2019牛客暑期多校训练营(第六场)(A、B、C、D、E、G、J)
自己通过
A Garbage Classification(模拟*1)
垃圾分类,模拟题
#include
using namespace std;
const int N=2e3+5;
char s[N],t[26];
int T,len;
int num[3];
mapto;
int main()
{
to['d']=0;to['w']=1;to['h']=2;
scanf("%d",&T);
for(int cas=1;cas<=T;++cas)
{
scanf("%s%s",s,t);
for(int j=0;j<3;++j)
num[j]=0;
len=strlen(s);
for(int j=0;j=len)puts("Harmful");
else if(10*num[2]<=len)puts("Recyclable");
else
{
if(num[0]>=2*num[1])puts("Dry");
else puts("Wet");
}
}
return 0;
} 队友通过
B Shorten IPv6 Address(模拟*2)
将读入的128位01序列视为二进制IPv6地址,每4位一取将其变为16进制地址,
如0000:0000:0123:4567:89ab:0000:0000:0000,
忽略前导0之后,变为0:0:123:4567:89ab:0:0:0
特别地,两个及以上的连续0,可以缩写成::的形式,不能有三个冒号连续出现
要求如果能缩写,最短长度优先,最短长度一致时,字典序最小,输出最后的化简序列
前面部分先模拟,注意坑点在于连续0在中间缩写,会比在两端缩写少一个:
所以,最简单的方法,储存所有可能缩写连续0的位置,分别存其对应结果,排序取最小
#include
#define pb push_back
using namespace std;
int a[35],cnt;
char s[130];
vectorps;
string ans[130];
struct node{
vectorf;
bool rc;
int num;
}p[10];
bool cmp(string a,string b)
{
if(a.size()!=b.size())return a.size()>2]+=(1<<(3-j));
for(int i=0;i<32;i+=4){
int pos=-1;
for(int j=0;j<4;j++) if(a[i+j]!=0){
pos=j;
break;
}
if(pos==-1){
p[i>>2].f.pb(0);
p[i>>2].rc=1;
}else{
for(int j=pos;j<4;j++) p[i>>2].f.pb(a[i+j]);
}
}
int res=0,pos=-1;
for(int i=0;i<8;i++) if(p[i].rc){
for(int j=i+1;j<8;j++) if(p[j].rc) p[i].num++;
else break;
res=max(res,p[i].num);
}
ps.push_back(-1);
if(res!=0){
for(int i=0;i<8;i++) if(p[i].num==res) ps.push_back(i);
}
printf("Case #%d: ",ca++);
int len=ps.size();
for(int k=0;k=10) ans[k]+=('a'+it-10);
else ans[k]+=(it+'0');
}
}
sort(ans,ans+len,cmp);
printf("%s\n",ans[0].c_str());
}
}
D Move(枚举)
n(n<=1e3)个物品,第i个物品的体积为vi(1<=vi<=1e3),有K个盒子,
糖糖想要把n个物品放进K个盒子,他会一个一个地放盒子,每次挑出能放入这个盒子的最大体积的物品,
直至这个盒子不能放为止,才会跳到下一个盒子,问盒子的最小容量
注意到,这题没有二分的性质,如n=15,K=5
vi依次为39 39 39 39 39 60 60 60 60 60 100 100 100 100 100,则199可行,200和201均不可行
但是,注意到,盒子可行容量有上下界,下界L显然为![]() 向上取整,
向上取整,
而上界R,
• 假设某个答案 ans 装不下,那么每个箱子的剩余空间都 < maxV(最大浪费空间为maxV-1)
• 此时 k * (ans - (maxV-1) ) <= sum
• ans <= sum/k + maxV - 1
即最大装不下的盒子不可行容量为sum/k + maxV - 1 ,有R为![]()
[L,R]区间长度Vmax,1e3级别,check答案O(nlogn),故O(n*logn*Vmax)
注意multiset的写法,放置过程等价于,V倒序放物品,每次挑一个能放的最大的盒子放
#include
using namespace std;
const int N=1e3+5;
int t,n,k,l,r,v[N],sum,mx,ans;
multisetq;
bool ok(int x)
{
q.clear();
for(int i=1;i<=k;++i)
q.insert(x);
multiset::iterator it;
for(int i=1;i<=n;++i)
{
it=q.lower_bound(v[i]);
if(it==q.end())return 0;
int tmp=*it;
q.erase(it);//erase值是清掉所有相同值 erase指针只删一个
q.insert(tmp-v[i]);
}
return 1;
}
int main()
{
scanf("%d",&t);
for(int cas=1;cas<=t;++cas)
{
scanf("%d%d",&n,&k);
sum=mx=0;
for(int i=1;i<=n;++i)
