作者:张馨予
本文从数据传输和数据可靠性的角度出发,对比测试了Storm与Flink在流处理上的性能,并对测试结果进行分析,给出在使用Flink时提高性能的建议。

Apache Storm、Apache Spark和Apache Flink都是开源社区中非常活跃的分布式计算平台,在很多公司可能同时使用着其中两种甚至三种。对于实时计算来说,Storm与Flink的底层计算引擎是基于流的,本质上是一条一条的数据进行处理,且处理的模式是流水线模式,即所有的处理进程同时存在,数据在这些进程之间流动处理。而Spark是基于批量数据的处理,即一小批一小批的数据进行处理,且处理的逻辑在一批数据准备好之后才会进行计算。在本文中,我们把同样基于流处理的Storm和Flink拿来做对比测试分析。

在我们做测试之前,调研了一些已有的大数据平台性能测试报告,比如,雅虎的Streaming-benchmarks,或者Intel的HiBench等等。除此之外,还有很多的论文也从不同的角度对分布式计算平台进行了测试。虽然这些测试case各有不同的侧重点,但他们都用到了同样的两个指标,即吞吐和延迟。吞吐表示单位时间内所能处理的数据量,是可以通过增大并发来提高的。延迟代表处理一条数据所需要的时间,与吞吐量成反比关系。
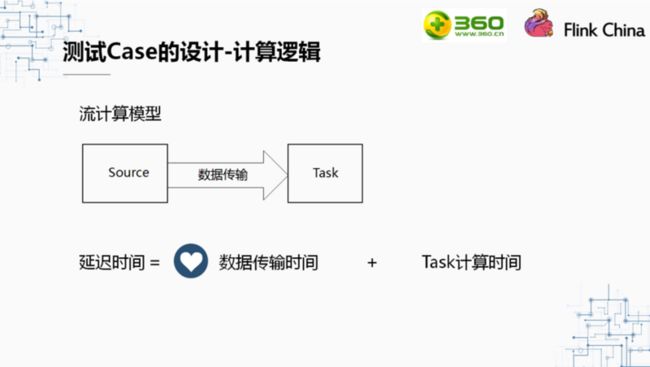
在我们设计计算逻辑时,首先考虑一下流处理的计算模型。上图是一个简单的流计算模型,在Source中将数据取出,发往下游Task,并在Task中进行处理,最后输出。对于这样的一个计算模型,延迟时间由三部分组成:数据传输时间、Task计算时间和数据排队时间。我们假设资源足够,数据不用排队。则延迟时间就只由数据传输时间和Task计算时间组成。而在Task中处理所需要的时间与用户的逻辑息息相关,所以对于一个计算平台来说,数据传输的时间才更能反映这个计算平台的能力。因此,我们在设计测试Case时,为了更好的体现出数据传输的能力,Task中没有设计任何计算逻辑。
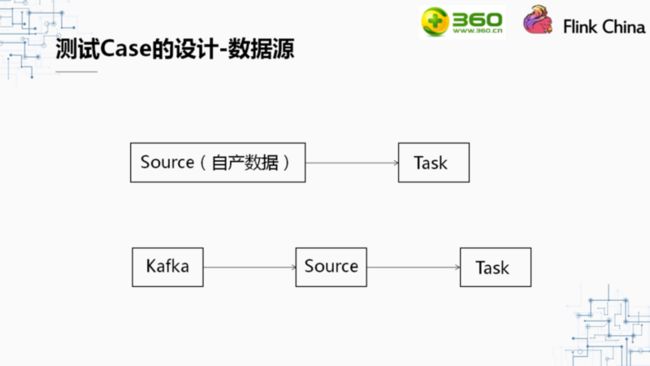
在确定数据源时,我们主要考虑是在进程中直接生成数据,这种方法在很多之前的测试标准中也同样有使用。这样做是因为数据的产生不会受到外界数据源系统的性能限制。但由于在我们公司内部大部分的实时计算数据都来源于kafka,所以我们增加了从kafka中读取数据的测试。

对于数据传输方式,可以分为两种:进程间的数据传输和进程内的数据传输。
