如何评价我们分类模型的性能?
作者:chen_h
微信号 & QQ:862251340
微信公众号:coderpai
什么是分类模型?
分类是将每个数据集合中的元素分配给一个已知的数据类别。
那么分类都有哪些任务呢?
- 根据医生的病历记录,将检查者区分为健康或者生病的人;
- 例如使用一些人口统计学和历史财务数据,在申请信用卡的时候,我们就可以对客户进行可信度评分,评为“可信”或者“不可信”;
- 可以根据用户使用软件的行为数据进行分析,来分类这个用户是不是还会继续使用这个软件,比如可以分为“继续使用的用户”和“不继续使用的用户”;
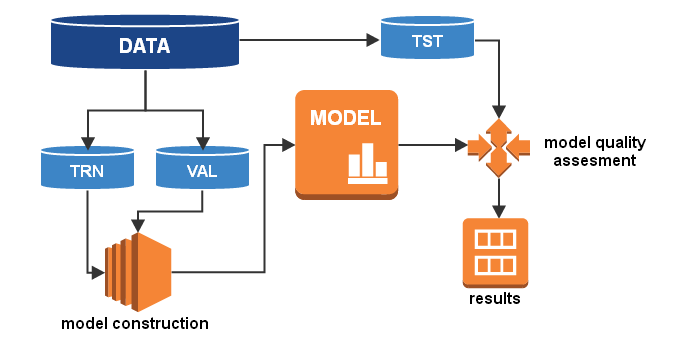
如何构建一个分类模型?
1. 数据预处理(导入数据,清洗数据,验证数据)
这个阶段将数据分为两个或三个部分:
- 训练数据 —— 将被用来进行数据建模;
- 验证数据 —— 将被用来做模型评估(这个在复杂环境下会被用到);
- 测试数据 —— 将被用来评估模型的最终质量;
2. 模型构建(使用训练数据和验证数据)
3. 模型质量评估(使用测试数据来测试模型)
4. 模型应用和后续监控(定期检查模型是否运行正常,性能是否下降)
可以使用哪些指标来确定分类模型的质量呢?
这里有两种指标可以来评估一个分类模型的质量:
- 定量指标 —— 用具体数值来表示分类质量。
- 图形指标 —— 分类质量用一张图来表示。图形化表示方法简化了质量的评估,并且也增强了可视化效果。这些指标包括:
- 混淆矩阵(confusion matrix)
- ROC 曲线
- LIFT 图表
用于评估分类模型的一些基本概念
二分类和多分类
二分类:
一个类别被定义为正样本,一个类别被定义为负样本。
多分类
一个类别被定义为正类,其他类别的组合都是被定义为负类。
正样本应该是在建模过程中被识别出来的对象:例如在信用评分模型中,正样本包括拖欠债务的顾客,负样本就是剩下所有类别的顾客。
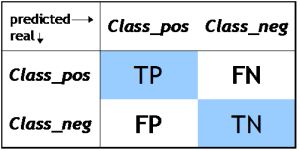
TP, TN, FP, FN
- TP —— 模型预测样本是正样本,这个样本的真实结果也是正样本;
比如:模型预测该客户是一个流失客户,然后实际情况是这个客户确实是一个流失掉的客户。 - TN —— 模型预测样本是负样本,这个样本的真实结果也是一个负样本;
比如:模型预测该客户不是一个流失客户,然后实际情况是这个客户确实不是一个流失掉的客户。 - FP —— 模型预测样本是正样本,这个样本的真实结果却是负样本;
比如:模型预测该客户是一个流失客户,然后实际情况是这个客户不是一个流失掉的客户。 - FN —— 模型预测样本是负样本,这个样本的真实结果是正样本;
比如:模型预测该客户不是一个流失客户,然后实际情况是这个客户确是一个流失掉的客户。
对于一个完美分类器来说,我们希望得到如下参数:
FP = 0
FN = 0
TP = 所有正样本的个数
TN = 所有负样本的个数
一些派生的质量指标
上面我们已经介绍了一些基本的质量指标,现在我们来介绍一些派生出来的质量指标。
