一、iOS应用数据存储的常用方式:
1> XML属性列表(plist)归档
2> Preference(偏好设置)
3> NSKeyedArchiver归档(NSCoding)
4> SQLite3
5> Core Data
二、应用沙盒
1、每个iOS应用都有自己的应用沙盒(应用沙盒就是文件系统目录),与其他文件系统隔离。应用必须待在自己的沙盒里,其他应用不能访问该沙盒
2、应用沙盒的文件系统目录,如下图所示(假设应用的名称叫Layer)

3、模拟器应用的沙盒根路径在:(apple是用户名,8.0是模拟器版本)
/User/apple/Library/Application Soupport/iPhone Simulator/8.0/Applications
三、应用沙盒结构分析:
(1)应用程序包:(上图中的Layer)包含了所有的资源文件和可执行文件。
(2)Documents:保存应用运行时生成的 需要持久化的数据 ,iTunes同步设备时 会备份 该目录。例如:游戏应用可将游戏存档保存在该目录。
(3)tmp:保存应用运行时所需的 临时数据 ,使用完毕后再将相应的文件从该目录删除。应用没有运行时,系统也可能会清除该目录下的文件。iTunes同步设备时 不会备份 该目录。
(4)Library:下面有两个文件夹(Caches 、Preference)
Library / Caches:保存应用运行时生成的 需要持久化的数据,iTunes同步设备时 不会备份 该目录。一般存储体积大、不需要备份的非重要数据。
Library / Preference:保存应用的所有 偏好设置,iOS的Settings(设置)应用会在该目录中查找应用的设置信息。iTunes同步设备时 会备份 该目录。
四、应用沙盒目录的常见获取方式
1、沙盒根目录:NSString*home =NSHomeDirectory();
2、Documents:(2种方式)
2.1 利用沙盒根目录拼接”Documents”字符串
NSString *home = NSHomeDirectory();
NSString *documents = [home stringByAppendingPathComponent:@"Documents"];
//不建议采用,因为新版本的操作系统可能会修改目录名
2.2 利用NSSearchPathForDirectoriesInDomains函数
// NSUserDomainMask 代表从用户文件夹下找
// YES 代表展开路径中的波浪字符“~”
NSArray*array = NSSearchPathForDirectoriesInDomains(NSDocumentDirectory,NSUserDomainMask, NO);
// 在iOS中,只有一个目录跟传入的参数匹配,所以这个集合里面只有一个元素
NSString *documents = [array objectAtIndex:0];
3、tmp:NSString*tmp = NSTemporaryDirectory();
4、Library/Caches:(跟Documents类似的2种方法);
4-1、利用沙盒根目录拼接”Caches”字符串
4-2、利用NSSearchPathForDirectoriesInDomains函数(将函数的第2个参数改为:NSCachesDirectory即可);
5、Library/Preference:通过NSUserDefaults类存取该目录下的设置信息。
五、属性列表:Plist文件 ---- 存储数据
1、属性列表是一种XML格式的文件,拓展名为plist
2、如果对象是NSString、NSDictionary、NSArray、NSData、NSNumber等类型,就可以使用writeToFile:atomically:方法直接将对象写到属性列表文件中
5-1、属性列表 --- 归档NSDictionary
a、将一个NSDictionary对象归档到一个plist属性列表中
// 将数据封装成字典
NSMutableDictionary *dict = [NSMutableDictionary dictionary];
[dict setObject:@"母鸡" forKey:@"name"];
[dict setObject:@"15013141314" forKey:@"phone"];
[dict setObject:@"27" forKey:@"age"];
// 将字典持久化到Documents/stu.plist文件中
[dict writeToFile:path atomically:YES];
b、成功写入到Documents目录下:如图 -- b
b-1、用文本编辑器打开,文件内容为:如图 b -- 1

b-2、用xcode打开属性文件(Plist文件打开):如图 b -- 2

5-2、属性列表 --- 恢复NSDictionary
a、读取属性列表,恢复NSDictionary对象
// 读取Documents/stu.plist的内容,实例化NSDictionary
NSDictionary *dict = [NSDictionary dictionaryWithContentsOfFile:path];
NSLog(@"name:%@", [dict objectForKey:@"name"]);
NSLog(@"phone:%@", [dict objectForKey:@"phone"]);
NSLog(@"age:%@", [dict objectForKey:@"age"]);
打印Log如下图5--2--a:

