不是很得手,导致虽然排查了一晚上但是并没有得出什么结论。写这篇博客也是为了做个记录,也希望能帮到几个看到这篇博客的人。虽然问题出现的情况和原因千奇百态,但是排查问题的思路还是大同小异的:
先把堆栈信息dump出来,通过工具查看,找到其中异常的点,查看它的引用链,分析其中的原因,最终得出结论。