【转载】基于 Kubeflow 的机器学习调度平台落地实战
作者:
- 范德良
- 周佳煊
- 张振华
机器学习,特别是深度学习,在蘑菇街这样的电商平台有大量实际业务的落地场景,比如搜索推荐、图像算法、交易风控反作弊等等。随着业务的快速发展,之前已有的基于 Yarn 的调度平台已经无法满足大规模机器学习的计算需求,因此我们在 2018 年和算法工程团队一起建设了基于 Kubeflow 和 Kubernetes 的分布式机器学习平台,并深入到业务层面进行分布式改造,并且从 Kubernetes、Tensorflow 和业务等多个层面进行了一系列的性能调优。
背景
随着机器学习和人工智能的迅猛发展,业界出现了许多开源的机器学习平台。由于机器学习与大数据天然的紧密结合,基于 Hadoop Yarn 的分布式任务调度仍是业界主流,但是随着容器化的发展,Docker + Kubernetes 的云原生组合,也展现出了很强的生命力。
| 公司 | 平台名称 | 集群管理和调度 |
|---|---|---|
| 百度 | PaddlePaddle | Docker+Kubernetes |
| 腾讯 | Angel | Docker+Yarn |
| 阿里 | X-DeepLearning | Docker+Yarn |
| 360 | XLearning | Yarn |
| 京东 | 登月平台 | Docker+Kubernetes |
| 才云科技 | Clever | Docker+Kubernetes |
表 1. 互联网业界机器学习平台架构对比
痛点
在建设分布式训练平台的过程中,我们和机器学习的各个业务方,包括搜索推荐、图像算法、交易风控反作弊等,进行了深入沟通,调研他们的痛点。从中我们发现,算法业务方往往专注于模型和调参,而工程领域是他们相对薄弱的一个环节。建设一个强大的分布式平台,整合各个资源池,提供统一的机器学习框架,将能大大加快训练速度,提升效率,带来更多的可能性,此外还有助于提升资源利用率。
痛点一:对算力的需求越来越强烈
算力代表了生产力。深度学习在多个领域的出色表现,给业务带来了更多的可能性,同时对算力提出了越来越高的要求。深度学习模型参数的规模陡增,迭代的时间变的更长,从之前的小时级别,变成天级别,甚至月级别。以商品推荐为例,面对几亿的参数,近百亿的样本数量,即使采用 GPU 机器,也需要长达一个星期的训练时间;而图像业务拥有更多的参数和更复杂的模型,面对 TB 级的训练样本,单机场景下往往需要长达近一个月的训练时间。
再者,机器学习具有试错性非常强的特点,更快的训练速度可以带来更多的尝试,从而发掘更多的可能性。Tensorflow 从 0.8 版本开始支持分布式训练,至今为止,无论高阶还是低阶的 API,对分布式训练已经有了完善的支持。同时,Kubernetes 和 Hadoop 等具有完善的资源管理和调度功能,为 Tensorflow 分布式训练奠定资源层面的基础。
Tensorflow On Yarn 和 Tensorflow On Spark 是较早的解决方案,奇虎 360 的 Xlearning 也得到众人的青睐。而基于 Kubernetes 的 kubeflow 解决了 Yarn 的痛点,展现出旺盛的生命力。
上述方案无一例外的将各个部门分散的机器纳入到统一的资源池,并提供资源管理和调度功能,让基于 Excel 表的资源管理和人肉调度成为过去,让用户更专注于算法模型,而非基础设施。在几十个 worker 下,无论是 CPU 还是 GPU 的分布式训练,训练速度都能得到近乎线性的提升,将单机的训练时间从月级别缩短到一天以内,提升效率的同时也大大提升了资源利用率。