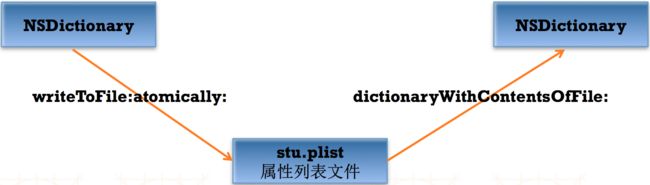
b、属性列表-NSDictionary的存储和读取过程.
如图5--2--b所示:
六、偏好设置 --- 存储数据
1、很多iOS应用都支持偏好设置,比如保存用户名、密码、字体大小等设置,iOS提供了一套标准的解决方案来为应用加入偏好设置功能.
2、每个应用都有个NSUserDefaults实例,通过它来存取偏好设置.
3、比如 : 保存用户名、字体大小、是否自动登录.
4、创建 NSUserDefaults
4-1、写入数据:图3-1、 图3-2
NSUserDefaults *defaults = [NSUserDefaults standardUserDefaults];
[defaults setObject:@"itcast" forKey:@"username"];
[defaults setFloat:18.0f forKey:@"text_size"];
[defaults setBool:YES forKey:@"auto_login"];

4-2、读取上次保存的设置
NSUserDefaults *defaults = [NSUserDefaults standardUserDefaults];
NSString *username = [defaults stringForKey:@"username"];
float textSize = [defaults floatForKey:@"text_size"];
BOOL autoLogin = [defaults boolForKey:@"auto_login"];
4-3、注意:UserDefaults设置数据时,不是立即写入,而是根据时间戳定时地把缓存中的数据写入本地磁盘。所以调用了set方法之后数据有可能还没有写入磁盘应用程序就终止了。出现以上问题,可以通过调用synchornize方法强制写入
[defaults synchornize];
七、NSKeyedArchiver
1.如果对象是NSString、NSDictionary、NSArray、NSData、NSNumber等类型,可以直接用NSKeyedArchiver进行归档和恢复。
2.不是所有的对象都可以直接用这种方法进行归档,只有遵守了NSCoding协议的对象才可以。
3.NSCoding协议有2个方法:
a、encodeWithCoder:
每次归档对象时,都会调用这个方法。一般在这个方法里面指定如何归档对象中的每个实例变量,可以使用encodeObject:forKey:方法归档实例变量。
b、initWithCoder:
每次从文件中恢复(解码)对象时,都会调用这个方法。一般在这个方法里面指定如何解码文件中的数据为对象的实例变量,可以使用decodeObject:forKey方法解码实例变量。
7.1、NSKeyedArchiver --- 归档NSArray
• 归档一个 NSArray 对象到 Documents/array.archive
NSArray *array = [NSArray arrayWithObjects:@”a”,@”b”,nil];
[NSKeyedArchiver archiveRootObject: array toFile:path];
• 归档成功:如图 7-1

• 恢复(解码)NSArray对象.如图 7-2
NSArray *array = [NSKeyedUnarchiver unarchiveObjectWithFile:path];

7.2 NSKeyedArchiver --- 归档Person对象
Person.h 文件
@interface Person : NSObject
@property (nonatomic, copy) NSString *name;
@property (nonatomic, assign) int age;
@property (nonatomic, assign)
float height;
@end
Person.m 文件
@implementation Person
- (void)encodeWithCoder:(NSCoder *)encoder {
[encoderencodeObject:self.nameforKey:@"name"];
[encoderencodeInt:self.ageforKey:@"age"];
[encoderencodeFloat:self.heightforKey:@"height"];
}
- (id)initWithCoder:(NSCoder *)decoder {
self.name= [decoderdecodeObjectForKey:@"name"];
self.age= [decoderdecodeIntForKey:@"age"];
self.height= [decoderdecodeFloatForKey:@"height"];
return self;
}
- (void)dealloc {
[superdealloc];
[_name release];
}
@end
NSKeyedArchiver-归档Person对象(编码和解码)
归档(编码)
Person *person = [[[Person alloc] init] autorelease];
person.name = @"MJ";
person.age = 27;
person.height = 1.83f;
[NSKeyedArchiver archiveRootObject:person toFile:path];
恢复(解码)
Person *person = [NSKeyedUnarchiver unarchiveObjectWithFile:path];
NSKeyedArchiver-归档对象的注意
1.如果父类也遵守了NSCoding协议,请注意:
1-1、应该在encodeWithCoder:方法中加上一句
[super encodeWithCode:encode];
确保继承的实例变量也能被编码,即也能被归档。
1-2、应该在initWithCoder:方法中加上一句
self = [super initWithCoder:decoder];
确保继承的实例变量也能被解码,即也能被恢复。
7.3 NSData 图 7-3
1、使用archiveRootObject:toFile:方法可以将一个对象直接写入到一个文件中,但有时候可能想将多个对象写入到同一个文件中,那么就要使用NSData来进行归档对象。
2、NSData可以为一些数据提供临时存储空间,以便随后写入文件,或者存放从磁盘读取的文件内容。可以使用[NSMutableData data]创建可变数据空间。

