【十八掌●武功篇】第八掌:HBase之基本概念
这一篇博文是【大数据技术●降龙十八掌】系列文章的其中一篇,点击查看目录:![]() 大数据技术●降龙十八掌
大数据技术●降龙十八掌
系列文章:
:【十八掌●武功篇】第八掌:HBase之基本概念
【十八掌●武功篇】第八掌:HBase之Shell
【十八掌●武功篇】第八掌:HBase之基本操作Java API
【十八掌●武功篇】第八掌:HBase之过滤器总结
【十八掌●武功篇】第八掌:HBase之性能调优
【十八掌●武功篇】第八掌:HBase之安装与集成 [草稿]
第一部分: HBase概述
一、 官网定义
Apache HBase is the Hadoop database, a distributed, scalable, big data store.
HBase是Hadoop生态系统中的一个分布式、可扩展、面向列、可伸缩、具有自动容错的大数据数据库。
● 分布式:HBase是集群方式运行的,HBase集群由一个Master节点和多个RegionServer节点组成,并由Zookeeper进行管理。
● 可扩展:HBase的数据存储是基于HDFS的,本身就可扩展的。
● 面向列:HBase是按列拆分为多个独立的集合进行存储的,按列存储利于压缩,减少存储空间, 并避免了读取冗余列,提高了查询的效率,缺点是不如行存储写入速度那么高,但是面向列存储更适合于大数据数据库。
● 可伸缩:可伸缩性讲究平滑线性的性能提升,HBase对数据的处理能力上是可以伸缩的,是指随着数据量的增长处理时间是同步线性增长的,并没有出现当数据量很大时造成处理时间的急剧增加现象
● 自动容错:HBase的自动容错体现在很多方面:Master自动容错、RegionServer自动容错、HDFS的自动容错。
二、 HBase的应用场景
应用于对大数据进行实时、随机查询的场景,这个大数据可以是数十亿行、数百万列的数据。但是HBase的局限在于HBase表的设计必须是依赖于查询条件的,是根据业务的查询条件来设计HBase表。
三、 存储和执行
HBase里的数据是存储在HDFS中的,是通过MapReduce来执行数据分析。
四、 HBase的框架特性
1、 线性与模块化扩展,体现了HBase的可伸缩性和扩展性。
2、 读写严格一致
3、 表可以自动或者通过配置进行切分
4、 数据读写节点服务器支持自动失效检测
5、 基于MapReduce方便对表进行数据处理
6、 方便使用Java API做为客户端进行过滤访问
7、 支持多客户端访问方式:Thrift、REST-ful。
8、 基于JRuby实现的Shell交互式操作界面
9、 可通过Ganglia或者JMX进行集群监控
五、 HBase表的特性
1、 大,一个表可以有几十亿行,百万列。数十亿行数百万列数千个版本=TB或者PB级别。
2、 模式自由:每行有一个可排序的主键和任意多的列,列可以动态增加,同一个表中的不同行可以有不同的列。
3、 面向列存储的。
4、 空null并不占用空间,数据在HBase都是以二进制数组进行存储的。
5、 数据有多个版本,每个单元格有多个不同的版本,版本号用时间戳自动分配,单元格中数据的更新都是新增新的版本的数据。
6、 数据类型单一,都是以字节数组存储的。
六、 HBase与HDFS比较
| HDFS | HBase |
|---|---|
| 为分布式存储提供文件系统 | 提供表状的面向列的数据存储 |
| 不支持随机读写,对存储大文件进行优化 | 对表状数据进行随机读写进行优化 |
| 直接读取文件 | 使用键值对类型数据 |
| 数据模型不灵活 | 提供灵活的数据模型 |
| 使用文件系统和处理框架 | 使用表状数据,依赖内置的MapReduce支持 |
| 为一次写多次读进行优化 | 为多次读写进行优化 |
七、 HBase与RDBMS比较
| 关系型数据库 | HBase |
|---|---|
| 支持向上扩展(升级硬件) | 支持向外扩展(增加服务器) |
| 使用SQL查询从表中读取数据 | 使用API和MapReduce来读写数据 |
| 面向行存储 | 面向列存储 |
| 数据总量依赖于数据库的配置 | 数据总量取决于服务器的个数 |
| 模式更严格 | 模式灵活,不严格 |
| 具有ACID支持 | 没有內建的对HBase的支持 |
