Hadoop之一:Hadoop的安装部署
云计算(cloud computing)是基于互联网的相关服务的增加、使用和交付模式,通常涉及通过互联网来提供动态易扩展且经常是虚拟化的资源。云是网络、互联网的一种比喻说法。过去在图中往往用云来表示电信网,后来也用来表示互联网和底层基础设施的抽象。因此,云计算甚至可以让你体验每秒10万亿次的运算能力,拥有这么强大的计算能力可以模拟核爆炸、预测气候变化和市场发展趋势。用户通过电脑、笔记本、手机等方式接入数据中心,按自己的需求进行运算。对云计算的定义有多种说法。对于到底什么是云计算,至少可以找到100种解释。目前广为接受的是美国国家标准与技术研究院(NIST)定义:云计算是一种按使用量付费的模式,这种模式提供可用的、便捷的、按需的网络访问, 进入可配置的计算资源共享池(资源包括网络,服务器,存储,应用软件,服务),这些资源能够被快速提供,只需投入很少的管理工作,或与服务供应商进行很少的交互。(以上是照搬百度百科的,别吐槽啊!跪谢了……)。
说完了云计算,我们来说说Hadoop的概念吧,Hadoop是一个分布式的基础架构,由Apache基金会开发,Hadoop实现了一个分布式文件系统也就是后续文章会说到的HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上;而且它提供高传输率来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
好吧,太罗嗦了,写那么多概念大部分都是从百度百科里摘抄下来的,我厌烦了。下面来讲讲如何配置部署Hadoop环境,首先要说的是,目前Hadoop版本已经到2的版本了,但是很遗憾,我作为一个初学者,我还是比较喜欢一步一个脚印的学习,所以我们今天要讲的是Hadoop1的部署和配置,以后的篇章也是针对Hadoop1的版本来学习。
Hadoop可以装在很多的操作系统上,比如Windows上,Linux上,苹果的Mac OSX上。由于目前的常用的生产环境都是Linux操作系统,所以我们本章之讲在Linux操作系统下如何配置部署Hadoop。Hadoop部署方式有三种分别是单机模式、伪分布式模式和分布式模式。由于本人电脑配置有限,无法虚拟太多的Linux环境,所以我们今天暂时只讲伪分布式的部署方式。至于单机模式,本文章不讲述,后面的篇幅我会讲分布式模式的配置步骤。
准备环境:Ubuntu12、jdk-6u45-linux-i586.bin、hadoop-1.0.4.tar.gz(作为程序员来讲,这些大家都是可以在官网弄到手的,我就不给下载地址了……如果读者看到这里,也许会吐槽了,Hadoop不止这些啊,Hbase哪去了、Hive数据仓库哪里去了?这太扯了吧……呵呵,我想说的是,一步一步的来,会的大神么就别吐槽我了,我菜鸟一枚,以后的篇章我会一一写出来这些内容,我做好了持久战的准备……)
首先进入 Ubuntu操作系统,检查一下Ubuntu是否安装了java jdk。
好吧,进入我们的Ubuntu终端,输入java -version,看看是否已经安装的sun公司的jdk,如图:
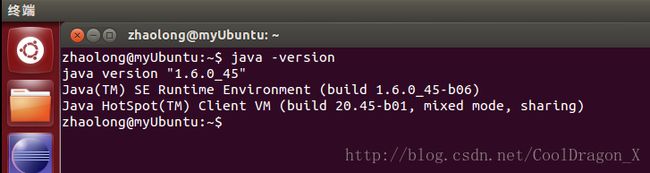
好吧,我这里是安装好的,没有安装jdk的同学,我继续说了。
将我们的jdk-6u45-linux-i586.bin文件考入到ubuntu的/home/zhaolong/下,好吧,我有一个这样的用户,你们按照你们的路径来吧。在Linux安装jdk其实就是一个文件解压的过程,安装前必须给当前这个文件进行授权。
cd命令进入我们jdk文件所在的目录,也就是/home/zhaolong/下,键入命令chmod 777 jdk-6u45-linux-i586.bin。
文件授权完毕之后,我们开始解压,使用./jdk-6u45-linux-i586.bin命令解压jdk文件。
解压完成之后,我们使用vi .bashrc命令进入到.bashrc文件编辑模式。我们要配置环境变量,在.bashrc文件的最后一行下面输入:
export JAVA_HOME=/home/zhaolong/jdk1.6.0_45 和 export PATH=/bin:$JAVA_HOME/bin:/usr/bin:$PATH:.