7.3-1 NSData-归档2个Person对象到同一文件中
归档(编码)
//新建一块可变数据区
NSMutableData *data = [NSMutableData data];
//将数据区连接到一个NSKeyedArchiver对象
NSKeyedArchiver *archiver = [[[NSKeyedArchiver alloc] initForWritingWithMutableData:data] autorelease];
//开始存档对象,存档的数据都会存储到NSMutableData中
[archiver encodeObject:person1 forKey:@"person1"];
[archiver encodeObject:person2 forKey:@"person2"];
//存档完毕(一定要调用这个方法)
[archiver finishEncoding];
//将存档的数据写入文件
[data writeToFile:path atomically:YES];
7.3-2 NSData-从同一文件中恢复2个Person对象
恢复(解码)
// 从文件中读取数据
NSData *data = [NSData dataWithContentsOfFile:path];
// 根据数据,解析成一个NSKeyedUnarchiver对象
NSKeyedUnarchiver *unarchiver = [[NSKeyedUnarchiver alloc] initForReadingWithData:data];
Person *person1 = [unarchiver decodeObjectForKey:@"person1"];
Person *person2 = [unarchiver decodeObjectForKey:@"person2"];
// 恢复完毕
[unarchiver finishDecoding];
7.4 利用归档实现深复制 。图7-4
比如对一个Person对象进行深复制
//临时存储person1的数据
NSData *data = [NSKeyedArchiver archivedDataWithRootObject:person1];
//解析data,生成一个新的Person对象
Student*person2 = [NSKeyedUnarchiver unarchiveObjectWithData:data];
// 分别打印内存地址
NSLog(@"person1:0x%x",person1); // person1:0x7177a60
NSLog(@"person2:0x%x",person2); // person2:0x7177cf0
八、SQLite
1、什么是SQLite?
SQLite是一款轻型的嵌入式数据库
它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了
它的处理速度比Mysql、PostgreSQL这两款著名的数据库都还快
2、什么是数据库?
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库
数据库可以分为2大种类
✔️关系型数据库( 主流 )
✔️对象型数据库
3、常用关系型数据库
PC端:Oracle、MySQL、SQLServer、Access、DB2、Sybase
嵌入式\移动客户端:SQLite
4、如何存储数据?
4.1、数据库是如何存储数据的?
p.数据库的存储结构和excel很像,以表(table)为单位
4.2、数据库存储数据的步骤:
p1.新建数据库文件
p2.新建一张表(table)
p3.添加多个字段(column,列,属性)
p4.添加多行记录(row,每行存放多个字段对应的值)
5、Navicat:数据库管理软件
1、Navicat是一款著名的数据库管理软件,支持大部分主流数据库(包括SQLite)
2、利用Navicat建立数据库连接:如图8-1
3、建表:如图8-2
2.1、Navicat建立数据库连接如图8-1