蘑菇街早期的业务方往往独立维护各自团队的 GPU 机器“小池子”,机器的资源分配和管理存在盲区,缺乏统一管理和调度。GPU 的资源存在不均衡和资源利用率低下的问题。事实上,大数据团队之前已经将 CPU 类型的训练任务接入了 Xlearning,尝到了分布式训练的甜头,但也发现一些问题:
- 公司目前的 Yarn 不支持 GPU 资源管理,虽然近期版本已支持该特性,但存在稳定性风险。
- 缺乏资源隔离和限制,同节点的任务容易出现资源冲突。
- 监控信息不完善。在发生资源抢占时,往往无法定位根本原因。
- 缺少弹性能力,目前资源池是静态的,如果能借助公有云的弹性能力,在业务高峰期提供更大的算力,将能更快的满足业务需求。
痛点二:人肉管理的成本很高
业务方反馈的第二大问题是人肉管理的成本问题。人肉化的管理主要包含了部署和训练任务管理两大方面。
人肉部署
一个典型的场景是:团队内的成员共享一批机器,每次跑训练任务前,用户手动登陆机器,下载代码,安装对应的 python 包,过程繁琐且容易出现安装包版本的冲突。
由于不同的训练任务对 python 的版本和依赖完全不同,比如有些模型使用 python 2.7,有些使用 python 3.3,有些使用 tensorflow 1.8,有些使用 tensorflow 1.11 等等,非常容易出现依赖包冲突的问题。虽然沙箱能在一定程度上解决这问题,但是也带来了额外的管理负担。
此外,不同 GPU 机型依赖的 Nvidia 驱动也不同,较新的卡,比如 V100 所依赖的版本更高。人肉部署还需要管理和维护多个不同的驱动版本。
训练任务管理
人肉启动训练任务时,需要手动查看 / 评估资源的剩余可用情况,手动指定 PS 和 Worker 的数量,管理配置并进行服务发现。这些都给业务方带来了很大的负担。
解决的思路
Docker 和 Kubernetes 很好的解决了人肉管理的问题:
- 部署:借助 Docker 良好的隔离性,各个容器的文件系统互不影响,将训练任务和驱动程序制作成镜像,避免了多次安装的繁琐。此外 Kubernetes 提供了服务发现功能,简化了分布式的部署。
- 训练任务生命周期管理:Kubernetes 提供了生命周期管理的 API,用户基于 API 即可一键式完成训练任务的增删改查,避免人工 ssh 的各种繁琐操作,可以大幅提升用户体验和效率。
痛点三:监控的缺失
监控也是分布式训练重要的一环,它是性能调优的重要依据。比如在 PS-Worker 的训练框架下,我们需要为每个 PS/Worker 配置合适的 GPU/CPU/Memory,并设置合适的 PS 和 Worker 数量。如果某个参数配置不当,往往容易造成性能瓶颈,影响整体资源的利用率。比如当 PS 的网络很大时,我们需要增加 PS 节点,并对大参数进行 partition;当 worker CPU 负载过高时,我们应该增加 Worker 的核数。
早期版本的 Hadoop 和 Yarn 并不支持 GPU 的资源可视化监控,而 Kubernetes 已拥有非常成熟监控方案 Prometheus,它能周期采集 CPU,内存,网络和 GPU 的监控数据,即每个 PS/Worker 的资源使用率都能得到详细的展示,为优化资源配置提供了依据。事实上,我们也是通过监控信息为不同的训练任务分配合适的资源配置,使得在训练速度和整体的吞吐率上达到一个较好的效果。
痛点四:资源隔离较弱
早期的机器学习平台基于 Yarn 的 Angel 和 XLearning,由于 Yarn 缺乏对实例之间的资源隔离,我们在内存,网络,磁盘等均遇到不同程度的问题。
