大战三回合:XGBoost、LightGBM和Catboost一决高低 | 程序员硬核算法评测

作者 | LAVANYA
译者 | 陆离
责编 | Jane
出品 | AI科技大本营(ID: rgznai100)
【导读】XGBoost、LightGBM 和 Catboost 是三个基于 GBDT(Gradient Boosting Decision Tree)代表性的算法实现,今天,我们将在三轮 Battle 中,根据训练和预测的时间、预测得分和可解释性等评测指标,让三个算法一决高下!
一言不合就 Battle
GBDT 是机器学习中的一个非常流行并且有效的算法模型,2014 年陈天奇博士提出的 XGBoost 算法就是 GBDT 一个重要实现。但在大训练样本和高维度特征的数据环境下,GBDT 算法的性能以及准确性却面临了极大的挑战,随后,2017 年 LightGBM 应势而生,由微软开源的一个机器学习框架;同年,俄罗斯的搜索巨头 Yandex 开源 Catboost 框架。
XGBoost(eXtreme Gradient Boosting) 特点是计算速度快,模型表现好,可以用于分类和回归问题中,号称“比赛夺冠的必备杀器”。
LightGBM(Light Gradient Boosting Machine)的训练速度和效率更快、使用的内存更低、准确率更高、并且支持并行化学习与处理大规模数据。
Catboost( Categorical Features+Gradient Boosting)采用的策略在降低过拟合的同时保证所有数据集都可用于学习。性能卓越、鲁棒性与通用性更好、易于使用而且更实用。据其介绍 Catboost 的性能可以匹敌任何先进的机器学习算法。
三个都是基于 GBDT 最具代表性的算法,都说自己的性能表现、效率及准确率很优秀,究竟它们谁更胜一筹呢?为了 PK 这三种算法之间的高低,我们给它们安排了一场“最浪漫的 Battle”,通过三轮 Battle 让 XGBoost、Catboost 和 LightGBM 一绝高下!
Round 1:分类模型,按照数据集Fashion MNIST把图像分类(60000行数据,784个特征);
Round 2:回归模型,预测纽约出租车的票价(60000行数据,7个特征);
Round 3:通过海量数据集,预测纽约出租车票价(200万行数据,7个特征);
Battle 规则
在每一轮 PK 中,我们都遵循以下步骤:
1、训练 XGBoost、Catboost、LightGBM 三种算法的基准模型,每个模型使用相同的参数进行训练;
2、使用超参数自动搜索模块 GridSearchCV 来训练 XGBoost、Catboost 和 LightGBM 三种算法的微调整模型;
3、衡量指标:
a.训练和预测的时间;
b.预测得分;
c.可解释性(包括:特征重要性,SHAP 值,可视化树);

PK 结果揭晓
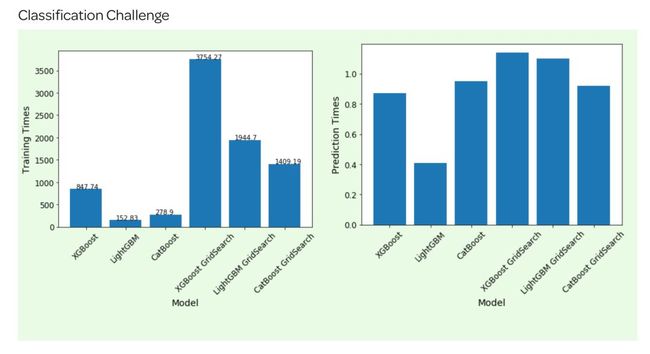
(一)运行时间& 准确度得分
Top 1:LightGBM
Top 2:CatBoost
Top 3:XGBoost

在训练和预测时间两方面,LightGBM 都是明显的获胜者,CatBoost 则紧随其后,而 XGBoost 的训练时间相对更久,但预测时间与其它两个算法的差距没有训练时间那么大。
在增强树(boosted trees)中进行训练的时间复杂度介于(log)和(2)之间,而对于预测,时间复杂度为(log2 ),其中 = 训练实例的数量, = 特征数量,以及 = 决策树的深度。
Round 1 ~ 3