2.2、建表如图8-2

3.3、查看DDL 如图8-3

4.4、执行SQL语句 如图8-4

8-1、SQL语句
1、如何在程序运行过程中操作数据库中的数据?
1> 那得先学会使用SQL语句。
2、什么是SQL?
1> SQL(structuredquerylanguage):结构化查询语言。
2> SQL是一种对关系型数据库中的数据进行 定义 和 操作 的语言。
3> SQL语言简洁,语法简单,好学好用
3、什么是SQL语句?
1> 使用SQL语言编写出来的句子\代码,就是SQL语句。
2> 在程序运行过程中,要想操作(增删改查,CRUD)数据库中的数据,必须使用SQL语句。
4、SQL语句的特点
1> 不区分大小写(比如数据库认为user和UsEr是一样的)
2> 每条语句都必须以分号;结尾
5、SQL中的常用关键字有
select、insert、update、delete、from、create、where、desc、order、by、group、table、alter、view、index等等;
6、数据库中不可以使用关键字来命名表、字段;
8-2、SQL语句的种类
1、数据定义语句(DDL:DataDefinitionLanguage)
1.1> 包括create和drop、alter等操作.
1.2> 在数据库中 创建新表 或 删除表(crea tetable 或 drop table).
2、数据操作语句(DML:Data Manipulation Language)
2.1> 包括 insert、update、delete等操作.
2.2> 上面的3种操作分别用于 添加、修改、删除 表中的数据.
3、数据查询语句(DQL:Data Query Language)
3.1> 可以用于查询获得表中的数据.
3.2> 关键字select是DQL(也是所有SQL)用得最多的操作.
3.3> 其他DQL常用的关键字有where,orderby,groupby 和 having.
学习SQL资料:http://www.phpstudy.net
8-3、DDL语句(主要是对表的操作)
1、创建表
1> 格式:create table 表名 (字段名1 字段类型1, 字段名2 字段类型2, …) ;
2>示例:create table t_student (id integer, name text, age inetger, score real) ;
3>经验:
A、实际上SQLite是无类型的
A1、就算声明为integer类型,还是能存储字符串文本(主键除外)。
A2、建表时声明啥类型或者不声明类型都可以,也就意味着创表语句可以这么写:create table t_student(name, age);
A3、为了保持良好的编程规范、方便程序员之间的交流,编写建表语句的时候最好加上每个字段的具体类型.
B、语句优化
B1、创建表格时, 最好加个表格是否已经存在的判断, 这个防止语句多次执行时发生错误:create table if not exists 表名 (字段名1 字段类型1, 字段名2 字段类型2, …) ;
如:create table if not exists t_student (id integer,name text,age inetger,score real);
2、删除表
1> 格式: drop table 表名 ; \ drop table if exists 表名 ;
2>示例: drop table t_student ;\ drop table if exists t_student ;
3>语句优化:删除表格时, 最好加个表格是否已经存在的判断, 这个防止语句多次执行时发生错误.\ drop table if exists 表名 ;
如:drop table if not exists t_student;
3、修改表
注意: sqlite里面只能实现Alter Table的部分功能。不能删除一列, 修改一个已经存在的列名
修改表名:ALTER TABLE 旧表名 RENAME TO 新表名
新增属性:ALTER TABLE 表名 ADD COLUMN 列名 数据类型 限定符
补充:字段类型
1、SQLite将数据划分为以下几种存储类型:
integer:整型值 real:浮点值
text:文本字符串 blob:二进制数据(比如文件)
2、实际上SQLite是无类型的
2.1 就算声明为integer类型,还是能存储字符串文本(主键除外)
2.2 建表时声明啥类型或者不声明类型都可以,也就意味着创表语句可以这么写:create table t_student(name, age);
3、为了保持良好的编程规范、方便程序员之间的交流,编写建表语句的时候最好加上每个字段的具体类型
8-4、约束
1、简单约束
1> 不能为空 not null :规定字段的值不能为null
2> 不能重复 unique :规定字段的值必须唯一
3> 默认值 default :指定字段的默认值
示例:create table t_student (id integer, name text not null unique, age integer not null default 1) ;
a、name字段不能为null,并且唯一。
b、age字段不能为null,并且默认为1。
2、主键约束
2.1、添加主键约束的原因?
如果t_student表中就name和age两个字段,而且有些记录的name和age字段的值都一样时,那么就没法区分这些数据,造成数据库的记录不唯一,这样就不方便管理数据。良好的数据库编程规范应该要保证每条记录的唯一性,为此,增加了主键约束。也就是说,每张表都必须有一个主键,用来标识记录的唯一性。
2.2、什么是主键?
1>主键(Primary Key,简称PK)用来唯一地标识某一条记录。
例如:t_student可以增加一个id字段作为主键,相当于人的身份证
2>主键可以是一个字段或多个字段
2.3、主键的设计原则?
1>主键应当是对用户没有意义的;
2>永远也不要更新主键;
3>主键不应包含动态变化的数据;
4>主键应当由计算机自动生成.
2.4、主键的声明?
1> 在创表的时候用primary key声明一个主键:
create table t_student (id integer primary key, name text, age integer) ;
