正则
内容摘要:
- 正则介绍_grep
- 命令sed
- 命令awk
一、正则介绍_grep
- 什么是正则?
- 正则就是一串有规律的字符串。
- 掌握好正则对编写shell脚本有很大的帮助。
- 各种编程语言中都有正则,原理是一样的。
- 命令grep 全面搜索正则表达式并把行打印出来,grep是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来, grep 更适合单纯的查找或匹配文本。
- 选项-c 显示符合要求的行数,例

- 选项-n 显示符合要求的行和其行号。
- 选项-i 不区分大小写。
- 选项-v 显示不符合要求的行,即取相反的结果。
- 选项-r 遍历所有子目录中的参数。
- 选项-A 过滤出符合条件行包括该行后的指定行数,例
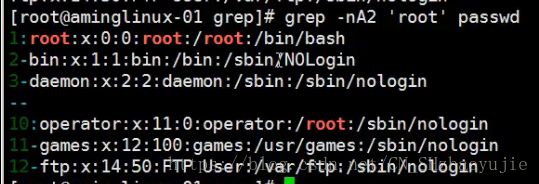
- 选项-B 过滤出符合条件行包括该行前的指定行数
- 选项-C 过滤出符合条件行包括该行前后的指定行数
- 实际应用的例子
- 在passwd中过滤出所有包含0-9任意一个数字的行 grep '[0-9]' passwd
- 在passwd中过滤出不包含0-9任意数字的行,并显示行号 grep -vn '[0-9]' passwd
- 在passwd中过滤出开头为#的行 grep '^#' passwd
- 在passwd中过滤出不包含0-9任意数字开头的行,[^]表示反义,取反的意思。^表示行首 grep '^[^0-9]' passwd
- 在passwd中过滤出所有除了数字以外的行 grep '[^0-9]' passwd
- 在passwd中过滤出所有包括r.o格式字符串的行。 .点表示任意的一个字符 grep 'r.o' passwd
- 在passwd中过滤出所有包括o开头和o结尾的行 grep 'o*o' passwd 符号*表示前面一个字符任意的0-n次相同的字符。如oo、ooo 、 oooo等等。
- 在passwd中过滤出所有包括2个O格式的行 grep 'o\{2\}' passwd 符号{}在grep中直接使用,需要使用\进行脱义。
- 命令egrep 或者 grep -E 可以在使用{}、+等符号时不用进行脱义。
- 加号表示前一个字符的1次或n次 egrep 'o+o' passwd
- 问号表示前一个字符的0次或1次,即有或没有 egrep 'o?t' passwd
- 符号|表示或者,root或者nologin egrep 'root|nologin' passwd
- 过滤oo组合出现两次的行,( )括号内的为一个整体,符号{}表示前面的字符出现多少次 egrep '(oo){2}' passwd
二、命令sed
sed是一个“非交互式的”面向字符流的编辑器。能同时处理多个文件多行的内容,可以不对原文件改动,把整个文件输入到屏幕,可以把只匹配到模式的内容输入到屏幕上。还可以对原文件改动,但是不会再屏幕上返回结果。 grep 更适合单纯的查找或匹配文本。
- 可以实现grep 'root' passwd 相同的效果,即在passwd中过滤打印有root的行: sed -n '/root/'p test.txt
- 命令sed 同样可以使用grep的符号,在使用 +、{ }也需要脱义。使用-r选项进行脱义。
- 将指定的第5行打印出: sed -n '5'p test.txt
- 将第1行到第5行打印出: sed -n '1,5'p test.txt
- 将第1行到最后一行全部打印出来:sed -n '1,$'p test.txt
- 选项-e可以同时过滤打印多个条件。例:sed -e '1'p -e '/root/'p -n test.txt 匹配打印出第1行,和其他包含root的行。(多个条件,匹配同一行时并不会合并显示,而是符合几次打印几次。)
- 不区分大小写的匹配过滤打印出包含有bus的行。(大写I选项可以使sed过滤时不区分大小写): sed -n '/bus/'Ip test.txt
- 删除1到30行,打印剩余的行(不会删除实际的文件): sed '1,30'd test.txt
- 删除包含有user2的行,并将剩余的打印出。(-i会删除实际的文件内容):sed -i '/user2/'d test.txt
- 将1到10行的root全部替换成toor,并打印出来。(不影响原文件的内容): sed '1,10s/root/toor/g' test.txt