由于 Yarn 没有对任务的内存进行隔离,所以,业务方常常因对内存资源估计不准而导致 worker 的进程 OOM。由于所有的进程都共用宿主机的 IP,很容易造成端口冲突,此外磁盘 IO 和网络 IO 也很容易被打爆。
| Yarn | Kubernetes | |
|---|---|---|
| 调度 | 以任务为粒度进行调度 支持 Capacity Schedule、Fair Schedule 等多种调度器 抢占式调度,支持任务排队,支持基于 Tag 的调度 |
以 Pod 为粒度进行调度 Label/Selector 机制,支持多调度器 Kube-batch 支持抢占式调度 |
| 隔离性 | 隔离性偏弱,高版本支持 cgroup 磁盘和网络 IO 未隔离,多任务容易造成抢占 |
隔离性强 docker 可以使用独立 IP 底层通过Linux 内核的 cgroup/namespace 和 TC 等机制,保证磁盘和网络 IO 的隔离 |
| 多租户配额管理 | 通过队列机制实现多租户的配额管理 | 支持基于 namespace 的配额管理,包括 GPU 的配额 |
| 开源社区 | 活跃度相对低,Apache 基金会 | 活跃度相对高,CNCF 基金会 |
| 可扩展性 | 可扩展性好,可以支持其他 非 Yarn 的调度框架 | 可扩展性好,支持 CRD 和 operator,能满足内部业务的定制化需求 |
表 2. Hadoop Yarn 和 Kubernetes 的横向对比
Kubeflow 及核心组件
Kubeflow 是由 Google 等公司于 2017 年推出的基于 Kubernetes 的开源项目,它支持常见的机器学习框架。
Kubeflow 简介
The Kubeflow project is dedicated to making deployments of machine learning (ML) workflows on Kubernetes simple, portable and scalable.
Kubeflow 旨在支持多种机器学习框架运行在 Kubernetes 之上,比如 Tensorflow, Pytorch, Caffe 等常见框架。它包含了 operator、pipeline、超参数调优、serving 等诸多模块。它通过提供对应的 operator,基于 Kubernetes 的 Pod/headless Service 等基础资源为框架提供与之相配的更高层次的资源。比如 tf-operator 为 Tensorflow 提供了 job 维度的生命周期管理能力,以满足 Tensorflow 分布式训练的资源和拓扑需求,达到了一键式部署 Tensorflow 训练任务的效果。
Kubeflow 包含如下 operator,分别对应主流的分布式计算框架。蘑菇街主要采用了 kubeflow 中的 tf-operator,来实现对机器学习任务的统一管理。

图 1. Kubeflow 所支持的主流分布式计算框架
Distributed Tensorflow
蘑菇街业务方使用的计算框架主要是 Tensorflow,因此有必要先介绍一下 Tensorflow 的分布式训练,Tensorflow 支持如下三种分布式策略:
- MirroredStrategy:适用于单机多卡的训练场景,功能有限,不在本文讨论范围内。
- ParameterServerStrategy:用于多机多卡场景,主要分为 worker 节点和 PS 节点,其中模型参数全部存储在 PS 节点,worker 在每个 step 计算完梯度后向 PS 更新梯度,蘑菇街当前使用这种方案。