integer类型的id作为t_student表的主键.
2> 主键字段
只要声明为primary key,就说明是一个主键字段
主键字段默认就包含了not null 和 unique 两个约束
3> 如果想要让主键自动增长(必须是integer类型),应该增加autoincrement
create table t_student (id integer primary key autoincrement, name text, age integer) ;
8-5、DML语句(主要操作表中的每一条记录的,主要是: 增、删、改)
1. 插入数据(insert)
格式:insert into 表名 (字段1, 字段2, …) values (字段1的值, 字段2的值, …) ;
示例:insert into t_student (name, age) values (‘sz’,10) ;
注意:数据库中的字符串内容应该用单引号 ’ 括住
2. 更新数据(update)
格式:update 表名 set 字段1 = 字段1的值, 字段2 = 字段2的值, … ;
示例:update t_student set name = ‘wex’, age = 20 ;
注意:上面的示例会将t_student表中所有记录的name都改为wex,age都改为20
3. 删除数据(delete)
格式:delete from 表名 ;
示例:delete from t_student ;
注意:上面的示例会将t_student表中所有记录都删掉
8-6、条件语句
1、如果只想更新或者删除某些固定的记录,那就必须在DML语句后加上一些条件
2、条件语句的常见格式
where字段=某个值;//不能用两个=
where字段is某个值;//is相当于=
where字段!=某个值;
where字段isnot某个值;//isnot相当于!=
where字段>某个值;
where字段1=某个值and字段2>某个值;//and相当于C语言中的&&
where字段1=某个值or字段2=某个值;//or相当于C语言中的||
条件语句练习
示例:
1、将t_student表中年龄大于10 并且 姓名不等于wex的记录,年龄都改为 5.
update t_student set age = 5 where age > 10 and name != ‘wex’ ;
2、删除t_student表中年龄小于等于10 或者 年龄大于30的记录
delete from t_student where age <= 10 or age > 30 ;
猜猜下面语句的作用?
3、update t_student set score = age where name = ‘wex’ ;
将t_student表中名字等于wex的记录,score字段的值 都改为 age字段的值
8-7、DQL (查询相关语句)
格式
select 字段1, 字段2, …from表名;
select *from 表名; //查询所有的字段
示例
select name, age from t_student;
select *from t_student;
select *from t_student where age>10;//条件查询
1 、统计
(1)计算记录的数量 :count(X)
格式:
select count (字段) from 表名;
select count (*) from 表名;
示例:
select count (age) from t_student;
select count (*) from t_student where score >= 60;
(2)补充:
计算某个字段的平均值 :avg(X)
计算某个字段的总和:sum(X)
计算某个字段的最大值:max(X)
计算某个字段的最小值:min(X)
2 、排序
(1)查询出来的结果可以用 order by 进行排序
select * from 表名 order by 字段;
select * from t_student order by age; //(默认升序)
(2)默认是按照升序排序(由小到大),也可以变为降序(由大到小)
select * from t_student order by age desc; //降序
select * from t_student order by age asc; //升序(默认)
(3)也可以用多个字段进行排序
select * from t_student order by age asc,height desc;
✔️先按照年龄排序(升序),年龄相等就按照身高排序(降序)
3 、limit分页使用 limit 可以 精确地控制 查询结果 的数量,比如 :每次只查询10条数据
(1)格式:
select * from 表名 limit 数值1, 数值2 ;
(2)示例:
select * from t_student limit 4, 8 ;
可以理解为:跳过最前面4条语句,然后取8条记录
(3)分页:
(3.1) limit常用来做分页查询,比如每页固定显示5条数据,那么应该这样取数据。
第1页:limit 0, 5 ; 第2页:limit 5, 5 ; 第3页:limit 10, 5 ······ 第n页:limit 5*(n-1), 5
(3.2)特殊案例
select * from t_student limit 7 ;
相当于select * from t_student limit 0, 7 ;
表示取最前面的7条记录
8-8、多表查询
1、多表查询:select 字段1, 字段2, … from 表名1, 表名2 ;
2 、起别名
( 1 )格式(字段 和 表 都可以 起别名)
//select 字段1 别名,字段2 别名,…from 表名 别名;
//select 字段1 别名,字段2 as 别名,…from 表名 as 别名;
//select 别名.字段1, 别名.字段2, …from 表名 别名;select
别名1.字段1 as 字段别名1,
别名2.字段2 as 字段别名2,
…
from
表名1 as 别名1,
表名2 as 别名2 ;
可以给表或者字段单独起别名,as 可以省略
( 2 )示例
2.1. select name myname, age myage from t_student;
