学术 | 一种新的CNN网络可以更高效地区分自然图像&生成图像

作者 | Weize Quan , Kai Wang, Dong-Ming Yan , Xiaopeng Zhang
译者 | linstancy
编辑 | Jane
出品 | AI 科技大本营
【导读】传统的肉眼识别方法是很难直接识别出 NIs (自然图像) 和 CG (计算机生成的图像)。本文中提出了一种高效的、基于卷积神经网络 (CNN) 的图像识别方法。通过大量的实验来评估模型的性能。实验结果表明,该方法优于现有的其他识别方法,与传统方法中采用 CNN 模型来识别图像,此方法还能借助高级可视化工具。
▌ 摘要
考虑到对现有的 CCNs 从头开始训练或微调预训练网络都具有一定的局限性,这个研究提出了一种更合适的想法:设计阶段在 CNN 模型的底部增加了两个级联卷积层。该网络能够根据不同大小的图像输入,进行自适应地调整,同时保持固定的深度,以稳定 CNN 结构并实现良好的识别表现。对于所提出的模型,我们采用一种称为“局部到全局”的策略,即 CNN 能够获取局部图像的识别决策,而全局的识别决策可通过简单的投票方式获得。我们通过大量的实验来评估模型的性能。实验结果表明,该方法优于现有的其他识别方法,且在后处理的图像上也具有较好的鲁棒性。此外,相比于传统方法中采用 CNN 模型来识别图像,我们的方法还能借助高级可视化工具,进一步可视化地了解 NIs 与 CG 之间的差异。
▌简介
当前,对 NIs 和 CG 的图像识别研究已经得到了广泛的关注。解决这个问题的主要挑战在于 NIs 与 CG 有近乎相同的写实性及图像模式。先前的研究通常都是人工设计一些可判别的特征,来区别 NIs 和 CG。但这些方法普遍存在的问题是人为设计的特征对于给定的图像识别问题来说,并不一定是最适合的,特别对于一些复杂的数据库而言,该方法的识别效果更差。
相比于需要先验知识和假设条件的传统方法,卷积神经网络 (CNN) 能够自动地从数据中学习目标的特征及其抽象表征,这使得它能够更广泛适用于一些复杂的数据库。本文,我们提出一种基于 CNN 的框架来识别 NIs 和 CG。这是一种以端到端的方式进行自动特征学习,而无需进行人为设计图像特征的框架。我们的工作主要总结如下:
-
提出了一种基于 CNN 的 NIs 与 CG 的通用识别框架,通过微调它能够自适应于不同尺寸的图像输入块。
-
对微调训练后的 CNN 模型,我们针对性地设计了一种改进方案以改进我们的识别表现,这两种基于 CNN 的方案都优于目前最先进的方法。
-
我们的方法在 Google 和 PRCG 数据库上都表现出良好的识别性能,而且对调整图像大小和压缩 JPEG 等后处理操作有强大的鲁棒性。
-
利用可视化工具,我们进一步地了解 CNN 模型是如何区分 NIs 和 CG。
▌数据集