| 适合结构化数据 | 适合结构化数据和 |
| 一般是中心化的 | 是分布式的 |
| 一般能保证事务的完整性 | HBase不支持事务 |
| 支持Join | 不支持Join |
| 支持参照完整性 | 没有内置的参照完整性支持 |
第二部分: HBase的组成部分
一、 架构图

二、 Master作用
1、 为RegionServer分配Region
Region可以看做是HBase表的分区,HBase表数据根据RowKey进行划分后,分布在不同的Region上。
2、 负责RegionServer的负载均衡
3、 发现失效的RegionServer并重新分配其上的Region
4、 管理用户对HBase表的增删改查操作
三、 Region
Region是HBase的最小负载均衡的单元,HBase表数据会分布在一个或者多个Region上。默认情况下创建表时只有一个Region,默认是256M大小,当数据慢慢增多后,Region会自动切分,平均分为两个Region。
四、 RegionServer
1、 维护其所包括的Region,处理对这些Region的IO请求。
2、 负责切分运行中变的过大的Region。
五、 Zookeeper
1、 保证HBase集群中只有一个Master在工作。
Master和RegionServer启动时会自动向Zookeeper注册。
2、 存储所有Region的寻址入口。
HBase中有一个hbase:meta系统表,记录了HBase集群中有哪些表、表有哪些Region、Region在哪些RegionServer上、Region包含哪些Rowkey(起始RowKey、截止RowKey)这些信息。
Zookeeper上存储了hbase:meta表在哪些Region上,在哪些RegionServer上,RowRegion包含哪些RowKey。
3、 实时监控RegionServer的上线、下线信息,并实时通知Master。
4、 存储HBase的Schema和Table元数据。
5、 Zookeeper上关于HBase的ZK节点
[zk: localhost:2181(CONNECTED) 7] ls /hbase
[meta-region-server, backup-masters, draining, table, region-in-transition, table-lock, running, namespace, hbaseid, online-snapshot, replication, recovering-regions, splitWAL, rs]
(1) meta-region-server:存储的是hbase:mate表的元数据。
(2) backup-masters:存储备份Master的信息,因为有可能有多个backup-master,所以可能有多个子节点。
(3) draining:记录哪些RegionSever下线了。
(4) table:存储HBase上表的信息,存储有哪些表。
(5) region-in-transition:控制事务的。
(6) table-lock:表锁信息,HBase只有行锁。
(7) running:正在运行的一些信息。
(8) master:master节点的信息。
(9) namespace:表的命名空间的信息,默认是default命名空间,系统的命名空间是hbase。
如hbase:meta中,hbase是命名空间的名字。
(10) hbaseid:hbase的编号。
(11) online-snapshot:
(12) replicateion
(13) recovering-regions
(14) splitWAL
(15) rs:储存regionServer节点的信息,RegionSever启动时会在Zookeeper上的注册。
六、 Client
包含访问HBase的接口,并维护Cache来加快HBase的访问,比如Region的位置信息。
七、 hbase:meta表
hbase:meta表中存储的是HBase中表Regin的信息,查看hbase:meta表中数据的命令如下:
hbase(main):005:0> scan ‘hbase:meta’ , {LIMIT=>100}
表中rowkey格式为:test,,1481541882182.b46f1de4ea1a909e