✔️给name起个叫做myname的别名,给age起个叫做myage的别名
2.2. select s.name,s.age from t_student s;
✔️给t_student表起个别名叫做 ‘s’ 利用 s 来引用表中的字段。
3、表连接查询
select 字段1, 字段2, … from 表名1, 表名2 where 表名1.id = 表名2.id;
4、外键
如果表A的主关键字是表B中的字段,则该字段(也就是表A的主关键字)称为表B的外键
保持数据一致性,完整性,主要目的是控制存储在外键表中的数据。 使两张表形成关联,外键只能引用外表中的列的值或使用空值。
九、FMDB
一、FMDB简介
1.什么是FMDB
1.1、FMDB是iOS平台的SQLite数据库框架
1.2、FMDB以OC的方式封装了SQLite的C语言API
2.FMDB的优点
2.1、使用起来更加面向对象,省去了很多麻烦、冗余的C语言代码
2.2、对比苹果自带的CoreData框架,更加轻量级和灵活
2.3、提供了多线程安全的数据库操作方法,有效地防止数据混乱
3.FMDB的github地址
https://github.com/ccgus/fmdb
二、FMDB基本使用
2-1、核心类
FMDB有三个主要的类:FMDatabase、FMResultSet、FMDatabaseQueue
1.FMDatabase
一个FMDatabase对象就代表一个单独的SQLite数据库
用来执行SQL语句
2.FMResultSet
使用FMDatabase执行查询后的结果集
3.FMDatabaseQueue
用于在多线程中执行多个查询或更新,它是线程安全的
2-2、 打开数据库
1.通过指定SQLite数据库文件路径来创建FMDatabase对象
FMDatabase *db = [FMDatabase databaseWithPath:path];
if (![db open]) {
NSLog(@"数据库打开失败!");
}
2.文件路径有三种情况
1>具体文件路径
✔️如果不存在会自动创建
2>空字符串@""
✔️会在临时目录创建一个空的数据库
✔️当FMDatabase连接关闭时,数据库文件也被删除
3>nil
✔️会创建一个内存中临时数据库,当FMDatabase连接关闭时,数据库会被销毁
2-3、执行更新
1> 在FMDB中,除查询以外的所有操作,都称为“更新”
create、drop、insert、update、delete等
2> 使用executeUpdate:方法执行更新
- (BOOL)executeUpdate:(NSString*)sql, ...
- (BOOL)executeUpdateWithFormat:(NSString*)format,
- (BOOL)executeUpdate:(NSString*)sqlwithArgumentsInArray:(NSArray*)arguments
3> 示例
[db executeUpdate:@"UPDATE t_student SET age = ? WHERE name = ?;", @20, @"Jack"]
2-3、执行查询
1> 查询方法
- (FMResultSet*)executeQuery:(NSString*)sql, ...
- (FMResultSet*)executeQueryWithFormat:(NSString*)format,
- (FMResultSet*)executeQuery:(NSString*)sqlwithArgumentsInArray:(NSArray*)arguments
2> 示例
//查询数据
FMResultSet *rs = [db executeQuery:@"SELECT * FROM t_student"];
// 遍历结果集
while ([rs next]) {
NSString*name = [rsstringForColumn:@"name"];
int age = [rsintForColumn:@"age"];
double score = [rsdoubleForColumn:@"score"];
}
FMDatabaseQueue
1.FMDatabase这个类是线程不安全的,如果在多个线程中同时使用一个FMDatabase实例,会造成数据混乱等问题
2.为了保证线程安全,FMDB提供方便快捷的FMDatabaseQueue类
3.FMDatabaseQueue的创建
FMDatabaseQueue *queue = [FMDatabaseQueue databaseQueueWithPath:path];
4.简单使用
[queue inDatabase:^(FMDatabase *db) {
[dbexecuteUpdate:@"INSERT INTOt_student(name) VALUES (?)",@"Jack"];
[dbexecuteUpdate:@"INSERT INTOt_student(name) VALUES (?)",@"Rose"];
[dbexecuteUpdate:@"INSERT INTOt_student(name) VALUES (?)",@"Jim"];
FMResultSet *rs = [dbexecuteQuery:@"select* fromt_student"];
while([rs next]) {
// …
}
}];
5.使用事务
[queue inTransaction:^(FMDatabase *db, BOOL *rollback) {
[dbexecuteUpdate:@"INSERT INTOt_student(name) VALUES (?)",@"Jack"];
[dbexecuteUpdate:@"INSERT INTOt_student(name) VALUES (?)",@"Rose"];
[dbexecuteUpdate:@"INSERT INTOt_student(name) VALUES (?)",@"Jim"];
FMResultSet*rs= [dbexecuteQuery:@"select * fromt_student"];
while([rsnext]) {
// …
}
}];
6.事务回滚
*rollback = YES;