spark支持standlone、yarn、mesos等多种运行模式,其中standlone模式主要用于线下环境的测试,线上都采用yarn或者mesos进行资源的管控、容错,这篇文章中介绍下spark在yarn-cluster的整个启动流程,重点介绍spark端的实现逻辑,关于yarn的一些细节我们会在其他的章节中进行介绍。
什么是yarn
yarn(Yet Another Resource Negotiator)是hadoop生态圈中用于资源管理、协调、任务隔离的框架,其他的计算编程模型可以基于yarn完成任务的调度执行;更多请查看yarn官网。

yarn的架构图
spark on yarn
消息流转图
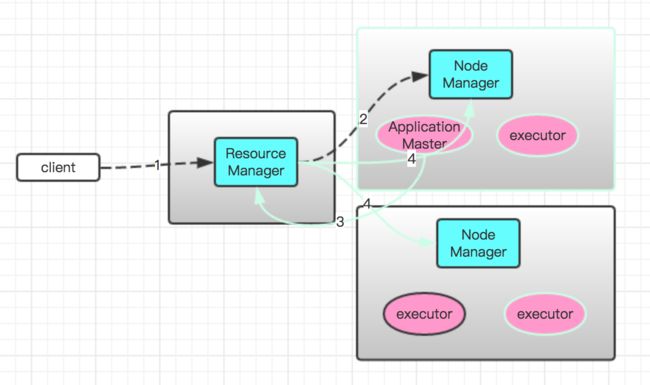
消息流转图
- client端向ResourceManager提交spark任务
- ResourceManager根据ApplicationManager请求的参数以及当前集群的运行状况将启动AM进程的请求发给相应的NodeManager
- NodeManager在本机上根据AM的启动命令拉起AM进程
- ApplicationManager向ResourceManager申请资源,同时将启动executor的ContainerRequest请求发送给ResourceManager;
- ResourceManger同样将拉起executor的请求发给相应的NodeManager,它根据executor的启动命令拉起executor进程
- executor进程向ApplicationManager中的DriverEndpoint注册自己,后续当ApplicationManger中有任务需要执行时,就会将任务的执行调度到注册成功的executor上;
类交互图

类交互图
- 设置环境变量
HADOOP_CONF_DIR或者YARN_CONF_DIR来指定yarn-site.xml和core-site.xml等hadoop和yarn的资源配置信息; - 执行命令行
sh bin/spark-submit --master yarn --depoly-mode cluster --files xxx --class xxx --jars xxx来向yarn提交spark应用程序; - 命令行最终转化为执行SparkSubmit.class的main函数,再依次执行参数的解析、校验、转换,最终再运行具体的类的main函数,在yarn模式中执行的类名为org.apache.spark.deploy.yarn.Client;
def main(args: Array[String]): Unit = {
val appArgs = new SparkSubmitArguments(args)
if (appArgs.verbose) {
// scalastyle:off println
printStream.println(appArgs)
// scalastyle:on println
}
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}
参数解析完毕后运行相应的childMainClass,yarn模式下为Client类的main方法。
private def submit(args: SparkSubmitArguments): Unit = {
val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args)
def doRunMain(): Unit = {
if (args.proxyUser != null) {
val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser,
UserGroupInformation.getCurrentUser())
try {
proxyUser.doAs(new PrivilegedExceptionAction[Unit]() {
override def run(): Unit = {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
})
} catch {
case e: Exception =>
// Hadoop's AuthorizationException suppresses the exception's stack trace, which
// makes the message printed to the output by the JVM not very helpful. Instead,
// detect exceptions with empty stack traces here, and treat them differently.
if (e.getStackTrace().length == 0) {
// scalastyle:off println
printStream.println(s"ERROR: ${e.getClass().getName()}: ${e.getMessage()}")
// scalastyle:on println
exitFn(1)
} else {
throw e
}
}
} else {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
}
- Client中首先向yarn申请一个ApplicationId,然后上传相应的文件、jar、配置参数等到hdfs上;然后提交应用到ResourceManager,如果spark.yarn.submit.waitAppCompletion设置为true,启动进程会一直获取应用的状态信息直到应用状态变为
FINISHED、KILLED、FAILED后退出;否则直接退出。
private def createContainerLaunchContext(newAppResponse: GetNewApplicationResponse)
: ContainerLaunchContext = {
logInfo("Setting up container launch context for our AM")
val appId = newAppResponse.getApplicationId
val appStagingDir = getAppStagingDir(appId)
val pySparkArchives =
if (sparkConf.getBoolean("spark.yarn.isPython", false)) {
findPySparkArchives()
} else {
Nil
}
val launchEnv = setupLaunchEnv(appStagingDir, pySparkArchives)
//上传spark.yarn.jar到/user/{user.home}/.sparkStaging/{applicationid}/__spark__.jar
//上传userjar到/user/{user.home}/.sparkStaging/{applicationid}/__app__.jar
//上传--jar中指定的jar到/user/{user.home}/.sparkStaging/{applicationid}/{#linkname}.jar
//上传--files中指定的文件到/user/{user.home}/.sparkStaging/{applicationid}/{#linkname}
//上传__spark_conf__.zip中指定的jar到/user/{user.home}/.sparkStaging/{applicationid}/__spark__conf__.zip,conf文件中包括HADOOP_CONF_DIR和YARN_CONF_DIR下面的所有文件以及由SparkConf生成的__spark_conf__.propertie文件
val localResources = prepareLocalResources(appStagingDir, pySparkArchives)
// Set the environment variables to be passed on to the executors.