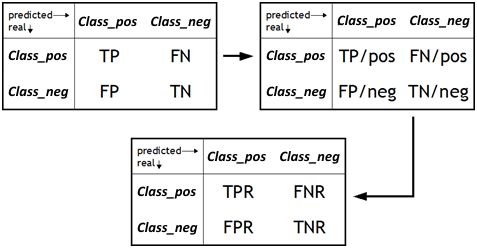
- TPR(True Positive Rate) —— 反映了分类器检测正样本的能力。
TPR = TP / (TP + FN) = TP / P,P 表示全部的正样本 - TNR(True Negative Rate) —— 反映了分类器检测负样本的能力。
TNR = TN / (TN + FP) = TN / N,N 表示全部的负样本 - FPR(False Positive Rate) —— 反映了分类器检测假正性的能力。
FPR = FP / (FP + TN) - FNR(False Negative Rate)—— 反映了分类器检测假负性的能力。
FNR = FN / (FN + TP)
- SE(敏感度)—— 反映了分类器检测正样本的能力。
SE = TP / (TP + FN) - SP (特异性)—— 反映了分类器检验负样本的能力
SP = TN / (TN + FP)
所以我们可以得到如下等式:
SE = TPR
SP = TNR
1 - SE = FNR
1 - SP = FPR
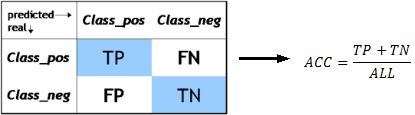
- ACC(总准确率)—— 反映了分类器的总体预测准确性,即进行正确预测的概率,也就是等于正确决策的个数与总决策个数的比例。
ACC = (TP + TN) / (TP + TN + FP + FN)
例子:如何去选择合适的评估指标
从上面我们可以看到,分类器有很多的评估质量的指标。那么如何选取当前模型的指标呢?这就变成了一个至关重要的问题。
例子
在客户流失分析模型中,我们的数据有两个类别:客户流失和客户不流失。假设我们有 100 个数据,那么:
- 90 个观察到的数据被标记为 “0”(正类)的类别,这个标记属于客户决定停止使用我们的服务或者产品;
- 10 个观察到的数据被标记为 “1”(负类)的类别,这个标记属于客户决定继续使用我们的服务或者产品;
然后,我们设计的分类器获得了如下结果:
TP = 85(85个被正确分类为正样本)
TN = 1(1个被正确分类为负样本)
FP = 9(9个原来是负样本的被分类为正样本)
FN = 5(5个原来是正样本的被分类为负样本)
上述指标总和是:
TP + TN + FP + FN = 100
我们现在计算分类的总体准确率:
ACC = (85 + 1)/ 100 = 0.86
86% 的准确率已经是一个不坏的结果了,但是让我们看一下另一个指标:TNR,这个指标反映了分类器检测负样本的能力,也就是在我们这个例子中会继续使用我们软件的客户:
TNR = 1 / 10 = 0.1
也就是说,只有一个不会流失的顾客被识别出来了,剩下的不流失的顾客都被错误分类了。如果从这个角度分析,那么这个模型是非常糟糕的一个模型。
所以,只有一个 ACC 是不能很准确来衡量一个模型的好坏的。
在接下来,我们将采用图形指标来分析模型的好坏。我们将从混淆矩阵开始,这是表示分类结果的最简单方法。
什么是混淆矩阵?
