CVPR 2018 最酷的十篇论文

本文为 AI 研习社编译的技术博客,原标题 :
The 10 coolest papers from CVPR 2018
作者 | George Seif
翻译 | Vincents 校对 | 邓普斯•杰弗
审核 | 永恒如新的日常 整理 | Pita
原文链接:
https://towardsdatascience.com/the-10-coolest-papers-from-cvpr-2018-11cb48585a49
2018年计算机视觉和模式识别会议(CVPR)上周在美国盐湖城举行。该会议是计算机视觉领域的世界顶级会议。今年,CVPR 收到3300篇主要会议论文并且最终被接收的论文多达 979 篇。超过6,500人参加了会议,这可以说是史诗级的大规模! 6500人在下图的会议厅参会:

CVPR2018大会会场
每年,CVPR都会带来优秀的人才以及他们很棒的研究; 并且总能看到和学习到一些新的东西。当然,每年都有一些论文发表新的突破性成果,并为该领域带来一些很有用的新知识。 这些论文经常在计算机视觉的许多子领域带来最先进的前沿技术。
最近,喜闻乐见的是那些开箱即用的创意论文!随着深度学习在计算机视觉领域的不断应用,我们仍然在探索各种可能性。许多论文将展示深度网络在计算机视觉中的全新应用。 它们可能不是根本上的突破性作品,但它们很有趣,并且可以为该领域提供创造性和启发性的视角,从它们呈现的新角度经常可以引发新的想法。总而言之,它们非常酷!
在这里,我将向您展示我认为在2018年CVPR上的10篇最酷论文。我们将看到最近才使用的深度网络实现的新应用,以及其他的一些提供了新的使用方法和技巧的应用。您可能会在此过程中从中获得一些新想法;)。话不多说,让我们开始吧!
使用合成数据训练深度网络:通过域随机化弥合现实差距
本文来自Nvidia,充分利用合成数据来训练卷积神经网络(CNN)。 他们为虚幻引擎4创建了一个插件,该插件将生成综合训练数据。 真正的关键是他们随机化了许多训练数据中可以包含的变量,包括:
对象的数量和类型
干扰物的数量,类型,颜色和尺度
感兴趣的对象和背景照片的纹理
虚拟相机相对于场景的位置
相机相对于场景的角度
点光源的数量和位置
他们展示了一些非常有前景的结果,证明了合成数据预训练的有效性; 达到了前所未有的结果。 这也为没有重要数据来源时提供了一种思路:生成并使用合成数据。

图片来自论文:使用合成数据训练深度网络:通过域随机化弥合现实差距
WESPE:用于数码相机的弱监督照片增强器
这篇非常精妙!研究人员训练了一个生成对抗网络(GAN),能够自动美化图片。最酷的部分是,它是弱监督的,你不需要有输入和输出的图像对!想要训练网络,你只需要拥有一套“好看”的图片(用于输出的正确标注)和一套想进一步调整的“粗糙”的图片(用于输入图像)。生成对抗网络被训练成输出输入图像更符合审美的版本,通常是改进色彩和图片的对比度。
这一模型非常简单并且能快速上手,因为你不需要精确的图像对,并且最终会得到一个“通用的"图片增强器。我还喜欢这篇论文的一点是它是弱监督的方法,非监督学习看起来很遥远。但是对计算机视觉领域的许多子类来说,弱监督似乎是一个更可靠更有希望的方向。

图片来自论文:WESPE:用于数码相机的弱监督照片增强器
用Polygon-RNN ++实现分段数据集的高效交互式标注
深度网络能够良好运行的一个主要原因是有大型的经过标注的可用的数据集。然而对很多机器视觉任务来说,想获得这样的数据会很耗费时间并且成本高昂。特别是分割的数据需要对图片中的每个像素进行分类标注。所以对大型数据集来说,你可以想象......标注任务永远不可能标完!
Polygon-RNN++能够让你在图中每个目标物体的周围大致圈出多边形形状,然后网络会自动生成分割的标注!论文中表明,这一方法的表现非常不错,并且能在分割任务中快速生成简单标注!

