Python常用库的安装
urllib、re 这两个库是Python的内置库,直接使用方法import导入即可。
在python中输入如下代码:
import urllib
import urllib.request
response=urllib.request.urlopen("http://www.baidu.com")
print(response)
返回结果为HTTPResponse的对象:
正则表达式模块
import re
该库为python自带的库,直接运行不报错,证明该库正确安装。
requests这个库是请求的库
我们需要使用执行文件pip3来进行安装。文件处于C:\Python36\Scripts下,我们可以先将此路径设为环境变量。在命令行中输入pip3 install requests进行安装。安装完成后进行验证
>>> import requests
>>> requests.get('http://www.baidu.com')
selenium实际上是用来浏览器的一个库
做爬虫时可能会碰到使用JS渲染的网页,使用requests来请求时,可能无法正常获取内容,我们使用selenium可以驱动浏览器获得渲染后的页面。也是使用pip3 install selenium安装。进行验证
>>> import selenium
>>> from selenium import webdriver
>>> driver = webdriver.Chrome()
DevTools listening on ws://127.0.0.1:60980/devtools/browser/7c2cf211-1a8e-41ea-8e4a-c97356c98910
>>> driver.get('http://www.baidu.com')
上述命令可以直接打开chrome浏览器,并且打开百度。但是,在这之前我们必须安装一个chromedriver,并且安装googlchrome浏览器,可自行去官网下载。当我们安装完毕后再运行这些测试代码可能依旧会出现一闪而退的情况,那么问题出在,chrome和chromdriver的版本不兼容,可以在官网下载chrome更高的版本,或者chromedriver更低的版本,但是只要都是最高版本就没问题。
如何查看本机的chrome的版本,具体方法如下:

chromedriver的下载地址如下:
http://chromedriver.storage.googleapis.com/index.html
chromedriver解压后放到Python或者其他配置了环境变量的目录下。
phantomjs是一个无界面浏览器,在后台运行
可在官网自行下载。并且需要将phantomjs.exe 的所在目录设为环境变量。测试代码
>>> from selenium import webdriver
>>> driver = webdriver.PhantomJS()
>>> driver.get('http://www.baidu.com')
>>> driver.page_source
'\n
lxml
使用pip3 install lxml安装
beautifulsoup是一个网络解析库,依赖于lxml库
使用pip3安装。必须安装pip3 install beautifulsoup4,因为beautifulsoup已经停止维护了。安装验证
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup('','lxml')
>>>
pyquery也是网页解析库
较bs4更加方便,语法和Jquery无异。也是使用pip3 安装
>>> from pyquery import PyQuery as pq #将其重命名
>>> doc = pq('')
>>> doc = pq('hello world')
>>> result = doc('html').text()
>>> result
'hello world'
pymysql是一个操作mysql数据库的库
使用pip3 安装
>>> import pymysql
>>> conn = pymysql.connect(host='localhost',user='root',password = '123456',port=3306,db='mysql')
>>> cursor = conn.cursor()
>>> cursor.execute('select * from db')
0
pymongo操作数据库MongoDB的库
需要开启MongoDB服务,在计算机管理当中的服务寻找。也是使用pip3安装
>>> import pymongo
>>> client = pymongo.MongoClient('localhost')
>>> db = client['newtestdb']
>>> db['table'].insert({'name':'tom'})
ObjectId('5b868ee4c4d17a0b2466f748')
>>> db['table'].find_one({'name':'tom'})
{'_id': ObjectId('5b868ee4c4d17a0b2466f748'), 'name': 'tom'}
>>> #完成了单条数据的查询
redis一个非关系型数据库,运行效率高
使用pip3 install redis安装
>>> import redis
>>> r = redis.Redis ('localhost',6379)
>>> r.set('name','tom')
True
>>> r.get('name')
b'tom'
>>> #是一个byte型数据类型
flask做代理时可能会用到
详细内容可以在flask官网查看flask文档
使用pip3 安装pip3 install flask
django是一个web服务器框架
提供了一个完整的后台管理,引擎、接口等,可以使用它做一个完整的网站。可在django的官网查看文档。使用pip3 install django安装
jupyter 可以理解为一个记事本
运行网页端,可以进行写代码,调试,运行。在官网可以下载jupyter,也可以用pip3 安装,相关库非常多,安装比较久。安装后可以在命令行直接运行jupyter notebook,因为此文件在scrips目录下。
C:\Users\dell>jupyter notebook
[I 20:32:37.552 NotebookApp] The port 8888 is already in use, trying another port.
[I 20:32:37.703 NotebookApp] Serving notebooks from local directory: C:\Users\dell
可以在选项 new 中建立新python3文件,并且可以编写代码。
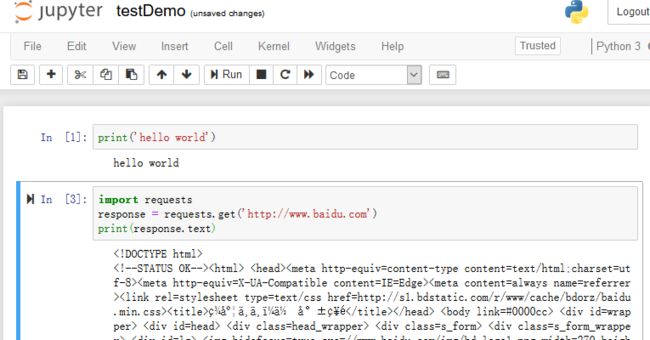
默认的文件名为unite,此处将其改为testDemo,使用快捷键ctrl+回车 运行,按键B跳转至新的编辑行。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对脚本之家的支持。如果你想了解更多相关内容请查看下面相关链接