我们使用的实验数据包括 Columbia Photo-graphic 与 PRCG 数据库。数据库由三组图像组成:(1) 从40个 3D 图形网站中获取的800张 PRCGs 数据;(2) 我们所采集的800张 NIs;以及 (3) 从 Google 搜索中获取的795张摄影图像。
我们所采集的300张 NIs 是通过小型数码相机拍摄的。先前研究的方法都没有在 Google 与 PRCG 数据库上进行过测试,这是因为 Google中的 NIs 与PRCG中的CG图像起源不同。而我们的研究不仅尝试解决这个问题,而且还将在 Personal 与 PRCG ,以及 Personal+Google 与 PRCG 两种不同数据库组合条件下进行测试。
▌框架
我们将 NIs 与 CG 的图像识别问题视为是一个二元分类问题。针对此问题,提出了两种不同的图像识别标准框架,如图1所示:其中,f 是特征提取器,c 代表一个分类器 (如 SVM) 。我们的框架是一个二阶段模型,其核心在于特征提取器。通常,特征的提取过程不仅需要耗费大量的时间,且提取出来的特征不一定是我们任务所需要的,而我们的 CNN 框架能够以端到端的方式自动学习并提取所需特征,这为解决特征提取问题提供了一种思路。因此,我们提出了一种适用的 CNN 模型,并采用以下三种不同的训练方法:(1) 遵循现有的网络结构,并从头开始训练 CNN 模型;(2) 微调一个预先在其他数据集或另外一个任务中训练好的、现成的 CNN 网络;(3) 设计一个新的网络,并从头开始训练。
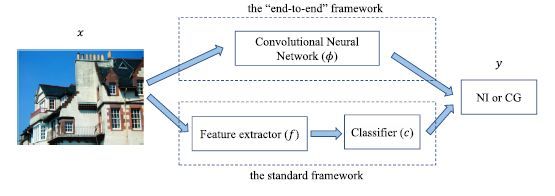
图1 两种不同的图像识别框架
局部到全局策略
考虑到模型的计算成本,图片尺寸的多样性以及图像识别的性能要求,我们采用一种由局部到全局的策略,来对局部图像进行训练并使用简单的投票规则再对全局的图像进行分类。这种由局部到全局的策略是一种基于数据增强的思想,也是扩展训练中的常用技巧,尤其是在深度学习领域。
对于图像分类问题,局部策略 (即高精度的局部图像) 对于图像识别来说是非常重要的;另一方面,从 CG 上裁剪下来的图像本质仍是 CG,而对 Nis 而言也是如此。因此,我们引入数据增强的方法,也就是说,从每次训练中选择一些固定尺寸的图像去增强训练数据集,并且尽可能地去获取更高精度的图像。在实践阶段,我们使用 Maximal Poisson-disk 从每次训练中随机裁剪一定数量的图像来构建新的训练数据集。在测试阶段,从每个测试图像中裁剪一定数量的局部图像,并给每张局部图像加上特定的标签 ( CG 属于0,而 NI 属于1 ),编号较高的标签作为该图像的预测结果。
网络结构
我们所采用的网络结构由 ConvFilter 层,3个卷积层组,2层 FC 层以及1个softmax 分类层组成,模型的输入是二进制的图片格式。其结构如下图2所示:我们的输入是一张233*233的 RGB 图像,用绿色方块表示;红色方块代表卷积核,靠近它的数字代表该卷积核的尺寸,左侧的红色方块代表一个7*7的卷积核;特征图则由阴影部分的长方体所示。