图片来自论文:用Polygon-RNN ++实现分段数据集的高效交互式标注
从时尚图片创造胶囊衣柜
“嗯......今天我该穿什么?” 如果某人或某个东西能够每天早上为你回答这个问题,那么你不必再去问这个问题,会不会很好?这样的话你就不用了吗?那么我们就跟胶囊衣柜(Capsule Wardrobes)打个招呼吧!
在这篇论文中,作者设计了一个模型,给出候选服装和配件的清单,可以对单品进行组合,提供最大可能的混合搭配方案。它基本上使用目标函数进行训练,这些目标函数旨在捕获视觉兼容性,多功能性和用户特定偏好的关键要素。 有了胶囊衣柜,您可以轻松地从衣柜中获得最适合您的服装搭配!

图片来源论文:从时尚图片中创造胶囊衣柜
Super SloMo:视频插值中多个中间帧的高质量估计
你曾经是否想过以超慢的动作拍摄超级酷炫的东西呢?Nvdia 的这项研究 Super SloMo 就能帮你实现!研究中他们使用 CNN 估计视频的中间帧,并能将标准的 30fps 视频转换为 240fps 的慢动作!该模型估计视频中间帧之间的光流信息,并在这些信息中间插入视频帧,使慢动作的视频看起来也能清晰锐利。

一颗子弹穿过一个鸡蛋,Super SloMo!
是谁放狗出去?用视觉数据构建狗的行为模型
这可能是有史以来最酷的研究论文!这项研究的想法是试图模拟狗的思想和行为。研究人员将许多传感器连接到狗的四肢以收集其运动和行为数据。此外,他们还在狗的头部安装一个摄像头,以便看到和从狗的第一人称视角所看到的世界相同。然后,将一组 CNN 特征提取器用于从视频帧获取图像特征,并将其与传感器数据一起传递给一组 LSTM 模型,以便学习并预测狗的动作和行为。这是一项非常新颖而富有创造性的应用研究,其整体的任务框架及独特的执行方式都是本文的亮点!希望这项研究能够为我们未来收集数据和应用深度学习技术的方式带来更多的创造力。
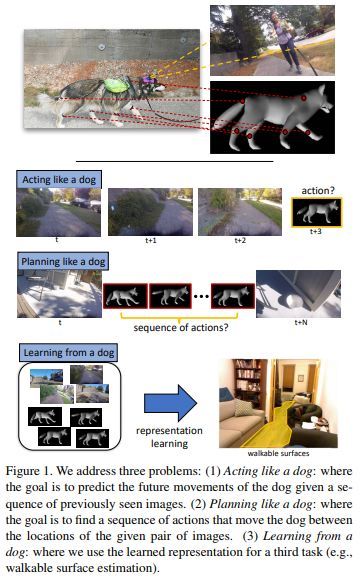
图片来自论文:用视觉数据构建狗的行为模型
学习分割一切
在过去的几年里,何凯明团队 (以前在微软研究院,现就职于 Facebook AI Research) 提出了许多重大的计算机视觉研究成果。他们的研究最棒之处在于将创造力和简单性相结合,诸如将 ResNets和 Mask R-CNN 相结合的研究,这些都不是最疯狂或最复杂的研究思路,但是它们简单易行,并在实践中非常有效。 这一次也不例外。
该团队最新的研究 Learning to Segment Every Thing 是 MaskR-CNN 研究的扩展,它使模型准确地分割训练期间未出现的类别目标!这对于获取快速且廉价的分割数据标注是非常有用的。事实上,该研究能够获得一些未知目标的基准分割效果,这对于在自然条件中部署这样的分割模型来说是至关重要的,因为在这样的环境下可能存在许多未知的目标。总的来说,这绝对是我们思考如何充分利用深层神经网络模型的正确方向。