- CollectiveAllReduceStrategy:用于多机多卡场景,通过 all-reduce 的方式融合梯度,只需要 worker 节点,不需要 PS 节点,从另外一个角度说,该节点既充当 worker 角色,又充当 PS 角色。该方案是带宽优化的,具有性能好,可扩展性强的特点,是 Tensorflow 推荐的未来方向。
以 ParameterServerStrategy 为例,一个分布式训练集群至少需要两种类型的节点:PS 和 worker。由于在训练中需要一个 worker 节点来评估效果和保存 checkpoint,因此单独把该节点作为 chief(或者叫 master) 节点。通常情况下,一个集群需要多个 worker 节点,多个 PS 节点,一个 chief 节点。所有 worker 节点的 CPU/ 内存 /GPU 等资源配置完全相同,所有 PS 节点的 CPU/ 内存等资源配置也相同。从资源拓扑角度出发,如果能够提供一种 Kubernetes 资源,用户可以基于该资源定义 PS/worker/chief 的数量和规格,用户就可以一键式创建分布式集群,大大简化了分布式集群的部署和配置。tf-operator 定义了 TFJob 资源,用户可以借助 tf-operator 在 Kubernetes 上一键拉起分布式训练集群。
从 Tensorflow 分布式训练的使用方式出发,用户在启动每个节点的任务时,需要传入集群所有节点的网络信息。这意味着分布式训练集群的每个节点需要预先知道所有其它节点的网络地址信息,即要求服务发现功能。tf-operator 基于 Kubernetes headless service,完美的提供了服务发现功能,无需用户再手工指定 PS/Worker 的 IP 信息,极大的降低了用户的部署成本。
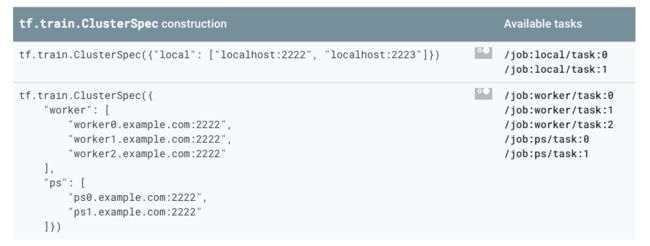
图 2. Tensorflow 分布式训练的 ClusterSpec 配置
落地实践
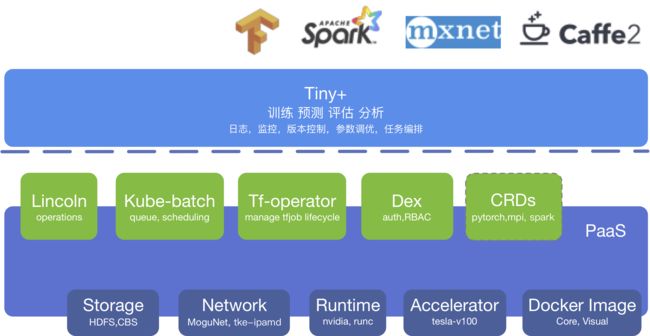
图 3. 基于 Kubernetes 的机器学习基础平台总体架构
主要包含了以下几部分:
Tensorflow 生命周期管理 (tf-operator)
在部署 tf-operator 之后,首先需要在 Kubernetes 中创建对应的 TFJob CRD,之后就可以创建 TFJob 资源了。
在如下的样例中,我们定义了一个具有 10 个 worker,4 个 ps,1 个 chief 的分布式训练集群。从 TFJob 参数不难发现,它对 ParameterServerStrategy 和 CollectiveAllReduceStrategy 这两种策略方式都支持,只是在 CollectiveAllReduceStrategy 场景下,无需要设置 PS 资源。
复制代码
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tf-operator 启动后,通过 list-watch 不断的监听 TFJob 资源相关事件,当收到创建 TFJob 事件时,tf-operator 依次创建 PS/Worker/Chief(Master) Replica 资源。以 PS Replica 为例,根据 replicas 数量依次创建等同数量的 pod,并为每个 pod 创建 headless service。此外,它还生成 TF_CONFIG 环境变量,这个环境变量记录了所有 pod 的域名和端口,最终在创建 pod 时候注入到容器中。

图 4. tf-operator 的配置示例
任务调度 (kube-batch)
