8个深度学习方面的最佳实践
点击上方“CSDN”,选择“置顶公众号”
关键时刻,第一时间送达!
本文经授权转自CSDN技术头条。
我很开心自己在过去的2017年中在人工智能领域获得的成就。我也学了不少数学方面的知识,虽然这也很有趣,但由于没有做实际的项目,所以并没有什么成果可以说明我在这方面的努力。为了弥补这一点,我在4月份申请了AI Grant(译者注:AI Grant是一家专注于人工智能的风险投资公司),目的是为肯尼亚语言建立FastText skip-gram模型。我在第一轮就进入了决赛,但最终并没有获得奖金。
接着,在9月份,我申请了深度学习编码实践(第一部分,v2)课程,讲师是fast.ai(http://fast.ai/)的杰里米·霍华德(Jeremy Howard)。它将在2018年1月的头两周左右作为MOOC(大型开放式网络课程)公开发布。经过七个多星期的学习,我学会了如何利用8个技巧来构建:
基于预先训练模型的世界级图像分类器
基于数据集构建语言模型的情感分析工具
如何对结构化数据集进行深度学习
如何使用深度学习通过协同过滤来构建推荐引擎
所有这一切都是通过由fastai深度学习库支持的Jupyter Notebook完成的,该库本身是基于PyTorch的。
本文将介绍这8个技巧。对于每个技巧,我将用一小段“fastai”代码来概括主要思想,并在括号中指出该技巧是否普遍适用(在图像识别和分类、自然语言处理、建模结构数据或协同过滤中是否有用),或者更具体到深度学习的数据类型。在课程中,图像识别课程涉及到了Kaggle竞赛的狗与猫:内核版本、 狗品种的鉴定和星球:根据太空认识亚马逊。
现在是互联网的时代,所以我使用了“狗与猫”这个竞赛,并用蜘蛛与蝎子来代替狗和猫。我通过搜索“蜘蛛”和“沙漠蝎子”在Google Images上抓取数据,下载了大概1500张图片。显然,这整个过程都是自动的。然后,通过删除非jpg图像、非图像的文件和没有扩展名的图像来清理数据。在完成了垃圾清理之后,大约剩下了815张图片。每个[spiders, scorpions]训练集分类中有290张图片,在测试集/验证集中有118个蜘蛛和117个蝎子。令人惊讶的是,这竟然可以用!我的模型达到了95%的准确度。
from fastai.imports import *
from fastai.transforms import *
from fastai.conv_learner import *
from fastai.model import *
from fastai.dataset import *
from fastai.sgdr import *
from fastai.plots import *
sz=224 # image size
# architecture, from https://github.com/facebookresearch/ResNeXt
arch=resnext50
# batch size
bs=64
PATH = 'data/spiderscorpions/'
# Enable data augmentation, and precompute=True
# transforms_side_on flips the image along the vertical axis
# max_zoom: 1.1 makes images up to 10% larger
tfms = tfms_from_model(arch, sz, aug_tfms=transforms_side_on, max_zoom=1.1)