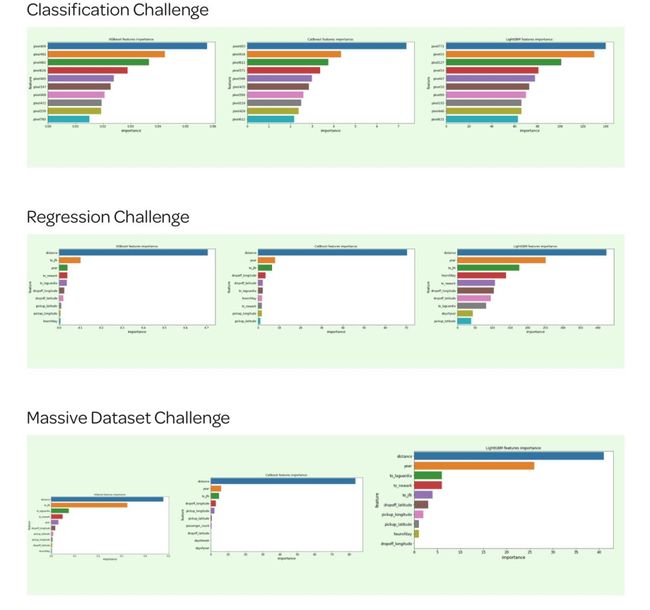
(二)可解释性
一个模型的预测得分仅反映了它的一方面,我们还想知道模型为什么要做出这个预测的。
在这里,我们描绘出了模型特征的重要性和 SHAP 值,还有一个实际的决策树,以便更准确地理解模型的预测。
(a)特征的重要性
这三个增强模型都提供了一个 .feature_importances_ attribute 属性,允许我们查看有哪些特征对模型预测的影响是最大的:
Round 1 ~ 3
(b)SHAP值
另外一种方法是 SHAP 摘要图,用来了解每个特性对模型输出的影响分布。SHAP 值是在这些特征之间的公平的信用分配,并且具有博弈论一致性的理论保证,这使得它们通常比整个数据集中的那些典型特征的重要性更值得信赖。
Round 1 & 2


(c)绘制决策树
最后,XGBoost 和 LightGBM 这两个算法还允许我们绘制用于进行预测的实际决策树,这对于更好地了解每个特征对目标变量的预测能力非常的有用。而 CatBoost 没有决策树的绘制功能。
如果想看 CatBoost 的结果,这里推荐给大家一个可视化工具:
https://blog.csdn.net/l_xzmy/article/details/81532281
Round 1 & 2