通过引入 kube-batch,满足了业务方对批量任务调度的需求。没有采用 Kubernetes 默认的调度器,主要是基于以下两点考虑:
-
GANG scheduling:Kubernetes 默认的调度器是以 pod 为粒度的,并不支持 GANG scheduling。机器学习的训练任务要求集群保持一个整体,要么所有的 pod 都能成功创建,要么没有一个 pod 能被创建。试想资源处于临界状态时,如果采用默认的调度器调度一个分布式训练集群,则会导致部分节点因资源不足而无法成功调度,那些成功创建的 pod 空占用资源,但是无法进行训练。
-
任务排队:Kubernetes 默认的调度器无法提供队列调度的功能,而不会像 Hadoop 任务那样进行排队。而面向机器学习 / 大数据 /HPC 的批量任务调度,往往要求系统能维护一个或多个队列,进行任务排队。当任务结束并且释放资源后,后续的任务可以继续执行。
Kube-batch 目前是 Kubernetes SIGs 旗下的一个孵化项目,是一个运行在 Kubernetes 上面向机器学习 / 大数据 /HPC 的批调度器(batch scheduler),它支持以 Pod Group 为单位进行资源调度,并支持 preempt 和 priority。对于暂时无法满足资源条件的 Pod,在 Kubernetes 中会处于 pending 状态,直到资源释放从而继续执行。
Kube-batch 的基本流程如下图,它通过 list-watch 监听 Pod, Queue, PodGroup 和 Node 等资源,在本地维护一份集群资源的全局缓存,依次通过如下的策略(reclaim, allocate, preemption,predict) 完成资源的调度。
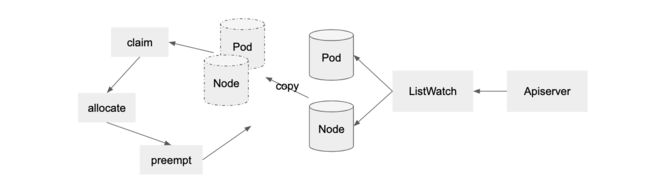
图 5. kube-batch 基本流程

图 6. kube-batch 工作流程
kube-batch 旨在通过配置策略,提供 gang scheduling 的调度能力,由于是基于 queue 的调度思想,kube-batch 对机器学习及大数据任务的调度具有很大的潜力。

图 7. 蘑菇街的使用姿势
由于 kube-batch 对任务的 actions 有四种,可以根据自身的业务特点,指定只使用其中的一种或者多种:如果简单的分配,使用 allocation 即可;如果资源存在碎片,让调度器能够感知并重新分配,可以将 allocation 与 backfill 结合起来使用。如此既可满足业务的调度需求,又可以在一定程度上提升调度性能。
认证和授权(Dex)
我们引入了由 CoreOS 研发的dex 组件,并嵌入到我们的 SDK 中,实现了与公司 LDAP 的对接。我们将 Kubernetes 中的 namespace 映射成不同的应用组,应用的负责人会自动授予(Rolebinding)管理员的角色(Role),同时针对一些特权用户还会创建 clusterRole 及 clusterRolebinding,方便这些特权用户访问某些需要高级权限的 API(如查询 node 信息等)。
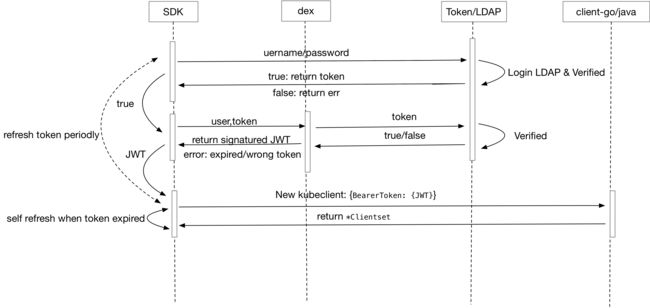
图 8. Dex 认证流程
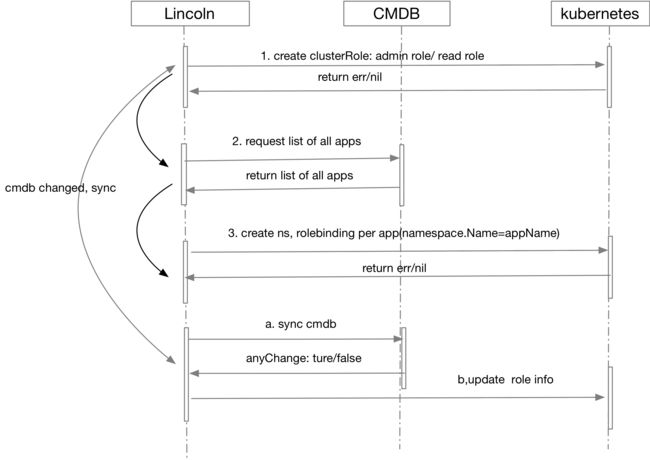
图 9. Dex 授权流程
多租户的隔离性
平台需要接入多个不同的业务方,自然需要考虑多租户间的隔离性。我们利用 Kubernetes 提供的 resource quota,以 namespace 为单位对资源进行分配。
复制代码