混淆矩阵是一个 N*N 矩阵,其中每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。每一列代表了模型预测得到的类别,每一列的总数表示预测为该类别的数据的数目。如下左上角的图,第一行第一列中的 85 表示有 85 个实际归属为第一类的数据被正确预测为了第一类。同理,第二行第一列中的 9 表示有 9 个实际是第二类的数据被错误预测为了第一类。
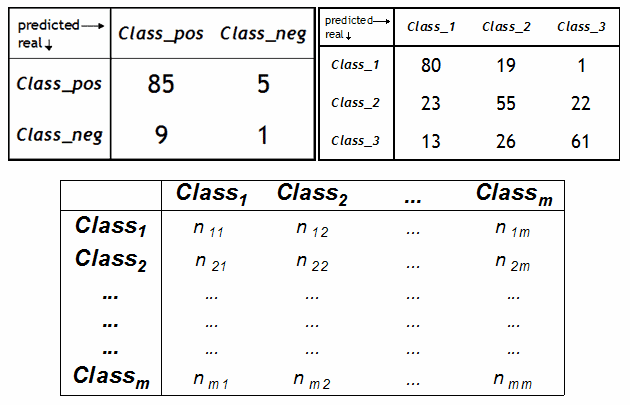
混淆矩阵的形式
各种形式的混淆矩阵让我们可以更加容易的观察分类模型性能的这种特征,主要有如下两种形式:
- 数字形式 —— 包含分配给特定类别的数字表示

- 百分数形式 —— 包含分配给特定类别的百分比,计算为分配给该类别的数量与总数量之间的比值。

- 收益和损失形式 —— 包含由于正确和错误的分类而产生的收益和损失信息。
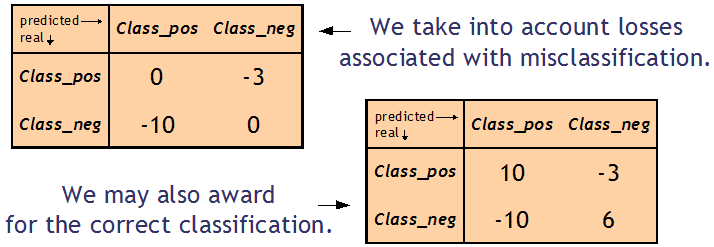
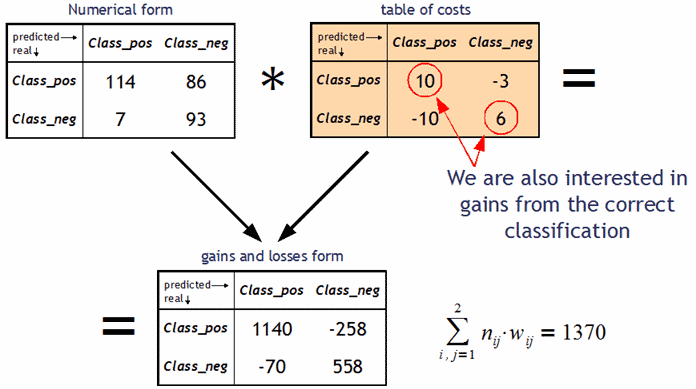
收益和损失形式中的混淆矩阵包含分类决策造成的成本总和。
接下来举几个例子。
例子1

例子2
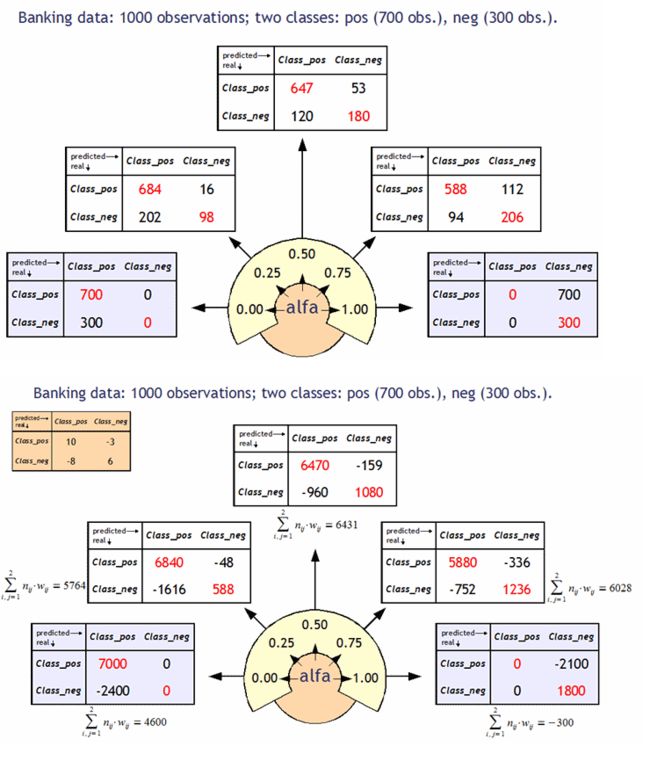
截止点和混淆矩阵
截止点是一个确定的阈值,可以用来确定一个观测属性是否属于一个特定的类别。
如果 P(class(x) = 1) > alfa,那么这个则分配给第一类。其中, alfa 就是一个截止点。P(class(x) = 1) 就是属于第一类的概率。
例如:
如果给定一个概率 60%,那么贷款申请人不善于偿还贷款的概率大于这个值(这个值是我们模型计算出来的),那么就将这个申请人转入坏账类别,否则将其转入好账类别。
对于相同的问题,我们可以考虑不同的截止点,这也将导致不同的混淆矩阵。通过分析这些矩阵我们就可以选择一个最佳的截止点。
混淆矩阵总结
- 收集分类结果的一种简单易懂的方法
- 使得分类模型的评估更加容易
- 混淆矩阵的不同形式可以帮助更好的观察分类器的性能
什么是 ROC 曲线?
