Paragraph2vec(段向量)-------基于《Distributed Representations of Sentences and Documents》
目录
一、概要
1)背景
2)摘要
二、内容
1)传统的bag of words
2)本文的paragraph vector
3)算法
(1)word2vec的算法原理
(2)paragraph vector算法
三、总结
一、概要
1)背景
本文是我学习word2vec和paragraph2vec之后写下的一篇文章,如有错误,请指正以共同学习。
2)摘要
paragraph vector,顾名思义——段向量,是对段落的一种的向量化表示。如果之前对word vector了解较少,建议阅读《word2vec 的数学原理》。那么paragraph vector有什么用呢?说白了就是保存上下文信息。举个简单的例子,一个句子的下一个词是什么,一定只和本句子有关吗?答案自然是否定的。例如,一个句子为:那是(),请填空。显然,根据句子本身无法推断出括号里需要填的是什么,有可能那是猪,也有可能那是猫。这就需要根据整个段落的信息来判断到底是猪还是猫了。这个时候,段向量就派上了用场。
本文主要是根据Mikolov的《Distributed Representations of Sentences and Documents》总结得到的。其英文原文很容易阅读,英语不错的同学建议直接阅读原文(强烈推荐作者其他关于word embedding的的文章)。
论文百度网盘链接:https://pan.baidu.com/s/1mY3QwUzbRLD9gYcYPhf9mA 密码:nns4。
二、内容
1)传统的bag of words
词袋模型:对于一个文本,忽略词序和文法,将整个文本仅仅看作一些词语的集合。显然,这种模型的局限性很大。例如对于词序,“草吃牛”和“牛吃草”的意义相去甚远,但是在词袋模型中并不考虑词序,因此词袋模型将其同一对待。
2)本文的paragraph vector
本文所介绍的paragraph vector的特点如下:
1、能为不同长度的段落训练出同一长度的向量(具体这个向量的含义是什么,没人能解释清楚)。
2、不同段落的词向量不共享。说白了就是,每出现一个新段落,就要训练一个新的向量与之对应。其实也很好理解,不同段落的主题的不一样,其段向量自然不一样。
3、词向量共享。根据训练集训练出来的词向量在任何地方都是通用的,不同段落的同一词语的意思应该是一致的,所以词向量不变。
3)算法
(1)word2vec的算法原理
本文不是讲解word2vec的,因此在这里只是简要提一下。如有不懂,强烈建议阅读《word2vec 的数学原理》。
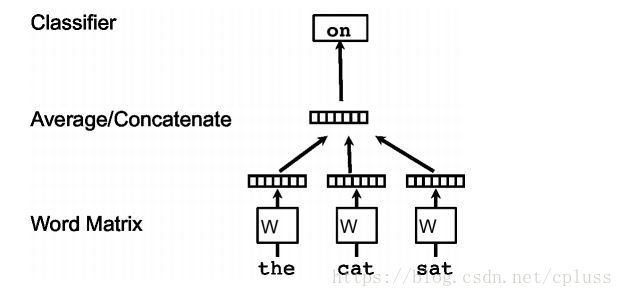
其主要作用机理如图所示。假设要预测“the cat sat”的下一个单词“on”:
输入:"the"、"cat"、"sat"的词向量。(实际情况可能还要输入on后面的单词。也有人可能会问,不是要求这些单词的词向量吗,怎么变成了输入呢。其实初始时,要求给每个单词初始化一个随机向量,然后通过BP算法不断调整,最后得到的向量才是我们想要的)
中间层:将输入的向量求和;将输入的向量求和再平均;将输入的向量按顺序连接起来。以上三种方法都有可能出现,讲道理第三种应该是最合适的,因为连接保留了顺序信息,但对应的参数量也会变大,所以效率和精度实在难以兼顾。
输出层:根据softmax函数计算概率。
优化:根据BP算法,使这个网络输出为"on"的概率不断变大,直到收敛或者满足条件。此时得到的向量便是我们所需要的词向量。
注:无论是CBOW还是skip_gram都只是模型(上图对应CBOW模型)。而针对这两种模型,都有不同的优化方法,例如Hierarchical Softmax和Negative sampling方法。
(2)paragraph vector算法
理解了上面的算法,剩下的就简单了。
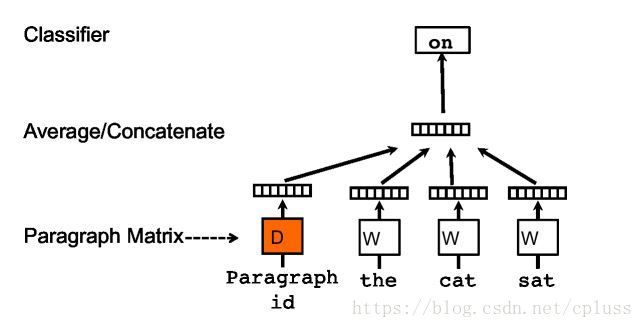
其差别就是在一个输入上:多了一个paragraph vector。将此段向量和其他词向量通过拼接或相加的方式输入到隐藏层,然后根据softmax函数计算输出层的概率。算法和上面的一样,只不过多了一个输入。
注意点:
1、测试时,会出现不同的段落。例如,我们要测试the dog sat 的下一个单词,这个句子出现在段落P中,但段落P在之前并未出现过,也就是我们尚不知道段落P的向量("the"、“dog”,“ sat”的词向量都是知道的,已经训练出来了)。此时的做法是固定词向量,只将段向量当作变量来进行BP算法,直到收敛,得到最终的段向量。再根据这个新训练的段向量去进行预测。
2、论文中提到,将CBOW和Skip_gram模型结合起来一起来训练段向量效果更佳。
3、主要的算法流程如上,具体实施时会进行很多优化,例如霍夫曼树的使用。
三、总结
论文中提到的段向量的算法只是众多段向量算法的一种。而这个算法又是由word2vec演化而来的,所以理解了word2vec之后,再来了解这个算法就会很容易。但是至今为止,词向量乃至神经网络都缺少现实的理论基础(现实意义?),例如我们得到的词向量或者段向量的每一维到底代表什么,都无从得知。所以,词向量还有很长的路要走!!再说点题外话,BP算法类似于现实中的负反馈调节,根据结果不断调整参数,让参数去适应结果。词向量的训练亦是如此。但是,我们是否可以从另一个角度出发:我们能否为语言设计一个数据结构(类似向量这种),使得这种数据结构在数学上的意义和在现实中的意义一致,然后我们用这种数据去预测或者翻译就简单多了(因为计算机能够理解其数学意义,而数学意义又对应着现实意义)。当然这是一种猜测(用word2vec训练出的词向量在数学意义上确实达到了某种一致,例如同义的词语其欧式距离会很接近)。