进程间的数据传输是指这条数据会经过序列化、网络传输和反序列化三个步骤。在Flink中,2个处理逻辑分布在不同的TaskManager上,这两个处理逻辑之间的数据传输就可以叫做进程间的数据传输。Flink网络传输是采用的Netty技术。在Storm中,进程间的数据传输是worker之间的数据传输。早版本的storm网络传输使用的ZeroMQ,现在也改成了Netty。
进程内的数据传输是指两个处理逻辑在同一个进程中。在Flink中,这两个处理逻辑被Chain在了一起,在一个线程中通过方法调用传参的形式进程数据传输。在Storm中,两个处理逻辑变成了两个线程,通过一个共享的队列进行数据传输。

Storm和Flink都有各自的可靠性机制。在Storm中,使用ACK机制来保证数据的可靠性。而在Flink中是通过checkpoint机制来保证的,这是来源于chandy-lamport算法。
事实上exactly-once可靠性的保证跟处理的逻辑和结果输出的设计有关。比如结果要输出到kafka中,而输出到kafka的数据无法回滚,这就无法保证exactly-once。我们在测试的时候选用的at-least-once语义的可靠性和不保证可靠性两种策略进行测试。

上图是我们测试的环境和各个平台的版本。

上图展示的是Flink在自产数据的情况下,不同的传输方式和可靠性的吞吐量:在进程内+不可靠、进程内+可靠、进程间+不可靠、进程间+可靠。可以看到进程内的数据传输是进程间的数据传输的3.8倍。是否开启checkpoint机制对Flink的吞吐影响并不大。因此我们在使用Flink时,进来使用进程内的传输,也就是尽可能的让算子可以Chain起来。
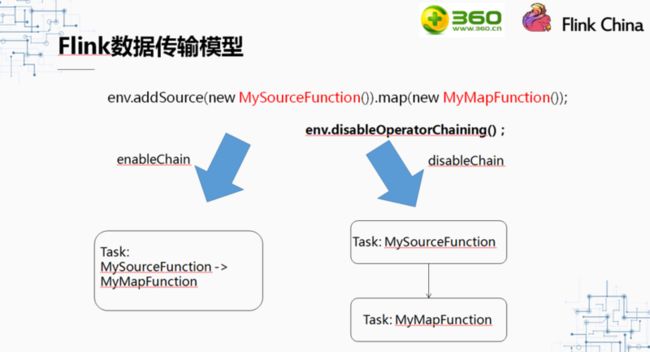
那么我们来看一下为什么Chain起来的性能好这么多,要如何在写Flink代码的过程中让Flink的算子Chain起来使用进程间的数据传输。
大家知道我们在Flink代码时一定会创建一个env,调用env的disableOperatorChainning()方法会使得所有的算子都无法chain起来。我们一般是在debug的时候回调用这个方法,方便调试问题。
如果允许Chain的情况下,上图中Source和mapFunction就会Chain起来,放在一个Task中计算。反之,如果不允许Chain,则会放到两个Task中。
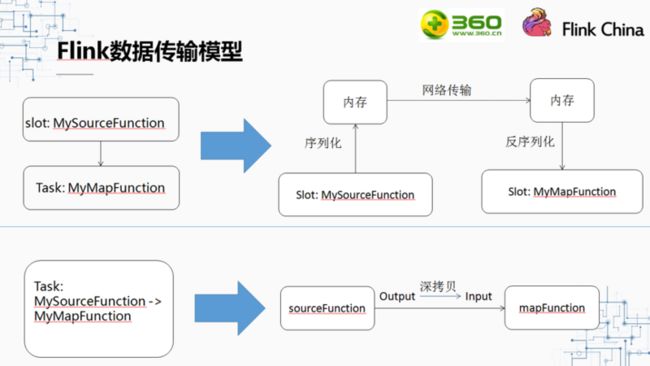
对于没有Chain起来的两个算子,他们被放到了不同的两个Task中,那么他们之间的数据传输是这样的:SourceFunction取到数据序列化后放入内存,然后通过网络传输给MapFunction所在的进程,该进程将数据方序列化后使用。