{
scanf("%d",&v[i]);
sum+=v[i];
mx=max(mx,v[i]);
}
sort(v+1,v+n+1,greater());
l=(sum+k-1)/k;
r=l+mx;
for(int i=l;i<=r;++i)
{
if(ok(i))
{
ans=i;
break;
}
}
printf("Case #%d: %d\n",cas,ans);
}
return 0;
} G Is Today Friday?(模拟*3+蔡勒公式)
T(T<=10)组样例,每次给出n(n<=1e5)个形如CABJ/AI/AC的只有'A’到‘J’之间字母构成的日期,
要求,合理分配0-9的全排列,使其依次对应‘A’到'J’之间的字母,使得分配后,n个日期都合法
所谓合法,这里是指满足基本日期限制条件下,年在[1600,9999]间,且该天为星期五
可以先用两三个,把360W全排列里符合答案的几W预处理出来一部分,再跑后n个
但事实上,星期五的约束条件很严格,用蔡勒公式判,每次判几个就能把不合法的判掉,
所以枚举360W全排列,checkN个后break,也能过,玄学过题法……
如果输入为string格式,可以洗一下牌,random_shuffle(e+1,e+n+1),相信随机的力量
#include
#define zeller(y,m,d) ((d+1+2*m+3*(m+1)/5+y+y/4-y/100+y/400)%7) //返回5就是周5 0是周日
#define lp(y) (y%400==0 || (y%4==0 && y%100!=0))
using namespace std;
const int N=1e5+5;
int t,n,len,cnt;
int a[10],b[10],y,m,d;
int com[13]={0,31,28,31,30,31,30,31,31,30,31,30,31};
int leap[13]={0,31,29,31,30,31,30,31,31,30,31,30,31};
char s[15];
bool ok;
struct node
{
char s[10];
}e[N];
bool operator<(node a,node b)
{
return strcmp(a.s,b.s)<=0;
}
bool operator==(node a,node b)
{
return strcmp(a.s,b.s)==0;
}
int main()
{
scanf("%d",&t);
for(int cas=1;cas<=t;++cas)
{
ok=0;
scanf("%d",&n);
for(int i=0;i<10;++i)
a[i]=i;
for(int i=1;i<=n;++i)
{
scanf("%s",s);
len=strlen(s);
cnt=0;
for(int j=0;j9999||m<1||m>12||d<1||d>31){yes=0;break;}
if(lp(y))
{
if(d>leap[m]){yes=0;break;}
}
else
{
if(d>com[m]){yes=0;break;}
}
if(m==1||m==2)m+=12,y--;//1 2月当上一年的13 14月使用
if(zeller(y,m,d)!=5){yes=0;break;}//蔡勒公式
}
if(yes)
{
ok=1;
for(int i=0;i<10;++i)
b[i]=a[i];
break;
}
}while(next_permutation(a,a+10));
printf("Case #%d: ",cas);
if(!ok)puts("Impossible");
else
{
for(int i=0;i<10;++i)
printf("%d",b[i]);
puts("");
}
}
return 0;
} J Upgrading Technology(枚举)
给你一个n*m(1<=n,m<=1e3)的矩阵,第i行第j个元素为cij(-1e9<=cij<=1e9)
对于每一行,都可以选出从左端开始连续的一段,也可以不选,收益为-cij
对于第j列,如果第一行到第n行都选中了这一列的元素,则可以获得额外收益dj(-1e9<=dj<=1e9)
问,如何选择矩阵元素,使最终收益最大
这题赛中我提了一个假算法,枚举额外收益最右列,然后从右边再贪心取最小的负的前缀和
但这样,会被di是负很大的的情况卡掉,如以下样例,n=3,m=3,前三行为cij,最后一行为dj,
则应该选第一列的1 1 1,支付3,收益2;选第二列的-2 -3,支付-5;总收益为4,
而不能选第三行第二列的-1,获得额外收益-7,从而得出错误答案3
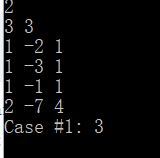
所以考虑枚举,a[i][j]代表第i行从1-j的前缀和,c[i][j]代表从j及右的位置取a[i][j],所能支付的最小值
每次仍枚举收益最右列j,但再枚举短板行i,这一行取a[i][j],剩下的行取c[i][j],即从j及右边的列里任取
具体实现,参考的几何旋律队的代码,不得不说,tql
#include
using namespace std;
typedef long long ll;
const int N=1e3+10;
int t,n,m;
ll a[N][N],c[N][N];
ll b[N];
ll res;
int main()
{
scanf("%d",&t);
for(int cas=1;cas<=t;++cas)
{
scanf("%d%d",&n,&m);
res=0;
for(int i=1;i<=n;++i)
{
for(int j=1;j<=m;++j)
{
scanf("%lld",&a[i][j]);
a[i][j]+=a[i][j-1];//行前缀和
}
}
for(int i=1;i<=n;++i)
{
c[i][m]=a[i][m];