ROC 曲线是分类质量可视化的另外一种方法,显示了 TPR 和 FPR 之间的依赖关系。
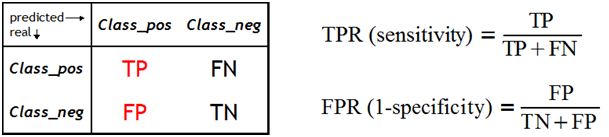
曲线越凸,分类器的性能越好。在下面的例子中,区域 1 中的 “绿色” 分类器更好,区域 2 中的 “红色” 分类器更好。
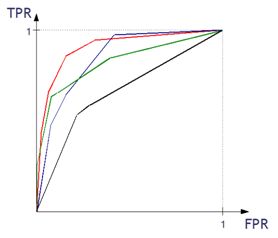
如何构建一条 ROC 曲线
- 我们需要计算决策函数的值;
- 我们测试不同的 alpha 阈值的分类器。回想一下,alpha 是估计概率的一个阈值,高于这个概率的观察值被分配到一个类别(正样本),低于这个阈值的概率被分配到另一个类别(负样本);
- 对于具有 alpha 阈值的每一个分类,我们获得(TPR,FPR)对,其对应于 ROC 曲线上的一个点。
- 对于每个具有 alpha 阈值的分类,我们也有相应的混淆矩阵;
例子


根据 ROC 曲线来评估分类器
分类质量可以使用 ROC 曲线下面的面积大小来计算衡量,这个曲线下的面积就是 AUC 系数。
AUC 系数越高越好。AUC = 1 意味着这是一个完美的分类器,我们把所有的东西都分类准确了。对于纯随机数的分类,我们的 AUC = 0.5。如果 AUC < 0.5,那么意味着这个分类器的性能比随机数还要差。
这里再说一个概念:基尼系数(Gini Coefficient),GC = 2 * AUC - 1。基尼系数越高,代表模型的效果越好。如果 GC = 1,那么这就是一个完美的模型了。如果 GC = 0,那么代表这只是一个随机数模型。

为什么使用ROC曲线
既然已经这么多评价标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。下图是ROC曲线和Precision-Recall曲线的对比:
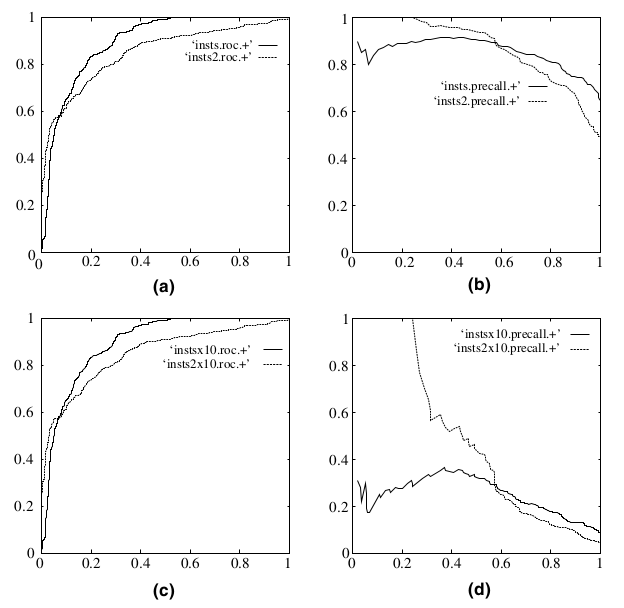
最后讲讲最常用的精确率和召回率

完整 PPT 可以关注微信公众号:coderpai,后台回复 20171223 获得。
来源:Data Science Central