distCacheMgr.setDistFilesEnv(launchEnv)
distCacheMgr.setDistArchivesEnv(launchEnv)
val amContainer = Records.newRecord(classOf[ContainerLaunchContext])
amContainer.setLocalResources(localResources.asJava)
amContainer.setEnvironment(launchEnv.asJava)
val javaOpts = ListBuffer[String]()
// Set the environment variable through a command prefix
// to append to the existing value of the variable
var prefixEnv: Option[String] = None
- 根据queue、am的启动命令、依赖的环境变量等信息初始化ApplicationSubmissionContext;
def createApplicationSubmissionContext(
newApp: YarnClientApplication,
containerContext: ContainerLaunchContext): ApplicationSubmissionContext = {
val appContext = newApp.getApplicationSubmissionContext
appContext.setApplicationName(args.appName)
appContext.setQueue(args.amQueue)
appContext.setAMContainerSpec(containerContext)
appContext.setApplicationType("SPARK")
sparkConf.getOption(CONF_SPARK_YARN_APPLICATION_TAGS)
.map(StringUtils.getTrimmedStringCollection(_))
.filter(!_.isEmpty())
.foreach { tagCollection =>
try {
// The setApplicationTags method was only introduced in Hadoop 2.4+, so we need to use
// reflection to set it, printing a warning if a tag was specified but the YARN version
// doesn't support it.
val method = appContext.getClass().getMethod(
"setApplicationTags", classOf[java.util.Set[String]])
method.invoke(appContext, new java.util.HashSet[String](tagCollection))
} catch {
case e: NoSuchMethodException =>
logWarning(s"Ignoring $CONF_SPARK_YARN_APPLICATION_TAGS because this version of " +
"YARN does not support it")
}
}
sparkConf.getOption("spark.yarn.maxAppAttempts").map(_.toInt) match {
case Some(v) => appContext.setMaxAppAttempts(v)
case None => logDebug("spark.yarn.maxAppAttempts is not set. " +
"Cluster's default value will be used.")
}
if (sparkConf.contains("spark.yarn.am.attemptFailuresValidityInterval")) {
try {
val interval = sparkConf.getTimeAsMs("spark.yarn.am.attemptFailuresValidityInterval")
val method = appContext.getClass().getMethod(
"setAttemptFailuresValidityInterval", classOf[Long])
method.invoke(appContext, interval: java.lang.Long)
} catch {
case e: NoSuchMethodException =>
logWarning("Ignoring spark.yarn.am.attemptFailuresValidityInterval because the version " +
"of YARN does not support it")
}
}
val capability = Records.newRecord(classOf[Resource])
capability.setMemory(args.amMemory + amMemoryOverhead)
capability.setVirtualCores(args.amCores)
if (sparkConf.contains("spark.yarn.am.nodeLabelExpression")) {
try {
val amRequest = Records.newRecord(classOf[ResourceRequest])
amRequest.setResourceName(ResourceRequest.ANY)
amRequest.setPriority(Priority.newInstance(0))
amRequest.setCapability(capability)
amRequest.setNumContainers(1)
val amLabelExpression = sparkConf.get("spark.yarn.am.nodeLabelExpression")
val method = amRequest.getClass.getMethod("setNodeLabelExpression", classOf[String])
method.invoke(amRequest, amLabelExpression)
val setResourceRequestMethod =
appContext.getClass.getMethod("setAMContainerResourceRequest", classOf[ResourceRequest])
setResourceRequestMethod.invoke(appContext, amRequest)
} catch {
case e: NoSuchMethodException =>
logWarning("Ignoring spark.yarn.am.nodeLabelExpression because the version " +
"of YARN does not support it")
appContext.setResource(capability)
}
} else {
appContext.setResource(capability)
}
appContext
}
- 提交应用上下文到ResourceManager的ClientRMService接口完成任务的提交;
ApplicationMaster启动
- NodeManager拉起ApplicationMaster,执行main函数,设置
amfilter,确保webui只能被指定的原ip访问,否则重定向到proxyurl; - 启动线程driver来运行
userclass的main函数,初始化相应的SparkContext,在主线程中向ResoureManager注册am,告知RM其sparkUI的地址
private def runDriver(securityMgr: SecurityManager): Unit = {
//添加AmIpFilter,控制sparkui只能从特定的ip访问,否则重定向到指定的url
addAmIpFilter()
//执行userclass的main 函数,开始运行用户定义的代码(sparksubmit命令中--class指定的类)
userClassThread = startUserApplication()
// This a bit hacky, but we need to wait until the spark.driver.port property has
// been set by the Thread executing the user class.