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
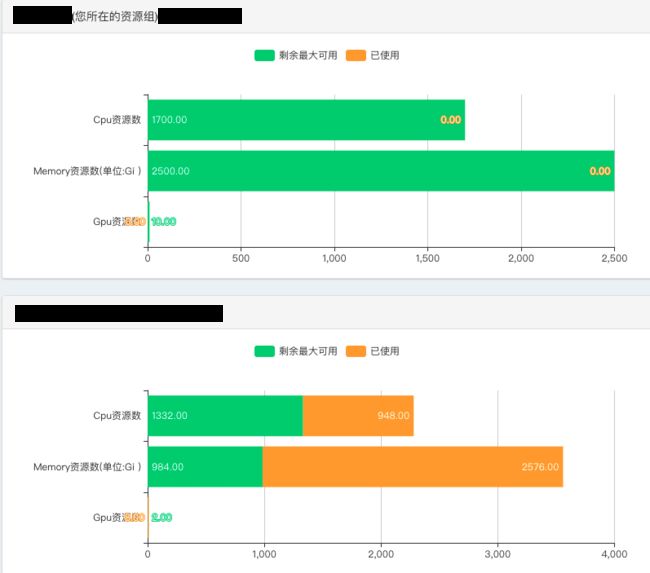
图 10. 多租户下的资源配额
性能调优
这里介绍一下蘑菇街在分布式机器学习调优的一些经验,主要分为 Kubernetes 层面、Tensorflow 层面和业务层面的一些调优。
Kubernetes 层面调优
CPUShare VS CPUSet
以商品推荐常用的 wide and deep 模型为例,该模型采用 CPU 资源进行训练,宿主机的规格为 80C256G。
从直觉上说,训练本质上是大量的矩阵运算,而矩阵运算在内存地址空间具有良好连续性的特点。若充分利用 CPU cache,将有助于提升 cache 的命中率,最终加快训练速度。Kubernetes 从 1.8 开始支持 CPU Manager 特性,该特性支持对于 Guaranteed 类型的 pod,采用 CpuSet 为 Pod 分配独占的 CPU core。在相同训练任务下,对比 CpuSet 和 CpuShare 对训练速度的影响,发现在 worker CPU 核数较少的情况下,CpuSet 的性能远远超过 CpuShare。

图 11. CpuSet 和 CpuShare 性能对比(Y 轴数值越大越好)
虽然 Guaranteed 类型的 Pod 牺牲了资源弹性,但是 CpuSet 带来的性能收益要高于弹性带来的收益。即使对 CpuShare 容器不设置 cpu limits,当跑满容器的 CPU 资源时,相同 cpu requests 下,CpuSet 容器的性能依旧比 CpuShare 的性能高出 20% 以上。
在 kubelet 中开启 CPU Manaer 特性的配置参数如下
复制代码
|
|
|
|
|
|
|
|
|
|
|
Pod Affinity
PS/Worker 训练框架下,PS 节点作为中心节点,网络流量往往非常大,容易把带宽跑满。通过 Pod AntiAffinity 将所有 PS 节点尽可能打散到不同的宿主机上,从而分摊网络流量。
复制代码
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
设置合适的资源配比
不同模型的计算量和参数各不相同,因此针对每个模型都应该设置一个合适的 PS/Worker 的规格和数量。在监控完善的条件下,可以根据监控数据分析瓶颈,调整实例的规格和数量,使得整体的训练速度和平台吞吐量能达到较好的水平。
Kube-batch 调度
由于 kube-batch 默认开启“reclaim, allocate, backfill, preempt”四种 actions,导致每次调度时轮询周期较长,通过配置 actions 为 allocate 一种可以提高 30% 的调度效率。
Tensorflow 层面调优
Tensorflow 的调优主要参考了官网文档。
线程数
由于 sysconf 系统调用等隔离性的问题,容器观察到的 CPU 信息往往是宿主机的。Tensorflow 默认的线程数为 CPU 核数,如此情况下,Tensorflow 创建的线程数远远超过实际分配到的 CPU 核数。同样以 wide and deep 模型为例,通过保持与 cpu limit
一致的线程数,上下文切换降低约 40%,训练速度提升约 5%。
复制代码
|
|
|
|
|
|
|
|
|
|
|
业务层面调优
Partition
在某次训练中发现 PS 流量节点的分布不均匀,其中某个 PS 节点的流量非常大,而其它 PS 节点的流量相对较低。通过分析 timeline.json 发现某个 embedding 向量非常大,所以通过 partition,将该 tensor 分散到不同的 PS 节点上,从而避免了某个 PS 节点成为瓶颈。

