Caffe Examples
1.ImageNet tutorial(Brewing tutorial)
(1)假设数据源已经OK,如下:
/path/to/imagenet/train/n01440764/n01440764_10026.JPEG /path/to/imagenet/val/ILSVRC2012_val_00000001.JPEG
(2)准备附加数据使用下面这条语句可以从主页中得到caffe_ilsvrc12.tar.gz压缩包,./data/ilsvrc12/get_ilsvrc_aux.sh该压缩包中包含:
det_synset_words.txt --------
imagenet.bet.pickle --------
imagenet_mean.binaryproto --------
synsets.txt -------- 1000个分类及文件夹名称
synset_words.txt -------- 1000个分类(包含训练数据集中1000个文件夹名称和分类名称)
test.txt -------- 包含10万张测试图片名称及标签(均为0)
train.txt -------- 训练数据中1000个文件夹名称、文件中的图片名称 (每个分类文件中包含1300个图片)和类别编号(0-999)
val.txt -------- 5万张评估照片,包含照片名称及每个照片的类别代码标签(0-999)
The training and validation input are described intrain.txtandval.txtas text listing all the files and their labels. Note that we use a different indexing for labels than the ILSVRC devkit: we sort the synset names in their ASCII order, and then label them from 0 to 999. Seesynset_words.txt for the synset/name mapping.
注:在创建.mdb数据库的时候,需要将图片进行尺寸变换,才不会出现越界的问题。在这个案例中所有的图片都调整为256*256大小。
在新版本的caffe-master中,使用examples/imagenet/create_imagenet.sh将.jpg格式的图片转换为.mdb数据库文件。在create_imagenet.sh会有RESIZE=false一条语句,将其更改为RESIZE=true即可。
You may want to resize the images to 256x256 in advance. By default, we do not explicitly do this because in a cluster environment, one may benefit from resizing images in a parallel fashion, using mapreduce. For example, Yangqing used his lightweight mincepie package. If you prefer things to be simpler, you can also use shell commands, something like:
for name in /path/to/imagenet/val/*.JPEG; do convert -resize 256x256\! $name $name done
图片大小转化完毕后,需要产生数据库.mdb文件,用以下命令:
最终会产生两个文件夹:./examples/imagenet/create_imagenet.sh.examples/imagenet/ilsvrc12_train_leveldb 和 examples/imagenet/ilsvrc12_val_leveldb
其中,包含data.mdb 和 lock.mdb.(注:在这个过程中可设置 GLOG_logtostderr=1来显示更多的信息,以便监视。)
至此,数据准备完毕。
(3)计算图像均值
输入图像的时候需要计算图像的均值,使用以下语句:
The model requires us to subtract the image mean from each image, so we have to compute the mean. tools/compute_image_mean.cpp implements that - it is also a good example to familiarize yourself on how to manipulate the multiple components, such as protocol buffers, leveldbs, and logging, if you are not familiar with them. Anyway, the mean computation can be carried out as:
./examples/imagenet/make_imagenet_mean.sh最终产生data/ilsvrc12/imagenet_mean.binaryproto文件便于后续使用。(4)模型定义
We are going to describe a reference implementation for the approach first proposed by Krizhevsky, Sutskever, and Hinton in their NIPS 2012 paper.
The network definition(models/bvlc_reference_caffenet/train_val.prototxt) follows the one inKrizhevsky et al. Note that if you deviated from file paths suggested in this guide, you’ll need to adjust the relevant paths in the.prototxt files.
If you look carefully atmodels/bvlc_reference_caffenet/train_val.prototxt, you will notice several include sections specifying either phase:TRAIN or phase:TEST. These sections allow us to define two closely related networks in one file: the networkused for training and the network used for testing. These two networks are almost iden tical, sharing all layers except for those marked with include { phase: TRAIN } or include { phase: TEST}. In this case, only the input layers and one output layer are different.
Input layer differences: The training network’s data input layer draws its data from examples/imagenet/ilsvrc12_train_leveldb and randomly mirrors the input image. The testing network’s data layer takes data fromexamples/imagenet/ilsvrc12_val_leveldb and does not perform random mirroring.
Output layer differences: Both networks output the softmax_loss layer, which in training is used to compute the loss function and to initialize the backpropagation, while in validation this loss is simply reported. The testing network also has a second output layer, accuracy, which is used to report the accuracy on the test set. In the process of training, the test network will occasionally be instantiated and tested on the test set, producing lines like Test score #0: xxx and Test score #1: xxx. In this case score 0 is the accuracy (which will start around 1/1000 = 0.001 for an untrained network) and score 1 is the loss (which will start around 7 for an untrained network).
- We will run in batches of 256, and run a total of 450,000 iterations (about 90 epochs).
- For every 1,000 iterations, we test the learned net on the validation data.
- We set the initial learning rate to 0.01, and decrease it every 100,000 iterations (about 20 epochs).
- Information will be displayed every 20 iterations.
- The network will be trained with momentum 0.9 and a weight decay of 0.0005.
- For every 10,000 iterations, we will take a snapshot of the current status.
Sound good? This is implemented inmodels/bvlc_reference_caffenet/solver.prototxt.