图片来自论文: 学习分割一切
桌上足球
本文的研究是在 FIFA 世界杯开幕时正式发表的,理应获得最佳时机奖!这的确是 CVPR 上在计算机视觉领域的“更酷”应用之一。简而言之,作者训练了一个模型,在给定足球比赛视频的情况下,该模型能够输出相应视频的动态 3D 重建,这意味着你可以利用增强现实技术在任何地方查看它!
本文最大的亮点是结合使用许多不同类型的信息。使用视频比赛数据训练网络,从而相当容易地提取 3D 网格信息。在测试时,提取运动员的边界框,姿势及跨越多个帧的运动轨迹以便分割运动员。接着你可以轻松地将这些 3D 片段投射到任何平面上。在这种情况下,你可以通过制作虚拟的足球场,以便在 AR 条件下观看的足球比赛!在我看来,这是一种使用合成数据进行训练的聪明方法。无论如何它都是一个有趣的应用程序!

图片来自论文:桌上足球
LayoutNet:从单个 RGB 图像重建 3D 房间布局
这是一个计算机视觉的应用程序,我们可能曾经想过:使用相机拍摄某些东西,然后用数字 3D 技术重建它。这也正是本文研究的目的,特别是重建3D 房间布局。研究人员使用全景图像作为网络的输入,以获得房间的完整视图。网络的输出是 3D 重建后的房间布局,具有相当高的准确性!该模型足够强大,可以推广到不同形状、包含许多不同家具的房间。这是一个有趣而好玩、又不需要投入太多研究人员就能实现的应用。

图片来自论文:LayoutNet:从单个 RGB 图像重建 3D 房间布局
学习可迁移的结构用于可扩展的图像识别任务
最后要介绍的是一项许多人都认为是深度学习未来的研究:神经架构搜索 (NAS)。NAS 背后的基本思想是我们可以使用另一个网络来“搜索”最佳的模型结构,而不需要手动地设计网络结构。这个搜索过程是基于奖励函数进行的,通过奖励模型以使其在验证数据集上有良好的表现。此外,作者在论文中表明,这种模型结构比起手动设计的模型能够获得更高的精度。这将是未来巨大的研究方向,特别是对于设计特定的应用程序而言。因为我们真正关注的是设计好的 NAS 算法,而不是为我们特定的应用设计特定的网络。精心设计的 NAS 算法将足够灵活,并能够为任何特定任务找到良好的网络结构。
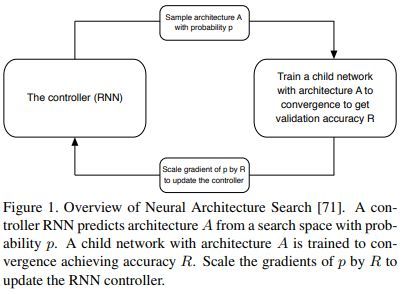
图片来自论文:学习可迁移的结构用于可扩展的图像识别任务
结语
感谢您的阅读! 希望您学到了一些新的有用的东西,甚至可能为你自己的工作找到了一些新的想法!如果您觉得不错,请分享给更多人可以看到这篇文章,并与我们一起跳上学习的列车!
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击【CVPR 2018 最酷的十篇论文】:
https://ai.yanxishe.com/page/TextTranslation/1306
AI研习社每日更新精彩内容,观看更多精彩内容:雷锋网雷锋网雷锋网(公众号:雷锋网)
盘点图像分类的窍门
深度学习目标检测算法综述
生成模型:基于单张图片找到物体位置
注意力的动画解析(以机器翻译为例)
等你来译:
如何在神经NLP处理中引用语义结构
(Python)用Mask R-CNN检测空闲车位
高级DQNs:利用深度强化学习玩吃豆人游戏
深度强化学习新趋势:谷歌如何把好奇心引入强化学习智能体