Python3简单爬虫-通过Cookie模拟登陆并通过下载连接批量下载
Python的爬虫由于各种库的支持,在初级爬虫的方面十分方便。以下以批量下载网上文件为例,介绍一下在Python3中如何实现爬虫。(由于下载地址和链接属于私人东西,所以文章中仅介绍方法,不提供真实的下载链接和地址,请知悉)
- Cookie的简单介绍
- 如何获取当前的Cookie
- 详细实现过程
- 实现过程中遇到的问题
1.Cookie的简单介绍
“Cookie”是小量信息,由网络服务器发送出来以存储在网络浏览器上,从而下次这位独一无二的访客又回到该网络服务器时,可从该浏览器读回此信息。
个人粗略的理解是计算机上保存的用户信息, 不过这个用户信息是通过加密处理的。所以当我们拿到登陆网站的cookie后,没有必要对其内容进行解读,将整个cookie信息放入程序中就好。
2.如何获取当前的Cookie
以Chrome为例,在当前登陆的页面点击F12打开开发者模式,点击转换的Network页面,然后刷新页面,随便在下方的文件框中点击一个文件,在对应的右侧信息框中找到Cookie的内容。
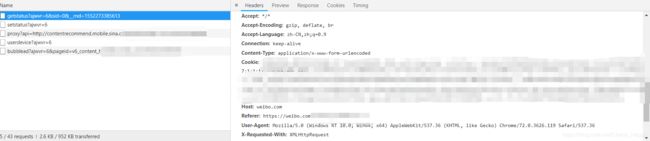
3.详细实现过程
在Python3中我们使用Urllib库中的Request来实现模拟登陆。首先在文件中导入用到的库
from urllib import request
import pandas as pd
之后配置模拟浏览器的一些信息,其中包括获取到的Cookie
cookie=‘’‘ ************************************************‘’‘
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36',
'Connection': 'keep-alive',
'accept': 'application/json, text/plain, */*',
'Cookie': cookie}
header就是一些浏览器信息,其中包括电脑的系统,浏览器的版本等,这些信息在查看cookie的那个页面上,在输入时可以按照页面信息输入。
一般下载链接在用户未登陆的情况下是无法下载,或者下载后是空的文件,所以就需要模拟登陆来获取下载的文件。
输入对应的下载链接,由于上面已经记录了cookie信息,这时要做的就是如何模拟登陆。
url='********************************'
wb = request.Request(url, headers=header)
f = request.urlopen(url=wb).read()
filename = 'tmp.xls'
open(filename, 'wb').write(f) # 在写文件时,要写成bytes类型的文件‘wb’
df_tmp = pd.read_excel('tmp.xls')
由于我在爬取的时候,下载的文件打开是bytes类型的文件,所以这里是使用临时文件tmp.xls作为中转,并通过pandas读取数据,然后做后续操作,如另存,上传数据库等等。
4.实现过程中遇到的问题
个人在实现过程中遇到的一些问题,分享出来以供大家参考
为什么不用Request库
对Python了解的童鞋肯定会问为什么是Urllib而不是Request,因为Request库中没有对下载链接文件的保存函数,由于下载下来的是bytes类型的文件,导致使用read()函数时,读出来的是乱码。在使用decode()函数时又会报错,报错原因查了半天半天资料也米有解决,所以放弃了。
为什么不适用Urllib.request.urlretrieve来保存文件?
由于需要使用urllib.request.request模拟登陆,urllib.request.urlretrieve无法读取request后的信息只能读取url,所以使用urllib.request.urlopen().read()和open().write()来写入文件,并且open的类型是’wb’
为什么使用pandas在中间做中转,而不是直接另存?
如果有需求直接另存到本地,可以将代码中的pandas去掉,直接使用循环对下载链接进行拼接,获得页面或者网站中的每个下载链接,然后对filename也进行循环,使用open().write()来另存文件,这里的filename需要使用绝对路径来写。而我的需求是上传到数据库中, 个人觉得pd.to_sql()比较好用,就使用了pandas做中转。
是不是每个网站都可以这么爬?
并不是,这要看网站的反爬策略的强弱了,如果是一些大网站的话,这种方法就显得过于简单。可以根据不同的网站情况修改对应的爬虫策略。
总结
以上就是使用Python3进行简单的爬虫,基于各个工具库使得简单爬虫很容易实现。以上只是基于下载做的示例,主要的问题其实是模拟登陆,在模拟登陆后,大家就可以举一反三的实现其他的需求。希望我的分享可以给大家带来帮助。