data=ImageClassifierData.from_paths(PATH,tfms=tfms)
learn = ConvLearner.pretrained(arch, data, precompute=True)
# Use lr_find() to find highest learning rate where loss is still clearly improving
learn.lr_find()
# check the plot to find the learning rate where the losss is still improving
learn.sched.plot()
# assuming the optimal learning rate is 0.01, train for 3 epochs
learn.fit(0.01, 3)
# train last layer with data augmentation (i.e. precompute=False) for 2-3 epochs with cycle_len=1
learn.precompute=False
learn.fit(1e-2, 3, cycle_len=1)
# unfreeze all layers, thus opening up resnext50's original ImageNet weights for the
# features in the two spider and scorpion classes
learn.unfreeze()
lr = 0.01
# fastai groups the layers in all of the pre-packaged pretrained convolutional networks into three groups
# retrain the three layer groups in resnext50 using these learning rates for each group
# We set earlier layers to 3x-10x lower learning rate than next higher layer
lrs = np.array([lr/9, lr/3, lr])
learn.fit(lrs, 3)
# Use lr_find() again
learn.lr_find()
learn.sched.plot()
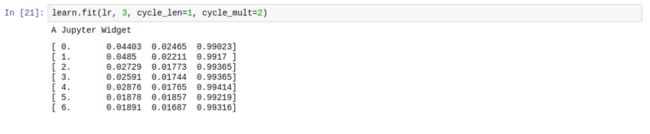
learn.fit(1e-2, 3, cycle_len=1, cycle_mult=2)
log_preds,y = learn.TTA()
preds = np.mean(np.exp(log_preds),0)
accuracy(log_preds, y)
1. 通过微调VGG-16和ResNext50来转移学习(计算机视觉和图像分类)
对于图像分类这个工作,需要具体问题具体分析,通过仔细的微调可以得到一个性能优良的神经网络架构。比如残差网络ResNext50(https://arxiv.org/abs/1611.05431),它是一个50层的卷积神经网络。由于它在1000个ImageNet挑战类别上进行了训练,所以表现非常好,从图像数据中提取的特征能够得以重用。为了让ResNext50能够适用于我这个问题,需要用输出二维向量的图层替换最后一个输出一个1000维向量的ImageNet预测的图层。这两个输出类在上面的代码片段中的PATH中指定。对于蜘蛛与蝎子这个问题,有以下两个目录:
$ ls -lsh data/spiderscorpions/train/
128K drwxrwxrwx 1 bmn bmn 128K Jan 3 00:22 scorpions
148K drwxrwxrwx 1 bmn bmn 148K Jan 3 00:22 spiders
请注意,train目录下的两个子目录各包含了290张图片。
这是微调程序的示例图,它重新训练一个10维的最终图层:
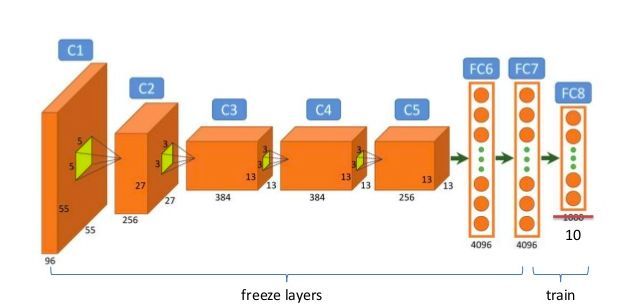
图片来自:https://image.slidesharecdn.com/practicaldeeplearning-160329181459/95/practical-deep-learning-16-638.jpg
2. 周期性学习率(普遍适用)
学习率也许是对深度神经网络进行调优最重要的一个超参数。在非自适应的环境下(即不使用Adam、AdaDelta或它们的变体),通常由深度学习研究人员并行运行多个试验,每个试验在学习速率上有着很小的差异。如果数据集非常庞大,并且非常容易出错,如果你对于用随机矩阵建立直觉的方法不熟悉的话,这会花费很长的时间。然而,2015年,美国海军研究实验室的莱斯利·N·史密斯(Leslie N. Smith)发现了一种自动搜索最优学习率的方法(http://arxiv.org/abs/1506.01186),即通过网络运行一些小的批次,每次都调整学习速度,同时跟踪损失的变化情况,直到损失出现下降。这里(http://teleported.in/posts/cyclic-learning-rate/)和这里(https://techburst.io/improving-the-way-we-work-with-learning-rate-5e99554f163b)有两位fast.ai学生解释周期性学习率方法的博客文章。
在fastai上,你可以通过在学习对象上运行lr_find(),并利用sched.plot()来识别与最优学习速率一致的点。下面是屏幕截图:
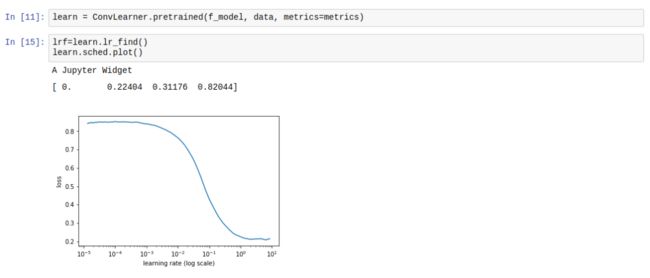
0.1似乎是一个很好的学习率
根据循环学习速度论文可以看出,它的表现非常不错,达到了非常高的准确性,并且是学习速度呈指数级衰减的两倍以上。
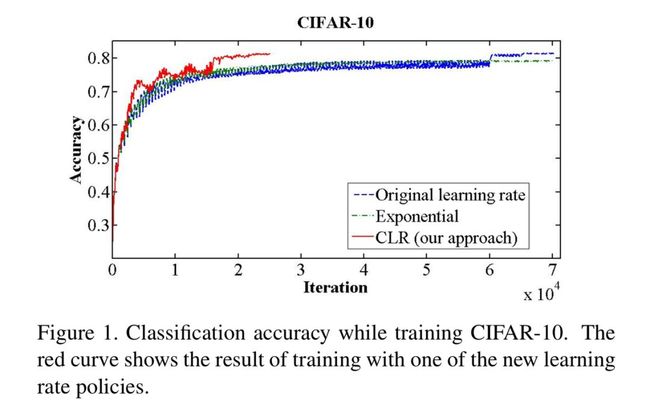
图1 莱斯利·N·史密斯(2017)的“用于训练神经网络的周期性学习速率”
3. 带重启的随机梯度下降(普遍适用)
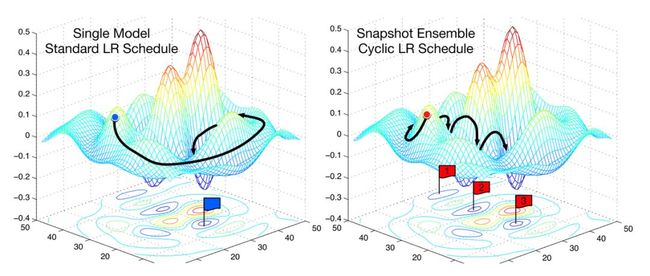
图2 SGD与快照集成(Huang等,2017)
加速随机梯度下降的另一种方法是在训练过程中逐步降低学习的速率。这个方法有助于我们观察学习速度的变化与损失的改善是否一致。越接近最佳权重,则调整的幅度越小;一旦调整的幅度过大,则很有可能会跳过误差曲面的最佳范围。如果学习速率和损失之间的关系不稳定,例如学习速率的一个小小的变化会让损失产生较大的变化,那么说明我们并不是在一个稳定的区域中(上面的图2)。那么这个策略就会周期性地提高学习率。这里的“周期”决定了提高学习速率需要达到的次数。这就是周期性的学习速率计划。在fastai中,这是通过设置learner.fit中的cycle_len和cycle_mult参数来实现的。在上面的图2中,学习速率被重置3次。在使用正常的学习速率计划时,通常需要更长的时间才能找到最佳的损失,开发人员需要等待所有的周期都完成后才能手动尝试不同的学习速率。