for(int j=m-1;j>=0;--j)
{
c[i][j]=min(a[i][j],c[i][j+1]);//从j往右取 [1,j]一行和的最小
}
}
for(int i=1;i<=m;++i)
{
scanf("%lld",&b[i]);
b[i]=b[i-1]+b[i];
}
for(int i=0;i<=m;++i)//枚举必选列 [1,i]必选
{
ll s=0,t=1e18;
for(int j=1;j<=n;++j)
s+=c[j][i];
for(int j=1;j<=n;++j)//枚举短板行 t为最小花销
{
t=min(t,s-c[j][i]+a[j][i]);
res=max(res,b[i]-t);
}
}
printf("Case #%d: %lld\n",cas,res);
}
return 0;
} 补题
E Androgynos(自补图构造/图论同构)
T(T<=5)组样例,每次给出一个n(n<=2e3),问是否存在n的自补图,
自补图是指,原图G和其补图H同构,通俗讲,形状完全一致
若存在,输出G的邻接矩阵表示,及G在编号增序排列的情况下,H与其对应的编号序列
由于要原图补图边数各一半,即完全图边数为偶数,故只有n=4k或n=4k+1有解
注意到n=4时,1-2-3-4的解为2-4-1-3,则可以将原图和补图的对应点视为两个集合,
即用2-sat思想,12不同集,24不同集,31,43同理,故14同集,23同集
n=4k时,可以将一个集合的点全视为团,而另一个集合点视为独立集,团取反后为独立集,反之亦然
团1-独2-独3-团4,边取反后仍为团2-独4-独1-团3,
注意到集合A抽象出的一个点与集合B抽象出的一个点之间连边,等价于A内所有点向B内所有点分别连一条边
n=4k+1时,最后一个点,可以分别连向两个团,则在补图中,仍连向两个团
#include
using namespace std;
const int N=2e3+5;
int t,n,mp[N][N],f[N];
void solve(int n)
{
if(n%4>1)
{
puts("No");
return;
}
int k=n/4;
memset(mp,0,sizeof mp);
for(int i=1;i<=k;++i)//团 -> 独
{
for(int j=1;j<=k;++j)
{
if(i==j)continue;
mp[i][j]=mp[j][i]=1;
}
for(int j=k+1;j<=2*k;++j)
mp[i][j]=mp[j][i]=1;
}
for(int i=k+1;i<=2*k;++i)//独 -> 独
{
for(int j=2*k+1;j<=3*k;++j)
mp[i][j]=mp[j][i]=1;
}
for(int i=3*k+1;i<=4*k;++i)//独 -> 团
{
for(int j=3*k+1;j<=4*k;++j)
{
if(i==j)continue;
mp[i][j]=mp[j][i]=1;
}
for(int j=2*k+1;j<=3*k;++j)
mp[i][j]=mp[j][i]=1;
}
for(int i=1;i<=k;++i)//i= 1 2 3 4 对应 f[i]= 2 4 1 3
{
f[i]=i+k;
f[i+k]=i+3*k;
f[i+2*k]=i;
f[i+3*k]=i+2*k;
}
if(4*k+1==n)
{
for(int i=1;i<=k;++i)
mp[n][i]=mp[i][n]=1;
for(int i=3*k+1;i<=4*k;++i)
mp[n][i]=mp[i][n]=1;
f[n]=n;
}
puts("Yes");
for(int i=1;i<=n;++i)
{
for(int j=1;j<=n;++j)
printf("%d",mp[i][j]);
puts("");
}
for(int i=1;i<=n;++i)
printf("%d%c",f[i],i==n?'\n':' ');
}
int main()
{
scanf("%d",&t);
for(int cas=1;cas<=t;++cas)
{
scanf("%d",&n);
printf("Case #%d: ",cas);
solve(n);
}
return 0;
} C Palindrome Mouse(回文树)
T(T<=5)组样例,每次给定一个串s,|s|<=1e5,
设现在集合S是s的所有本质不同回文子串的集合,
从S中选出a、b两个串,求满足a是b的子串的对数(a,b)
做法相当神奇,也算是对回文树fail树进一步理解吧……
考虑fail的回溯过程,fail[u]一定是u的回文子串,
如果fail[v]=u,记to[u]=v的话
那么所有u的to,构成了u的回文串的可拓展集,
拓展,一方面可以通过前后各加一个字母,拓展到子树;
另一方面,可以通过从u跳到to[u]上,以最长后缀拓展到包含最长后缀的最短回文串上
那么,如果枚举节点u作(a,b)中的a,b应该是所有to[u]的子树包含的回文串的集合的并,
所以,dfs遍历回文树,记下每个节点的dfs序区间,
对节点u的to节点按长度从小到大排序,每次尽量取短的,
即靠近回文树根的son[u],加上这棵子树的贡献
这样如果已经取了son[u],且v是u的子树里的点,就不该取son[v]了
怎么按dfs序判断,u节点到根的路径上这一段的点没有被取呢,
差分BIT维护,枚举a使,每插入一个点,即对dfs序对应[L,R]区间+1,即差分单点+1-1,
如果[1,该点u的入序L[u]]的和为0,说明所有插入的点不是祖先节点(已经离开R了),或祖先的点尚未插入
每次统计完(a,)的答案之后,回滚BIT操作,BIT的作用在于对于固定的a,只统计靠根的子树,避免重复统计
学习了一个谓词的排序重载,sort(pa.son[i].begin(),pa.son[i].end(),[&](int a,int b){return pa.len[a] #include