val sc = waitForSparkContextInitialized()
// If there is no SparkContext at this point, just fail the app.
if (sc == null) {
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_SC_NOT_INITED,
"Timed out waiting for SparkContext.")
} else {
rpcEnv = sc.env.rpcEnv
val driverRef = runAMEndpoint(
sc.getConf.get("spark.driver.host"),
sc.getConf.get("spark.driver.port"),
isClusterMode = true)
//向ResourceManager注册启动成功的AM,告知其ui的地址,程序退出后,在去注册的时候告知其history ui address
registerAM(rpcEnv, driverRef, sc.ui.map(_.appUIAddress).getOrElse(""), securityMgr)
//等待应用线程执行结束
userClassThread.join()
}
}
- 同时开启report线程,用于定期的向ResourceManager申请资源,主要逻辑在YarnAllocator中;同时监测executor失败的情况,当executor失败的次数超过spark.yarn.max.executor.failures指定的值时,停止AM;
//开启reporter线程监控程序的运行状态,同时定期的向RM申请资源
private def launchReporterThread(): Thread = {
// The number of failures in a row until Reporter thread give up
val reporterMaxFailures = sparkConf.getInt("spark.yarn.scheduler.reporterThread.maxFailures", 5)
val t = new Thread {
override def run() {
var failureCount = 0
while (!finished) {
try {
if (allocator.getNumExecutorsFailed >= maxNumExecutorFailures) {
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_MAX_EXECUTOR_FAILURES,
s"Max number of executor failures ($maxNumExecutorFailures) reached")
} else {
logDebug("Sending progress")
//触发资源的申请流程
allocator.allocateResources()
}
failureCount = 0
} catch {
case i: InterruptedException =>
case e: Throwable => {
failureCount += 1
if (!NonFatal(e) || failureCount >= reporterMaxFailures) {
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_REPORTER_FAILURE, "Exception was thrown " +
s"$failureCount time(s) from Reporter thread.")
} else {
logWarning(s"Reporter thread fails $failureCount time(s) in a row.", e)
}
}
}
try {
val numPendingAllocate = allocator.getPendingAllocate.size
allocatorLock.synchronized {
val sleepInterval =
if (numPendingAllocate > 0 || allocator.getNumPendingLossReasonRequests > 0) {
val currentAllocationInterval =
math.min(heartbeatInterval, nextAllocationInterval)
nextAllocationInterval = currentAllocationInterval * 2 // avoid overflow
currentAllocationInterval
} else {
nextAllocationInterval = initialAllocationInterval
heartbeatInterval
}
logDebug(s"Number of pending allocations is $numPendingAllocate. " +
s"Sleeping for $sleepInterval.")
allocatorLock.wait(sleepInterval)
}
} catch {
case e: InterruptedException =>
}
}
}
}
// setting to daemon status, though this is usually not a good idea.
t.setDaemon(true)
t.setName("Reporter")
t.start()
logInfo(s"Started progress reporter thread with (heartbeat : $heartbeatInterval, " +
s"initial allocation : $initialAllocationInterval) intervals")
t
- 如果未开启dynamic功能,系统一开始需要申请的executor个数由spark.executor.instances参数指定;开启dynamic allocate的话,最初的资源个数由参数spark.dynamicAllocation.initialExecutors指定
YarnAllocator
def allocateResources(): Unit = synchronized {
//根据需要申请的executor总数、已经成功申请和任务的位置获取需要申请的executor数目以及其地理位置信息
updateResourceRequests()
val progressIndicator = 0.1f
// Poll the ResourceManager. This doubles as a heartbeat if there are no pending container
// 获取AmClientImpl中处于pending和release状态的请求,组装成AllocateRequest,最终调用ApplicationMasterProtocol.allocate接口向RM申请资源
val allocateResponse = amClient.allocate(progressIndicator)
val allocatedContainers = allocateResponse.getAllocatedContainers()
if (allocatedContainers.size > 0) {
logDebug("Allocated containers: %d. Current executor count: %d. Cluster resources: %s."