test为表名;第二个为开始的Rowkey,带三部分是时间戳,最后为对前面的md5。
第三部分: HBase表的逻辑结构
八、 表的组成结构
1、 表结构示意图
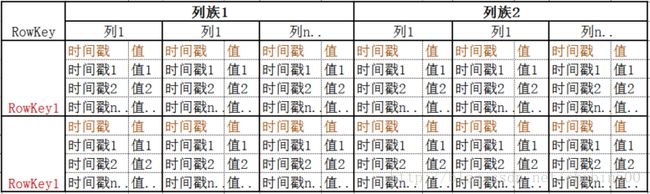
2、 表名
类似于关系型数据库的表。
3、 RowKey
类似于关系型数据库中的主键,RowKey是HBase表中数据的唯一标示,是按照字典顺序排序的,最多存储64K数据。
4、 列族
必须是在创建表时要定义好列族,也可以动态添加列族,列族不能太多,一般是一两个。
在物理上同一行同一个列族下的所有内容存储在一起。
5、 列标签
一个列族下,是由列标签和Value值组成的键值对组成的,插入数据时是可以任意指定列标签的,但是实际应用时,是要根据业务来定义列表标签。
6、 单元格
单元格是存储数据的最小单位,是由表名、rowkey、列族、列标签确定一个单元格的,一个单元格上多个版本,每一个版本有一个值,同一个单元格上,可以有多个版本的数据。
7、 时间戳
时间戳是单元格上的版本号。
九、 HBase的更新
因为HBase实际上是存储在HDFS上的,由于HDFS上的数据是不能进行更改的。
HBase的更新是在单元格上新增一个版本。
第四部分: HBase数据读写流程
十、 读HBase数据过程
1、 客户端连接Zookeeper,从ZK节点,/hbase/meta-region-server节点上获取关于hbase:meta表的信息。
2、 根据hbase:meta表的元数据找存储hbase:meta表数据的到RegionServer,读取数据。
3、 从hbase:meta表中读取目标表的元数据,根据元数据去读取对应Region上的数据。
4、 写缓存:blockcache
十一、 HBase写数据过程
下面以客户端向HBase中test表里写一条数据为例,说明写入数据的过程:
1、 客户端首先读取Zookeeper节点,获取hbase:meta表所在Region信息
2、 根据Regin信息找到hbase:meta表的位置,读取hbase:meta表里的数据。
3、 从hbase:meta表里读取到test表所有的Region信息,再根据RowKey确定插入哪个Region中。
4、 Region内部会根据列族划分出Store,每个Store中会有一个memstore和零个或者多个storefile。memstore是一块内存空间,默认是128M,达到最大空间后,就会刷写到磁盘,生成一个storefile。memstore是滚动刷写的,即当memstore满后就会生成一块新的memstore用来接收新的写入,老的memstore用来进行刷写磁盘,这样避免阻塞提高效率。
一个storefile是一个HFile。
5、 当插入memstore之前会有一个WAL(预写日志)机制,就是先将数据写入一个日志文件Hlog中,这个文件是顺序写的,然后再写入memstore,这样避免了memstore没有刷写到前宕机造成数据丢失的问题。如果宕机,可以从HLog中再次重生数据。HLog也是DataNode上的一个文件,有多个备份。
6、 当memstore中的数据刷写到磁盘后,HLog中的数据也会随着删除。
第五部分: RowKey设计
1、 唯一性
rowkey是HBase表中的唯一标识,所以必须唯一。
2、 长度尽量短,最长不能超过64KB。
每一行都有一个rowkey, HBase表中的数据往往很大,但是rowkey是与业务信息无关的数据,如果rowkey设计的很长,那就会占用很大的硬盘资源,造成资源巨大的浪费。所以应该在能满足需求的基础上,rowkey设计的尽量的短。
3、 写入散列、读取连续原则
HBase是根据rowkey进行分配Region的,相近的rowkey会分配到同一个region上,rowkey设计的散列,更利于在各个Region上平均分配,不会导致数据在某一时刻集中存储到某一两个Region上,造成这几个Region压力过大。
4、 尽可能将查询字段放入rowkey
因为HBase根据rowkey查询速度是最快的,所以要尽量将查询字段放入rowkey中。
这一篇博文是【大数据技术●降龙十八掌】系列文章的其中一篇,点击查看目录:![]() 大数据技术●降龙十八掌
大数据技术●降龙十八掌