对于Chain起来的两个算子,他们被放到同一个Task中,那么这两个算子之间的数据传输则是:SourceFunction取到数据后,进行一次深拷贝,然后MapFunction把深拷贝出来的这个对象作为输入数据。
虽然Flink在序列化上做了很多优化,跟不用序列化和不用网络传输的进程内数据传输对比,性能还是差很多。所以我们尽可能的把算子Chain起来。
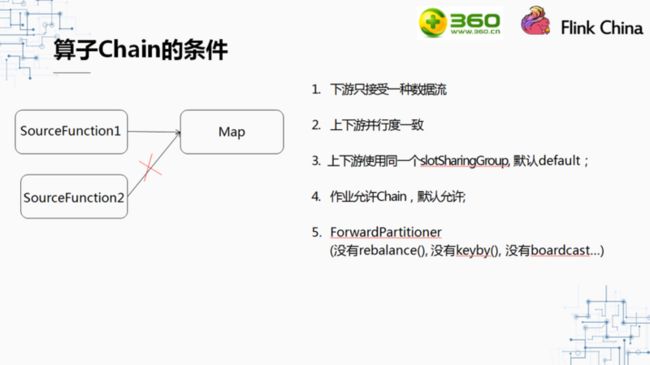
不是任何两个算子都可以Chain起来的,要把算子Chain起来有很多条件:第一,下游算子只能接受一种上游数据流,比如Map接受的流不能是一条union后的流;其次上下游的并发数一定要一样;第三,算子要使用同一个资源Group,默认是一致的,都是default;第四,就是之前说的env中不能调用disableOperatorChainning()方法,最后,上游发送数据的方法是Forward的,比如,开发时没有调用rebalance()方法,没有keyby(),没有boardcast等。
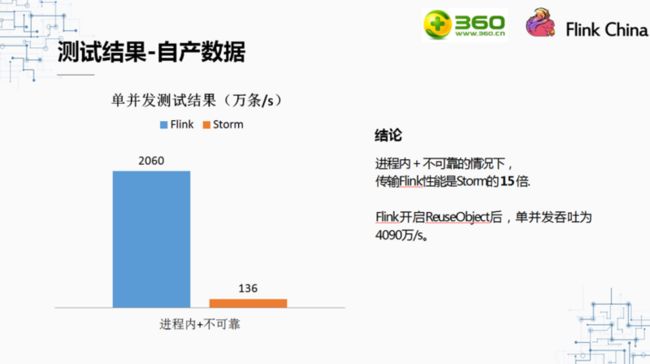
对比一下自产数据时,使用进程内通信,且不保证数据可靠性的情况下,Flink与Storm的吞吐。在这种情况下,Flink的性能是Storm的15倍。Flink吞吐能达到2060万条/s。不仅如此,如果在开发时调用了env.getConfig().enableObjectReuse()方法,Flink的但并发吞吐能达到4090万条/s。
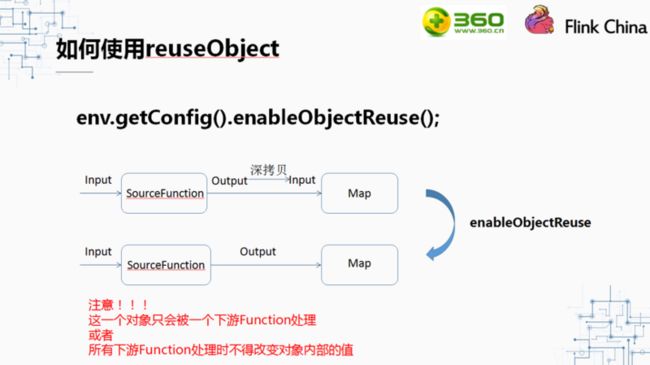
当调用了enableObjectReuse方法后,Flink会把中间深拷贝的步骤都省略掉,SourceFunction产生的数据直接作为MapFunction的输入。但需要特别注意的是,这个方法不能随便调用,必须要确保下游Function只有一种,或者下游的Function均不会改变对象内部的值。否则可能会有线程安全的问题。
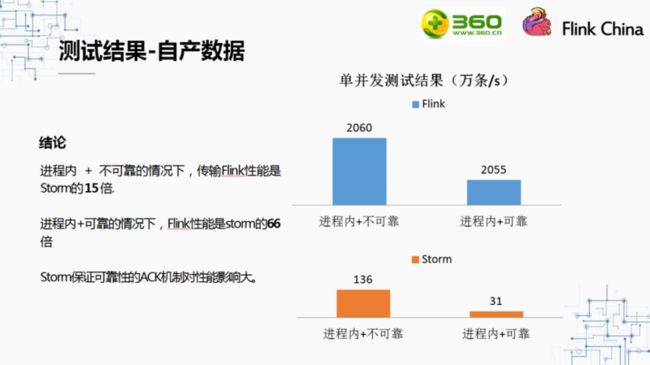
当对比在不同可靠性策略的情况下,Flink与Storm的表现时,我们发现,保证可靠性对Flink的影响非常小,但对Storm的影响非常大。总的来说,在保证可靠的情况下,Flink单并发的吞吐是Storm的15倍,而不保证可靠的情况下,Flink的性能是Storm的66倍。会产生这样的结果,主要是因为Flink与Storm保证数据可靠性的机制不同。
