大数据python之简单的网络爬虫代码实现(单一与循环代码进行网络爬虫)
网络爬虫对于大数据类专业的同学来说可能并不陌生,那么在讲网络爬虫之前,博主先给予大家介绍一下我们平常所用的浏览器的工作原理,只要明白了平常的浏览器的工作原理,那么网络爬虫也就变得简单了。
下面的图是一个浏览器正常的工作原理流程图:
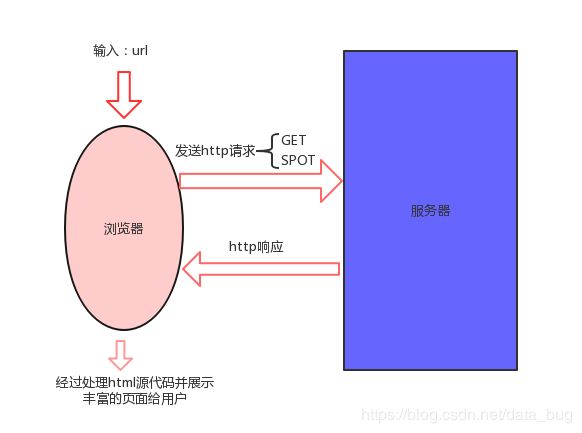
首先我们可以看到有四个流程:
(1)我们先向浏览器中输入url(网址);
(2)浏览器就会向指定的服务器进行发送HTTP请求,请求的方式有两种:一种是get,另一种是:spot。那么这两种有什么区别呢?你可以这么理解:get是指从服务器里下载回来我们需要的数据,spot就是我们上传(粘贴)到服务器上的资料;
(3)当服务器接收到浏览器的请求之后就会对服务器产生http响应;
(4)其实响应回来的是html的源代码一般的人是看不懂的,那么浏览器再经过处理,最后给我们展示出丰富,美丽的网页!!!
介绍完 一个正常的浏览器的工作流程后,我们就开始我们的网络爬虫了。网络爬虫:模拟浏览器网页,下载我们需要的网络资源的一个程序,其实本质上是一个伪造的http请求。好了,我们开始我们的代码部分(说明:使用python环境)
首先我们先再python中加载第三方库:re,urllib,json,time,三个库
#加载第三方库
import urllib
import re
import json
import time
###
#输入网站
url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv6992&productId=8758880&score=0&sortType=5&page=2&pageSize=10&isShadowSku=0&rid=0&fold=1'
#1:模拟浏览器的http请求部分
#html = urllib.request.urlopen(url)
#2:模拟响应过程
#html = urllib.request.urlopen(url).read()
#我们可以打印print(html)看,如果源码出现乱码,我们再响应过程部分进行编码设置:常用的编码有:utf-8,gbk,gb18030
#完整的模拟浏览器的http请求过程和http响应的过程
html = urllib.request.urlopen(url).read().decode('gbk')#此处已经经请求和响应过程合并
print(html)
#由于读取到的源码不是标准的 JSON 格式,因此需要使用进行处理
json_data = re.search('{.+}', html).group()#正则表达式处理
data = json.loads(json_data)# 将json格式数据转为字典格式(反序列化)
现在进行爬取1一页的评论数据,代码运行:
#忘记每行代码的目的,请看上面备注
import pandas as pd
import urllib
import requests
import re
import json
import random
url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv6992&productId=8758880&score=0&sortType=5&page=2&pageSize=10&isShadowSku=0&rid=0&fold=1'
html = urllib.request.urlopen(url).read().decode('gbk')
print(html)
json_data = re.search('{.+}', html).group()
data = json.loads(json_data)
data['comments']
运行后我们就可以得到了我们所需的数据评论数据了。
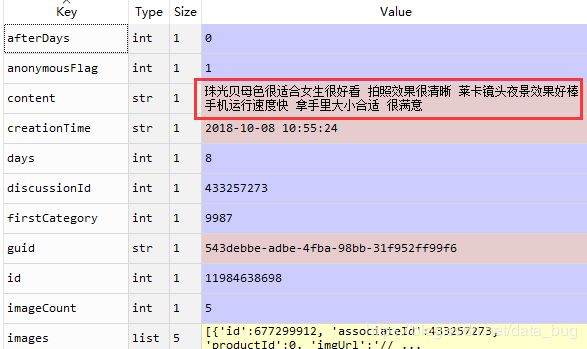
是不是突然感觉网络爬虫很简单?几行代码就完全解决了,但是别忘了这里只是爬取一页的数据,如需爬取多页就要需要我们自己进行写循环爬取咯。为了方便大家,博主自己也写了个循环爬虫的代码如下:
all_url = []
for i in range(0,10):
all_url.append('https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv6992&productId=8758880&score=0&sortType=5&page='+str(i)+'&pageSize=10&isShadowSku=0&rid=0&fold=1')
allh_data = pd.DataFrame()
for k in range(0,10): #爬取10页的数据
print("正在打印第{}页的评论数据".format(k+1))
html_data = urllib.request.urlopen(all_url[k]).read().decode('gb18030')
json_data = re.search('{.+}', html_data).group()
all_data = json.loads(json_data)
alls_data = all_data['comments']
referenceName = [x['referenceName'] for x in alls_data] # 提取商品的品牌名
nickname = [x['nickname'] for x in alls_data] # 提取商品购买用户的昵称
creationTime = [x['creationTime'] for x in alls_data] # 提取购物时间
content = [x['content'] for x in alls_data] # 发表时间
all_data_hp = pd.DataFrame({'referenceName': referenceName,
'nickname': nickname,
'creationTime': creationTime,
'content': content})
allh_data = allh_data.append(all_data_hp)
time.sleep(random.randint(2, 3))
print(">>>爬取第{}结束.......".format(k+1))
allh_data.index = range(len(allh_data))#重设dateframe的index
那么最后就可以得到如下的数据:
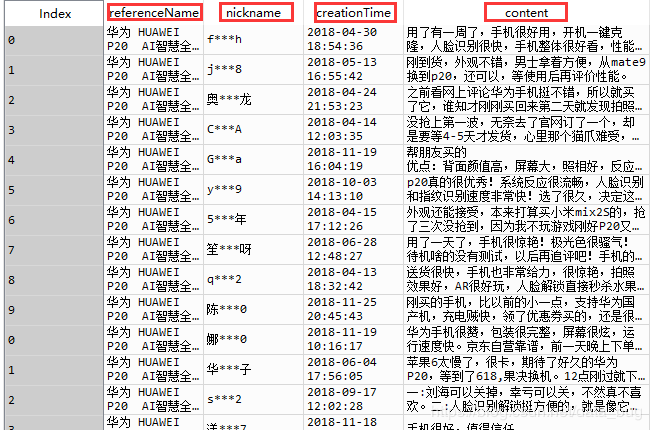
如有疑问欢迎评论,博主会尽力回答。
转载说明:如需转载请标注来源:https://blog.csdn.net/data_bug/article/details/84646030