(5)训练ImageNet
训练的网络结构如下所示:
(6)实例
分类:cat

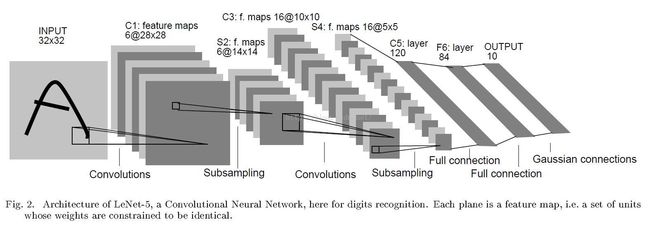
2.Training LeNet on MNIST with Caffe
3.CIFAR-10 tutorial
目标:Train and test Caffe on CIFAR-10 data. (This example reproducesAlex Krizhevsky'paper results in Caffe.)来源:Learning Multiple Layers of Features from Tiny Images(Alex Krizhevsky April 8, 2009)数据集:CIFAR-10 (http://www.cs.toronto.edu/~kriz/cifar.html)
Model:The CIFAR-10 model is a CNN that composes layers of convolution, pooling, rectified linear unit (ReLU) nonlinearities, and local contrast normalization with a linear classifier on top of it all. We have defined the model in theCAFFE_ROOT/examples/cifar10 directory’s cifar10_quick_train_test.prototxt.cifar10 directory’s cifar10_quick_train_test.prototxt网络结构如下:

4.Feature extraction with Caffe C++ code
Target:
Extract CaffeNet / AlexNet features using the Caffe utilityInfo:
In this tutorial, we will extract features using a pre-trained model with the included C++ utility. Note that we recommend using the Python interface for this task, as for example in the filter visualization example.
Pipline:
(1)创建临时文件夹用来存储特征文件
mkdir examples/_temp
(2)Generate a list of the files to process. We’re going to use the images that ship with caffe.
find `pwd`/examples/images -type f -exec echo {} \; > examples/_temp/temp.txt
(3)The ImageDataLayerwe’ll use expects labels after each filenames, so let’s add a 0 to the end of each line
sed "s/$/ 0/" examples/_temp/temp.txt > examples/_temp/file_list.txt
(4)Let’s copy and modify the network definition. We’ll be using the ImageDataLayer, which will load and resize images for us.
cp examples/feature_extraction/imagenet_val.prototxt examples/_temp
(5)Extract Features
./build/tools/extract_features.bin models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel examples/_temp/imagenet_val.prototxt fc7 examples/_temp/features 10 leveldb
The name of feature blob that you extract is fc7, which represents thehighest level feature of the reference model. We can use any other layer, as well, such asconv5 or pool3.
The last parameter above is the number of data mini-batches.
The features are stored to LevelDBexamples/_temp/features, ready for access by some other code.
If you meet with the error “Check failed: status.ok() Failed to open leveldb examples/_temp/features”, it is because the directory examples/_temp/features has been created the last time you run the command. Remove it and run again.
rm -rf examples/_temp/features/
(6)If you’d like to use the Python wrapper for extracting features, check out the filtervisualization notebook.
5.CaffeNet C++ Classification example(Classifying ImageNet: using the C++ API)
Target:
A simple example performing image classification using the low-level C++ API.Info:
Caffe, at its core, is written in C++. It is possible to use the C++ API of Caffe to implement an image classification application similar to the Python code presented in one of the Notebook example. To look at a more general-purpose example of the Caffe C++ API, you should study the source code of the command line toolcaffe intools/caffe.cpp.
Example:
(1) Presentation
A simple C++ code is proposed inexamples/cpp_classification/classification.cpp. For the sake of simplicity, this example does not support oversampling of a single sample nor batching of multiple independant samples. This example is not trying to reach the maximum possible classification throughput on a system, but special care was given to avoid unnecessary pessimization while keeping the code readable.
(2) Compiling
The C++ example is built automatically when compiling Caffe. To compile Caffe you should follow the documented instructions. The classification example will be built asexamples/classification.bin in your build directory.
(3) Usage
To use the pre-trained CaffeNet model with the classification example, you need to download it from the “Model Zoo” using the following script:./scripts/download_model_binary.py models/bvlc_reference_caffenet. The ImageNet labels file (also called the synset file) is also required in order to map a prediction to the name of the class:./data/ilsvrc12/get_ilsvrc_aux.sh.
Using the files that were downloaded, we can classify the provided cat image (examples/images/cat.jpg) using this command:
The output should look like this:./build/examples/cpp_classification/classification.bin models/bvlc_reference_caffenet/deploy.prototxt models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel data/ilsvrc12/imagenet_mean.binaryproto data/ilsvrc12/synset_words.txt examples/images/cat.jpg---------- Prediction for examples/images/cat.jpg ---------- 0.3134 - "n02123045 tabby, tabby cat" 0.2380 - "n02123159 tiger cat" 0.1235 - "n02124075 Egyptian cat" 0.1003 - "n02119022 red fox, Vulpes vulpes" 0.0715 - "n02127052 lynx, catamount"
(3) Improving Performance
To further improve performance, you will need to leverage the GPU more, here are some guidelines:
Move the data on the GPU early and perform all preprocessing operations there.
If you have many images to classify simultaneously, you should use batching (independent images are classified in a single forward pass).
Use multiple classification threads to ensure the GPU is always fully utilized and not waiting for an I/O blocked CPU thread.