而Storm的ACK机制为了保证数据的可靠性,开销更大。
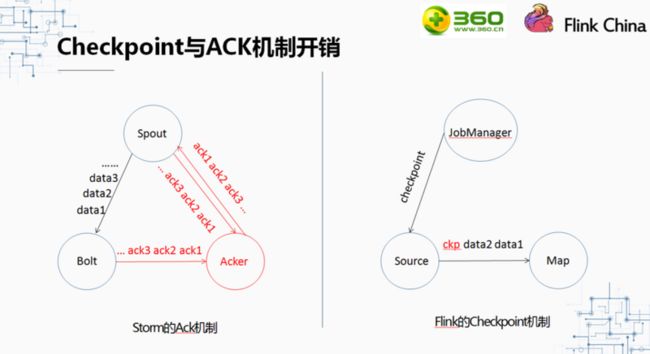
左边的图展示的是Storm的Ack机制。Spout每发送一条数据到Bolt,就会产生一条ack的信息给acker,当Bolt处理完这条数据后也会发送ack信息给acker。当acker收到这条数据的所有ack信息时,会回复Spout一条ack信息。也就是说,对于一个只有两级(spout+bolt)的拓扑来说,每发送一条数据,就会传输3条ack信息。这3条ack信息则是为了保证可靠性所需要的开销。
右边的图展示的是Flink的Checkpoint机制。Flink中Checkpoint信息的发起者是JobManager。它不像Storm中那样,每条信息都会有ack信息的开销,而且按时间来计算花销。用户可以设置做checkpoint的频率,比如10秒钟做一次checkpoint。每做一次checkpoint,花销只有从Source发往map的1条checkpoint信息(JobManager发出来的checkpoint信息走的是控制流,与数据流无关)。与storm相比,Flink的可靠性机制开销要低得多。这也就是为什么保证可靠性对Flink的性能影响较小,而storm的影响确很大的原因。
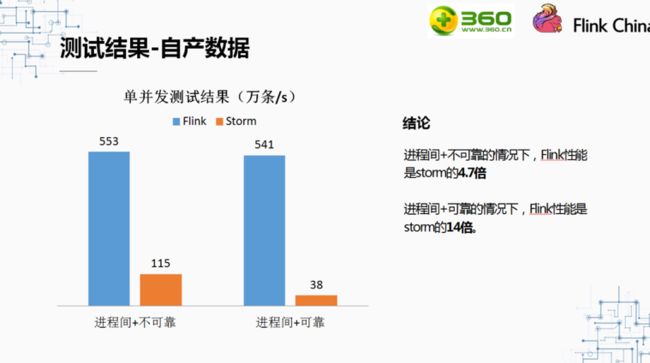
最后一组自产数据的测试结果对比是Flink与Storm在进程间的数据传输的对比,可以看到进程间数据传输的情况下,Flink但并发吞吐是Storm的4.7倍。保证可靠性的情况下,是Storm的14倍。
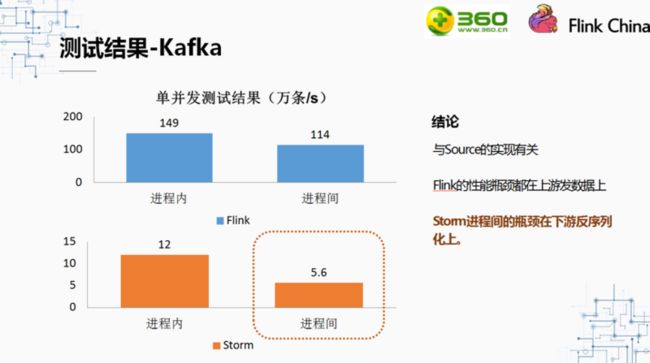
上图展示的是消费kafka中数据时,Storm与Flink的但并发吞吐情况。因为消费的是kafka中的数据,所以吞吐量肯定会收到kafka的影响。我们发现性能的瓶颈是在SourceFunction上,于是增加了topic的partition数和SourceFunction取数据线程的并发数,但是MapFunction的并发数仍然是1.在这种情况下,我们发现flink的瓶颈转移到上游往下游发数据的地方。而Storm的瓶颈确是在下游收数据反序列化的地方。
之前的性能分析使我们基于数据传输和数据可靠性的角度出发,单纯的对Flink与Storm计算平台本身进行了性能分析。但实际使用时,task是肯定有计算逻辑的,这就势必更多的涉及到CPU,内存等资源问题。我们将来打算做一个智能分析平台,对用户的作业进行性能分析。通过收集到的指标信息,分析出作业的瓶颈在哪,并给出优化建议。