- 命令 sed -r 's/([^:]+):(.*):([^:]+)/\3:\2:\1/' test.txt
- 思路:-r 进行脱义,([^:]+): 第一段表示冒号前一个以上的所有非冒号的字符串,(.*)第二段表示任意数量的任意字符即两个冒号之间的所有字符,:([^:]+)第三段表示冒号后所有一个以上的非冒号字符。()内的三段分别以1、2、3代替。(不影响原文件的内容)
- 结果:将所有行第一个冒号前非冒号的所有字符于最后一个冒号后非冒号的所有字符,调换位置。中间不变。
- 删除所有字母并显示(不影响原文件的内容) : sed 's/[a-zA-Z]//g' test.txt
- 将test.txt中所有行开头添加一个aaa:,&表示()中的内容(也可以用\1表示): sed -r 's/(.*)/aaa:&/' test.txt
三、命令awk
awk 不会更改文件的实际内容,使用正则时不需要脱义。awk 更适合格式化文本,对文本进行较复杂格式处理
- 以冒号为分隔符,打印该文件所有行的第一段内容: awk -F ':' '{print $1}' test.txt
- 以冒号为分隔符,打印该文件的所有段。($0表示全部): awk -F ':' '{print $0}' test.txt
- 以冒号为分隔符,打印该文件所有行的1、3、4段。(使用逗号时默认空格显示结果,也可以使用“#”等符号分隔显示的结果。): awk -F ':' '{print $1,$3,$4}' test.txt
- 过滤打印出含有oo的行,效果与sed、grep类似: awk '/oo/' test.txt
- 以冒号为分隔符。将第一段中包含有oo的行打印出来,(~为匹配的意思): awk -F ':' '$1 ~ /oo/' test.txt
- 以冒号为分隔,将所有含有root的行的第一第二段打印出来以及所有含有user的行的第二第三段打印出来: awk -F ':' '/root/ {print $1,$2} /user/ {print $2,$3}' test.txt
- 以冒号为分隔符,将含有root或者user的行的,全部段落打印出来: awk -F ':' '/root|user/ {print $0}' test.txt
- 以冒号为分隔符,将所有第三段大于等于1000的行的第一段字符打印出来。(数字1000处,以""双引号标注时会以文本计算,不加时就以普通数字计算。): awk -F ':' '$3>=1000 {print $1}' test.txt
- 以冒号为分隔符,将所有第七段不等于文本nologin的行的第一段打印出来。(!=表示不等于。): awk -F ':' '$7!="nologin" {print $1}' test.txt
- 以冒号为分隔,打印所有第三段小于第四段的行: awk -F ':' '$3<$4' test.txt
- 以冒号为分隔,打印所有第三段大于5并且小于10的行: wk -F ':' '$3>5 && $3<10' test.txt
- 以冒号为分隔,打印所有第三段大于5或第四段为/bin/bash的行: awk -F ':' '$3>5 || $4=="/bin/bash"' test.txt
- 以冒号为分隔,打印出所有第三段大于1000或第七段包含有oo的行: awk -F ':' '$3>1000 || $7 ~ /oo/' test.txt
- 以冒号为分隔符,打印所有第三段大于1000的行的第一第三第五段,并以#分隔(OFS是print输出结果分隔符的变量,用于自定义输出分隔符): awk -F ':' '{OFS="#"} {if ($3>1000) {print $1,$3,$5}}' test.txt
- NR表示行数、NF表示段数。两者都可作为判断条件。
- 以冒号为分隔符,打印所有行并标注行号: awk -F ':' '{print NR":"$0}' test.txt
- 以冒号为分隔符,打印所有行并在开头标注段落数: awk -F ':' '{print NF":"$0}' test.txt
- 以冒号为分隔符,打印第10行以内且第一段包含有root或sync的行: awk -F ':' 'NR<=10 && $1 ~ /root|sync/' test.txt
- 以冒号为分隔符,将第一段替换成root(单个=就是赋值): awk -F ':' '$1="root"'