图 12. 通过 partition 将 tensor 打散到不同的 PS 节点
复制代码
|
|
|
|
|
|
|
|
|
Adam 优化器
由于 Adam 优化器会更新所有参数的梯度,所以在大 embedding 向量下,如果采用 adam 优化器,会大大增加计算量,严重影响训练速度。因此建议采用 Lazy_Adam_Optimizer 或者 Adadelta 优化器。
总结和体会
目前上述基于 Kubernetes 的机器学习平台已经在生产环境为多个业务方提供了服务。建设这套平台的过程,也是我们探索的过程。以下我们总结了一些还不尽如人意的地方,以及我们对未来的展望。
tf-operator
从落地的情况来看,tf-operator 的功能能满足基本的要求,稳定性较高。但是在故障恢复稍有欠缺,对于 pod 级别的故障,依赖 kubelet 来恢复;对于 node 级别的故障,目前还不支持故障恢复。分布训练下,故障概率随着 worker 数量和训练时间的增加而增加。worker 作为无状态节点,故障恢复既是可行的,也是非常有必要的。
kube-batch
目前 kube-batch 功能薄弱,成熟度有待商榷。比如 kube-batch 只有 predict 功能,没有 priority 功能。并且 predict 功能也非常薄弱,仅支持部分基础的 filter,比如 PodMatchNodeSelector, PodFitsHostPorts 以及基本的资源调度等。特别是 PodAffinity 特性,对于 PS-Worker 架构非常有用,因为 PS 节点的网络流量非常大,所以需要 PS 节点之间反亲和,将各个 PS 节点分散。此外,kube-batch 也不支持多任务之间依赖关系。
Kube-batch 的落地效果差强人意,社区的维护力度较低。除了功能薄弱以外,我们也碰上了诸多的问题,处于勉强可用状态。我们建议可将 pod 群维度的资源判断功能放到上层,只有当空闲资源满足创建整个分布式训练集群时,再将请求发送给 Kubernetes,由 Kubernetes 默认的调度器完成调度,当然,这种方式也存在一些缺点。
GPU 虚拟化
目前 GPU 相关的监控、隔离性以及更细粒度的调度,仍然是业界的痛点问题。Nvidia 提供的 GPU 虚拟化方案需要收取高额的 Lincense 费用,目前业界还没有免费的 GPU 虚拟化方案。
在实际的业务场景中,一些业务的 GPU 使用率并不高,但以虚拟机或者容器方式运行时往往会独占一块 GPU 卡,虽然可以通过设置 CUDA_VISIBLE_DEVICES 来实现多个容器共享一块 GPU 卡,但任务之间的隔离性是无法保证的。
另外,Kubernetes 进行 GPU 资源分配时,默认还不感知 GPU 的 Topology,而不同分配的策略,对训练的性能也会产生很大的影响。YARN和Kubernetes开源社区都在努力增强这块的调度能力。
Kubeflow 展望
Kubeflow 是目前基于 Kubernetes 的主流机器学习解决方案,它抽象了和机器学习相关的 PS-Worker 模型,实现了一套 pipeline 的工作流,支持超参数训练和 Jupyter notebooks 集成等能力。
由于 Kubeflow 解决了基于 Yarn 的机器学习平台的痛点,同时容器化越来越普及。基于 Kubernetes 这样大规模的企业级容器平台,将会是未来的方向,相信 Kubeflow 在 2019 年将会有更好的发展