编辑完成后按ESC键然后输入:wq保存退出。使用. .bashrc命令使其生效。这时候我们再来用java -version来验证我们是否安装成功jdk了,不出意外应该会出现上图的内容。
接下来,我们来配置SSH的无密码登录,如果SSH有密码的话,每次启动每个节点都要重新输入密码,这是一件很麻烦的事情。
首先使用命令sudo apt-get install ssh安装ssh,安装的过程需要联网,下载有点慢,要有点耐心……
安装成功后,输入ssh-keygen命令,不用理会下面的内容,一路回车即可,结束后会在~/.ssh/目录下生成了两个文件:id_dsa和 id_rsa.pub,这两个文件是成对出现的类似钥匙和锁,再把id_dsa.pub文件复制到~/.ssh/目录的authorizde_keys里具体命令为:cp id_dsa.pub authorizde_keys
SSH我们安装配置好了,接着,我们安装Hadoop。将下载好的hadoop文件hadoop-1.0.4.tar.gz拷贝到/home/zhaolong/下。和安装JDK一样,我们要设置文件的权限,不然无法解压,设置hadoop-1.0.4.tar.gz文件的权限,命令为:chmod 777 hadoop-1.0.4.tar.gz
解压解压hadoop-1.0.4.tar.gz文件,命令为:tar xzvf hadoop-1.0.4.tar.gz
解压完成后,添加hadoop bin到环境变量中。具体操作依然是修改.bashrc文件最下面的$PATH环境变量。操作和上面的配置JDK的环境变量一样,我就不赘述了。
Hadoop环境变量配置好后,我们需要配置一些Hadoop的配置文件,我们需要进入到hadoop/conf目录下,
1、修改:hadoop-env.sh配置文件,文件内容增加
export JAVA_HOME=/home/zhaolong/jdk1.6.0_45
2、修改:core-site.xml配置文件,文件内容增加
3、修改:hdfs-site.xml配置文件,文件内容增加
4、修改:mapred-site.xml配置文件,文件内容增加
以上4步骤都配置完成后,我们需要启动一下Hadoop来验证我们的环境是否部署成功,启动前,必须先格式化文件系统,当然这个格式化文件系统只在第一次启动是进行,以后不需要重新格式化文件系统。格式化文件系统的命令为:hadoop namenode -format
文件系统格式化需要等待一段时间,不过不会很长,格式化完成之后,我们可以尝试着启动Hadoop了,为了方便我们start-all.sh命令启动所有的服务。
我们启动了所以的服务。
好吧大概说一下Hadoop启动和停止的常用命令,
(1)格式化文件系统,命令为:hadoop namenode -format
(2)启动关闭所有服务:start-all.sh/stop-all.sh
(3)启动关闭HDFS:start-dfs.sh/stop-dfs.sh
(4)启动关闭MapReduce:start-mapred.sh/stop-mapred.sh
(5)使用jps命令查看进程,确保有namenode,dataNode,JobTracker
(6)Job Tracker管理界面:http://localhost:50030
(7)HDFS管理界面:http://localhost:50070
(8)HDFS通信端口:9000
(9)MapReduce通信端口:9001
先写到这吧,夜深了,该睡觉了……写的比较笼统,先这样吧,晚安……