- tot初始值为0,从该文本的第一行开始到最后一行循环相加第三段的值,最后打印出来:awk -F ':' '{(tot=tot+$3)}; END {print tot}' test.txt
- 以冒号为分隔符,打印该文本每一行对应行数的段以及最后一段。假设所有行段为7段,即第一行打印第一段:第七段、第二行打印第二段:第七段。依次类推: awk -F ':' '{print $NR":"$NF}' test.txt
四、扩展
- 把一个目录下,过滤所有*.php文档中含有eval的行 grep -r --include="*.php" 'eval' /data/ 仅仅在搜索匹配*.php的文件时在目录中递归搜索
五、sed练习题
- 把/etc/passwd 复制到/root/test.txt,用sed打印所有行
答:sed -n '1,$'p test.txt
- 打印test.txt的3到10行
答:sed -n '3,10'p test.txt
- 打印test.txt 中包含 ‘root’ 的行
答:sed -n '/root/'p test.txt
- 删除test.txt 的15行以及以后所有行
答:sed '15,$'d test.txt
- 删除test.txt中包含 ‘bash’ 的行
答:sed '/bash/'d test.txt
- 替换test.txt 中 ‘root’ 为 ‘toor’
答:sed '1,$s/root/toor/g' test.txt
- 替换test.txt中 ‘/sbin/nologin’ 为 ‘/bin/login’
答:sed '1,$s/sbin\/nologin/bin\/login/g' test.txt
- 删除test.txt中5到10行中所有的数字
答:sed '5,10s/[0-9]//g' test.txt
- 删除test.txt 中所有特殊字符(除了数字以及大小写字母)
答:sed 's/[^0-9a-zA-Z]//g' test.txt
- 把test.txt中第一个单词和最后一个单词调换位置
答:sed -ri 's/([^:]+):(.*):([^:]+)/\3:\2:\1/' test.txt
- 把test.txt中出现的第一个数字和最后一个单词替换位置
答:sed -r 's/([^0-9][^0-9]*)([0-9][0-9]*)([^0-9].*)([^a-zA-Z])([a-zA-Z][a-zA-Z]*$)/\1\5\3\4\2/' test.txt
- 把test.txt 中第一个数字移动到行末尾
答:sed -r 's/([^0-9][^0-9]*)([0-9][0-9]*)([^0-9].*$)/\1\3\2/' test.txt
- 在test.txt 20行到末行最前面加 ‘aaa:’
答:sed -r '20,$s/(.*)/aaa:&/' test.txt
六、awk练习题
- 用awk 打印整个test.txt (以下操作都是用awk工具实现,针对test.txt)
答:awk '{print $0}' test.txt
- 查找所有包含 ‘bash’ 的行
答:awk '/bash/ ' test.txt
- 用 ‘:’ 作为分隔符,查找第三段等于0的行
答:awk -F ':' '$3==0' test.txt
- 用 ‘:’ 作为分隔符,查找第一段为 ‘root’ 的行,并把该段的 ‘root’ 换成 ‘toor’ (可以连同sed一起使用)
答:awk -F ':' '$1=="root"' test.txt | sed 's/root/toor/'
- 用 ‘:’ 作为分隔符,打印最后一段
答:awk -F ':' '{print $NF}' test.txt
- 打印行数大于20的所有行
答:awk -F':' 'NR>20' test.txt
- 用 ‘:’ 作为分隔符,打印所有第三段小于第四段的行
答:awk -F':' '$3<$4' test.txt
- 用 ‘:’ 作为分隔符,打印第一段以及最后一段,并且中间用 ‘@’ 连接 (例如,第一行应该是这样的形式 'root@/bin/bash‘ )
答:awk -F ':' '{OFS="@"} {print $1,$NF}' test.txt
- 用 ‘:’ 作为分隔符,把整个文档的第四段相加,求和
答:awk -F ':' '{tot=tot+$4}; END {print tot}' test.txt