评测总结
CatBoost
(1)CatBoost 提供了比 XGBoost 更高的准确性和和更短的训练时间;
(2)支持即用的分类特征,因此我们不需要对分类特征进行预处理(例如,通过 LabelEncoding 或 OneHotEncoding)。事实上,CatBoost 的文档明确地说明不要在预处理期间使用热编码,因为“这会影响训练速度和最终的效果”;
(3)通过执行有序地增强操作,可以更好地处理过度拟合,尤其体现在小数据集上;
(4)支持即用的 GPU 训练(只需设置参数task_type =“GPU”);
(5)可以处理缺失的值;
LightGBM
(1)LightGBM 也能提供比 XGBoost 更高的准确性和更短的训练时间;
(2)支持并行的树增强操作,即使在大型数据集上(相比于 XGBoost)也能提供更快的训练速度;
(3)使用 histogram-esquealgorithm,将连续的特征转化为离散的特征,从而实现了极快的训练速度和较低的内存使用率;
(4)通过使用垂直拆分(leaf-wise split)而不是水平拆分(level-wise split)来获得极高的准确性,这会导致非常快速的聚合现象,并在非常复杂的树结构中能捕获训练数据的底层模式。可以通过使用 num_leaves 和 max_depth 这两个超参数来控制过度拟合;
XGBoost
(1)支持并行的树增强操作;
(2)使用规则化来遏制过度拟合;
(3)支持用户自定义的评估指标;
(4)处理缺失的值;
(5)XGBoost 比传统的梯度增强方法(如 AdaBoost)要快得多;
如果想深入研究这些算法,可以阅读下面相关文章的链接:
LightGBM: 一种高效的梯度增强决策树
https://papers.nips.cc/paper/6907-lightgbm-a-highly-efficient-gradient-boosting-decision-tree.pdf
CatBoost: 支持分类特征的梯度增强
http://learningsys.org/nips17/assets/papers/paper_11.pdf
XGBoost: 一个可扩展的树增强系统
https://arxiv.org/pdf/1603.02754.pdf
重要参数解读
下面列出的是模型中一些重要的参数,以帮助大家更好学习与使用这些算法!
Catboost
n_estimators:表示用于创建树的最大数量;
learning_rate:表示学习率,用于减少梯度的级别;
eval_metric:表示用于过度拟合检测和最佳模型选择的度量标准;
depth:表示树的深度;
subsample:表示数据行的采样率,不能在贝叶斯增强类型设置中使用;
l2_leaf_reg:表示成本函数的L2规则化项的系数;
random_strength:表示在选择树结构时用于对拆分评分的随机量,使用此参数可以避免模型过度拟合;
min_data_in_leaf:表示在一个叶子中训练样本的最小数量。CatBoost不会在样本总数小于指定值的叶子中搜索新的拆分;
colsample_bylevel, colsample_bytree, colsample_bynode — 分别表示各个层、各棵树、各个节点的列采样率;
task_type:表示选择“GPU”或“CPU”。如果数据集足够大(从数万个对象开始),那么在GPU上的训练与在CPU上的训练相比速度会有显著的提升,数据集越大,加速就越明显;
boosting_type:表示在默认情况下,小数据集的增强类型值设置为“Ordered”。这可以防止过度拟合,但在计算方面的成本会很高。可以尝试将此参数的值设置为“Plain”,来提高训练速度;
rsm:对于那些具有几百个特性的数据集,rsm参数加快了训练的速度,通常对训练的质量不会有影响。另外,不建议为只有少量(10-20)特征的数据集更改rsm参数的默认值;
border_count:此参数定义了每个特征的分割数。默认情况下,如果在CPU上执行训练,它的值设置为254,如果在GPU上执行训练,则设置为128;
LightGBM
num_leaves:表示一棵树中最大的叶子数量。在LightGBM中,必须将num_leaves的值设置为小于2^(max_depth),以防止过度拟合。而更高的值会得到更高的准确度,但这也可能会造成过度拟合;
max_depth:表示树的最大深度,这个参数有助于防止过度拟合;
min_data_in_leaf:表示每个叶子中的最小数据量。设置一个过小的值可能会导致过度拟合;
eval_metric:表示用于过度拟合检测和最佳模型选择的度量标准;
learning_rate:表示学习率,用于降低梯度的级别;
n_estimators:表示可以创建树的最大数量;
colsample_bylevel, colsample_bytree, colsample_bynode — 分别表示各个层、各棵树、各个节点的列采样率;
boosting_type — 该参数可选择以下的值:
‘gbdt’,表示传统的梯度增强决策树;
‘dart’,缺失则符合多重累计回归树(Multiple Additive Regression Trees);
‘goss’,表示基于梯度的单侧抽样(Gradient-based One-Side Sampling);
‘rf’,表示随机森林(Random Forest);
feature_fraction:表示每次迭代所使用的特征分数(即所占百分比,用小数表示)。将此值设置得较低,来提高训练速度;
min_split_again:表示当在树的叶节点上进行进一步的分区时,所需最小损失值的减少量;
n_jobs:表示并行的线程数量,如果设为-1则可以使用所有的可用线程;
bagging_fraction:表示每次迭代所使用的数据分数(即所占百分比,用小数表示)。将此值设置得较低,以提高训练速度;
application :default(默认值)=regression, type(类型值)=enum, options(可选值)=
regression : 表示执行回归任务;
binary : 表示二进制分类;
multiclass:表示多个类的类别;
lambdarank : 表示lambdarank 应用;
max_bin:表示用于存放特征值的最大容器(bin)数。有助于防止过度拟合;
num_iterations:表示增强要执行的迭代的迭代;
XGBoost 参数
https://xgboost.readthedocs.io/en/latest/parameter.html
LightGBM 参数
https://lightgbm.readthedocs.io/en/latest/Python-API.html
CatBoost 参数
https://catboost.ai/docs/concepts/python-reference_parameters-list.html#python-reference_parameters-list
上面三个文件可以查看这些模型所有超参数。
如果想详细本文的代码和原文,可访问下面的地址:
https://www.kaggle.com/lavanyashukla01/battle-of-the-boosting-algos-lgb-xgb-catboost
https://lavanya.ai/2019/06/27/battle-of-the-boosting-algorithms/
(*本文为 AI科技大本营编译文章,转载请联系 1092722531)
◆
精彩推荐
◆

推荐阅读
阿里90后科学家研发,达摩院开源新一代AI算法模型
正态分布为何如此重要?
智能文本信息抽取算法的进阶
入门必备 | 一文读懂神经架构搜索
印度人才出口:一半美国科技企业CEO是印度裔 | 数据分析中印青年
为什么说“大公司的技术顽疾根本挽救不了”
25 年 IT 老兵零基础写小说,作品堪比《三体》| 人物志
中小企业搭建混合云,服务器如何选?
从0到1 | 文本挖掘的传统与深度学习算法
一览微软在机器阅读理解、推荐系统、人机对话等最新研究进展 | ACL 2019
1.2w星!火爆GitHub的Python学习100天刷爆朋友圈!