图2 我们的网络结构
▌实验结果
实验设置与细节
我们使用了双三次插值来调整所有图像的大小,调整后的图片的较短边像素值为512,以此确保所有图像的大小一致性。基于原始数据集,我们以 3:1 的分离率来设置训练集和测试集,并用 MPS 从每张训练数据中裁剪出 200 张,以满足局部到全局策略的需要并达到扩充训练数据的目的。同样地,从每张测试数据中裁剪出 30 张来作为测试集。在训练时,我们采用128的批次大小,学习率设置为0.001,每 30k 次迭代学习率就除以10,直到迭代完 90k 次为止。此外,除了 60×60 和 30×30 图像块大小的正则化设置为 5e-5 和 1e-5 外,其余的正则化权重的默认值为 1e-4。
微调 CaffeNet 和卷积滤波器层的性能分析
微调后的 CaffeNet 的测试结果如下表 1 所示。我们可以看到,微调后网络 (C-1 到 C-7) 的测试性能要优于从头开始训练的网络 (C-S) 实验结果,这可能是由于预训练期间学习大量 NI 对模型的特征学习是有益的。而相比于传统方法 (准确率最高80.65%),通过微调后,我们的网络性能更佳,准确率更高。

表1 模型的分类精度,其中 C 表示 CaffeNet,”C-S” 表示从头开始训练网络 CaffeNet,”C-N” 表示微调 CaffeNet 后的前 N 层网络,N 从1到7。
此外,我们还对 ConvFilter 层进行了四种不同的配置: (1) 两个级联卷积层;(2) 删除 convFilter 层;(3) convFilter 层之后接 ReLU 激活层;以及(4) convFilter 层中加入高通滤波器。下表2 显示了这四种配置相对应的模型性能,其中使用两个级联卷积层时模型的准确率最高。

表2 四种不同配置下的 convFilter 的分类精度
不同尺寸图像块上的分类性能
下图 3 展示了我们的方法与三种人工设计特征的方法在不同尺寸图像块上的分类精度。与其他三种方法相比较,我们的方法在任何图像块尺寸上的准确率都更高,且随着图像块尺寸的缩小,网络的分类准确率会降低。
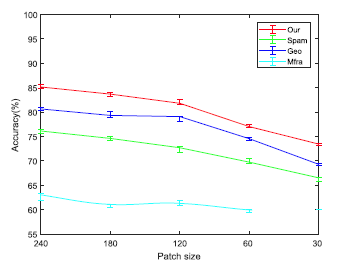
图3 我们的方法与三种人工设计特征的方法在不同尺寸图像块上的分类精度表现
后处理的鲁棒性分析
有效的图像识别算法不仅能处理原始数据,还应该在后处理数据中具有良好的鲁棒性。本文的研究中,我们针对图像缩放和 JPEG 压缩这两种典型的后处理进行鲁棒性分析。下图 4 展示了四种分类方法在五种后处理中的分类准确率表现 (实线部分)。可以看到,我们的模型对于后处理的数据具有更强的鲁棒性。
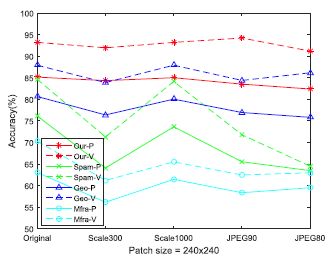
图4 不同分类方法在后处理数据上的分类精度表现
局部到全局策略的分析
进一步地,我们还分析了局部到全局策略在全尺寸图像上的分类精度表现。如下表3所示,实验结果表明在全尺寸图像上的模型精度,比在图像块上的模型精度要高,并且采用图像块投票的方式获得的全尺寸分类精度要高于直接在全尺寸上图像得到的分类精度。而投票准确性对后处理操作的稳健性由上图4中的虚线表示。
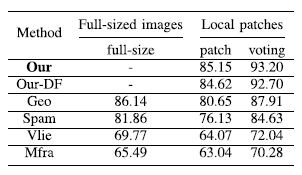
表3 局部到全局策略对六种方法的分类准确率的影响
▌可视化
在计算机视觉任务中,CNN 的训练普遍存在一种现象:即模型在第一层学习的卷积核类似于 Gabor 滤波器和 color blobs。我们在下图 5 展示了模型的卷积可视化结果,其中 (a) 表示我们模型的第一层卷积核的傅里叶变换 (FFT) 结果, (b) 表示预训练的 CaffeNet 的结果,(c) 是对应于 CaffeNet 中第一层的前96个卷积核的可视化结果,而 (d) 则对应于最后的96个结果。滤波器根据三个颜色通道 B,G 和 R 被分为3个组,而像素越亮则代表所对应的B,G,R的值越高。

图 5 卷积可视化结果
▌结论
本文,我们提出了一种基于 CNN 的通用框架来区别自然图像 NIs 与计算机生成图像 CG 之间的差异,这种方法不仅能够在 Google 和 PRCG 的数据集中进行测试,而在后处理时也表现出较好的鲁棒性。这些优点对于现实生活中的图像识别任务是非常有效且重要的。
未来的工作中,我们将尝试通过引入语义级别的 CNN 集成模型来进一步改进我们的模型性能。此外,我们还将扩展我们的方法,并应用于视频数据的差异性探索。
更多内容可以参考论文
https://ieeexplore.ieee.org/document/8355795/
——【完】——