.format(
allocatedContainers.size,
numExecutorsRunning,
allocateResponse.getAvailableResources))
handleAllocatedContainers(allocatedContainers.asScala)
}
def updateResourceRequests(): Unit = {
val pendingAllocate = getPendingAllocate
val numPendingAllocate = pendingAllocate.size
//计算出还需要申请多少container
val missing = targetNumExecutors - numPendingAllocate - numExecutorsRunning
if (missing > 0) {
logInfo(s"Will request $missing executor containers, each with ${resource.getVirtualCores} " +
s"cores and ${resource.getMemory} MB memory including $memoryOverhead MB overhead")
// Split the pending container request into three groups: locality matched list, locality
// unmatched list and non-locality list. Take the locality matched container request into
// consideration of container placement, treat as allocated containers.
// For locality unmatched and locality free container requests, cancel these container
// requests, since required locality preference has been changed, recalculating using
// container placement strategy.
val (localityMatched, localityUnMatched, localityFree) = splitPendingAllocationsByLocality(
hostToLocalTaskCounts, pendingAllocate)
// Remove the outdated container request and recalculate the requested container number
localityUnMatched.foreach(amClient.removeContainerRequest)
localityFree.foreach(amClient.removeContainerRequest)
val updatedNumContainer = missing + localityUnMatched.size + localityFree.size
//计算出container的位置信息,比如分布到哪些host或者rack
val containerLocalityPreferences = containerPlacementStrategy.localityOfRequestedContainers(
updatedNumContainer, numLocalityAwareTasks, hostToLocalTaskCounts,
allocatedHostToContainersMap, localityMatched)
for (locality <- containerLocalityPreferences) {
val request = createContainerRequest(resource, locality.nodes, locality.racks)
//只是简单存储到本地的全局的map中,待后续真正申请才向rm发送申请命令
amClient.addContainerRequest(request)
val nodes = request.getNodes
val hostStr = if (nodes == null || nodes.isEmpty) "Any" else nodes.asScala.last
logInfo(s"Container request (host: $hostStr, capability: $resource)")
}
} else if (missing < 0) {
val numToCancel = math.min(numPendingAllocate, -missing)
logInfo(s"Canceling requests for $numToCancel executor containers")
val matchingRequests = amClient.getMatchingRequests(RM_REQUEST_PRIORITY, ANY_HOST, resource)
if (!matchingRequests.isEmpty) {
matchingRequests.iterator().next().asScala
.take(numToCancel).foreach(amClient.removeContainerRequest)
} else {
logWarning("Expected to find pending requests, but found none.")
}
}
}
- 其余运行过程中executor故障退出后,会由YarnSchedulerBackend向YarnAllocator设置需要申请的总数,触发节点的补充。
资源的弹性伸缩
spark on yarn运行用户开启弹性伸缩策略,系统将根据当前的负载来决定增加或者移除相应的executor,负载是根据正在运行以及待运行的任务数来决定需要的executor数目;详情可以参考类ExecutorAllocationManager。
private def maxNumExecutorsNeeded(): Int = {
val numRunningOrPendingTasks = listener.totalPendingTasks + listener.totalRunningTasks
//tasksPerExecutor是executor的核数
(numRunningOrPendingTasks + tasksPerExecutor - 1) / tasksPerExecutor
}
动态伸缩的策略
- 扩容策略: 当积压的task的持续时间超过一定的阈值时,开始进行executor的增加,增加的方式类似于tcp的慢启动算法,指数级增加
- 缩容策略:当executor空闲的时间超过一定的阈值时,进行资源的释放
参数详解
| 参数值 | 参数说明 |
|---|---|
| spark.dynamicAllocation.minExecutors | 最小的executor的数量 |
| spark.dynamicAllocation.maxExecutors | 最大的executor的数量 |
| spark.dynamicAllocation.enabled | 是否开启动态分配策略,前提是spark.executor.instances为0 |
| spark.executor.instances | 设置executor的个数 |
| spark.dynamicAllocation.initialExecutors | 初次申请executor个数 |
| spark.dynamicAllocation.schedulerBacklogTimeout | 开始扩容的阈值 |
| spark.dynamicAllocation.sustainedSchedulerBacklogTimeout | 超过schedulerBacklogTimeout阈值后,再次扩容的时间 |
| spark.dynamicAllocation.executorIdleTimeout | executor空闲时间,超过改值,移除掉executor |
| spark.dynamicAllocation.cachedExecutorIdleTimeout | 有缓存block的executor的超时时间 |