4. 数据增强(计算机视觉和图像分类)
数据增强是一种增加训练和测试数据数量的简单方法。对于图像来说,这取决于具体的学习问题,因此,取决于数据集中图像的对称数量,比如蜘蛛与蝎子这个问题。这被称为transforms_side_on。例如:
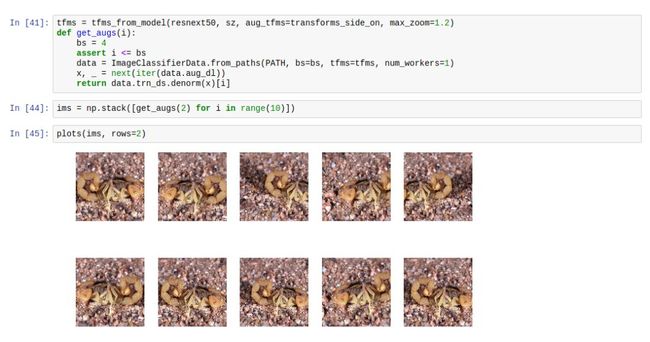
注意不同的角度和缩放。
5. 测试时间增强(计算机视觉和图像分类)
我们也可以在推理时间(或测试时间)内使用数据增强。在推理时间内,需要做的就是做出预测。你可以使用测试集中的单个图像来完成此操作,但是如果在访问的测试集中随机生成每个图像的几个增强图像,则该过程会变得更加健壮。在fastai里,在测试过程中会用到每个测试图像的4个随机增强图像,并且将预测的平均值用作该图像的预测值。
6. 用预训练的循环神经网络替换词向量
在不涉及词向量的情况下,我们照样可以得到世界级的情感分析框架,那就是把要分析的整个训练数据集合在一起,并基于此构建一个深度循环神经网络语言模型。当模型达到较高精度的时候,保存模型的编码器,并使用从编码器获得的嵌入层来构建情感分析模型。这比从词向量获得的嵌入矩阵更好,因为循环神经网络可以比词向量更好地跟踪长距离依赖性。
7. 时间反向传播(BPTT)(自然语言处理)
如果在反向传播了一些时间步长之后未复位的话,深度循环神经网络中的隐藏状态可能会变得难以处理。例如,在字符级的循环神经网络中,如果有一百万个字符,那么就会有一百万个隐藏的状态向量,每个状态向量都有自己的历史信息。为了调整神经网络的梯度,我们需要对每个字符每个批次执行链规则的一百万次计算。这会消耗很多很多的内存。所以,为了降低内存占用,我们设置了最大反向传播字符数。由于循环神经网络中的每个循环周期被称为时间步长,所以,限制反向传播保持隐藏状态历史层数的任务被称为时间反向传播。这个数值决定了模型计算的时间和内存要求,但它提高了模型处理长句或动作序列的能力。
8. 分类变量的实体嵌入 (结构化数据和自然语言处理)
在对结构化数据集进行深度学习时,这有助于将包含连续数据的列(例如在线商店中的价格信息)从包含分类数据(例如日期和取货地点)的列中区分出来。然后,可以将这些分类列的独热编码过程转换为指向神经网络的完全连接嵌入层的查找表。这样,神经网络就有机会了解那些被忽略的分类变量或者列。它可以学习到周期性事件,例如根据多年的数据获得一周中的哪一天销售量最大、假期之前和之后发生了什么。这是预测产品最优定价和协同过滤的一个非常有效的方法。这应该也是所有拥有表格数据的公司的标准数据分析方法和预测方法。
这个方法被应用在了郭和伯克恩的Rossmann Store SalesKaggle(https://www.kaggle.com/c/rossmann-store-sales)比赛中。他们只使用了深度学习以及最少的特征工程,但还是获得了第三名。在这篇论文(https://arxiv.org/abs/1604.06737)中介绍了他们的方法。
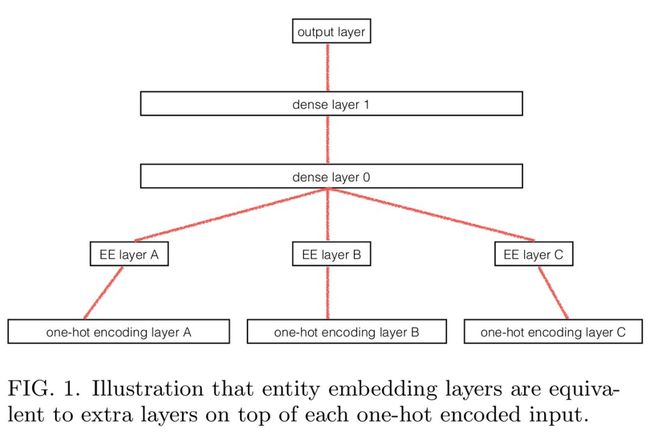
Guo, Berkhahn (2016) (https://arxiv.org/abs/1604.06737)
结语
随着相关的库变得越来越好,人工智能的子领域深度学习也在变得越来越容易学习。我个人认为,最有潜力的领域是教育和医学,尤其是在生物技术方面。我们将会变得更聪明、更富有,并且在本世纪末将会因为这些工具而变得更长寿,更健康。
作者:Muhia
翻译:雁惊鸿

