CPU Rings, Privilege, and Protection
原文地址:http://duartes.org/gustavo/blog/post/cpu-rings-privilege-and-protection/
You probably know intuitively that applications have limited powers in Intel x86 computers and that only operating system code can perform certain tasks, but do you know how this really works? This post takes a look at x86 privilege levels, the mechanism whereby the OS and CPU conspire to restrict what user-mode programs can do. There are four privilege levels, numbered 0 (most privileged) to 3 (least privileged), and three main resources being protected: memory, I/O ports, and the ability to execute certain machine instructions. At any given time, an x86 CPU is running in a specific privilege level, which determines what code can and cannot do. These privilege levels are often described as protection rings, with the innermost ring corresponding to highest privilege. Most modern x86 kernels use only two privilege levels, 0 and 3:
直觉上,你也许知道 intel x86 机器限制了应用程序的权限,并且只有操作系统代码能执行某些任务。但是你知道他们实际是怎么工作的吗?本文带你学习 x86 的“特权级”,这种机制依靠操作系统和 cpu 共同限制了用户态程序能做什么。一共有四种特权级别,从 0(最高) 到 3(最低),三种资源被保护起来:内存、I/O 端口、和某些机器指令执行权限。cpu 在某个时刻运行在特定的特权级,并且决定了可以做什么,不可以做什么。通常用保护环(ring)来描述特权级,最内层的环对应最高权限。大多数 x86 内核只用了两个特权级:0 和 3:
About 15 machine instructions, out of dozens, are restricted by the CPU to ring zero. Many others have limitations on their operands. These instructions can subvert the protection mechanism or otherwise foment chaos if allowed in user mode, so they are reserved to the kernel. An attempt to run them outside of ring zero causes a general-protection exception, like when a program uses invalid memory addresses. Likewise, access to memory and I/O ports is restricted based on privilege level. But before we look at protection mechanisms, let’s see exactly
how the CPU keeps track of the current privilege level, which involves the segment selectors from the previous post. Here they are:
大约有15条机器指令限制在cpu ring 0(不多)。更多的限制是在这些指令的操作数上。这些指令如果允许在用户模式执行,会破坏保护机制,搞乱操作系统(比如蓝屏和系统 oops,译者注 ),操作系统保留指令的执行权限。如果尝试在 ring 0 外执行特权指令,会导致 general-protection 异常,就像程序使用了一个无效的内存地址。类似的,特权级也限制了访问内存和 IO 端口。在我们看保护模式之前,让我们先仔细看看 cpu 如何处理当前应用程序的特权级,这些和我们之前的文章讲过的段选择子有关系:
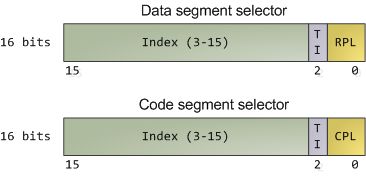
The full contents of data segment selectors are loaded directly by code into various segment registers such as ss (stack segment register) and ds (data segment register). This includes the contents of the Requested Privilege Level (RPL) field, whose meaning we tackle in a bit. The code segment register (cs) is, however, magical. First, its contents cannot be set directly by load instructions such as mov, but rather only by instructions that alter the flow of program execution, like call. Second, and importantly for us, instead of an RPL field that can be set by code, cs has a Current Privilege Level (CPL) field maintained by the CPU itself. This 2-bit CPL field in the code segment register is always equal to the CPU’s current privilege level. The Intel docs wobble a little on this fact, and sometimes online documents confuse the issue, but that’s the hard and fast rule. At any time, no matter what’s going on in the CPU, a look at the CPL in cs will tell you the privilege level code is running with.
段选择子的全部数据都是由代码直接从各种各样的段寄存器加载的,比如 ss (栈寄存器),ds(数据段寄存器)。这也包括请求特权级(RPL)域,其中每个 bit 含义都不同(whose meaning we tackle in a bit,按位处理每位的含义,译者注)。然而,代码段寄存器(cs)比较神奇,首先,cs 的值不能直接使用加载指令设置,比如 mov,而是通过可以修改程序执行顺序(flow of program execution)的指令来设置,比如 call。第二,也是非常重要的一点,cpu 自己维护 cs 的当前特权级(CPL)域,这和 RPL 不同,RPL 自己是可以通过代码设置。代码段寄存器 2 bit 的 CPL 域总是等于 cpu 当前特权级。intel 文档对这个事实说的含混不清,一些在线文档也搞混了这点,不过这是严谨和快速易用的规则(that's the hard and fast rule)。不管cpu 在做什么,只要看 CPL 就知道当前代码在什么特权级别运行。
Keep in mind that the CPU privilege level has nothing to do with operating system users. Whether you’re root, Administrator, guest, or a regular user, it does not matter. All user code runs in ring 3 and all kernel code runs in ring 0, regardless of the OS user on whose behalf the code operates. Sometimes certain kernel tasks can be pushed to user mode, for example user-mode device drivers in Windows Vista, but these are just special processes doing a job for the kernel and can usually be killed without major consequences.
但是记住,cpu 特权级对系统用户没做任何事情,不管是不是 root、Administrator、guest 或者一般用户,都和特权级没关系。不管代码操作代表了哪个 OS 用户,所有用户代码都运行在 ring 3,所有内核代码都运行在 ring 0(意思 cpu 特权级和以哪个用户运行程序没什么关系,新人容易搞混 cpu 特权级和用户权限)。有时候某些内核任务可以提升到(push)用户模式,比如 windows vista 的用户态设备驱动,只是特殊的进程为了内核做工作,而且杀死这种程序也没什么严重后果。
Due to restricted access to memory and I/O ports, user mode can do almost nothing to the outside world without calling on the kernel. It can’t open files, send network packets, print to the screen, or allocate memory. User processes run in a severely limited sandbox set up by the gods of ring zero. That’s why it’s impossible, by design, for a process to leak memory beyond its existence or leave open files after it exits. All of the data structures that control such things – memory, open files, etc – cannot be touched directly by user code; once a process finishes, the sandbox is torn down by the kernel. That’s why our servers can have 600 days of uptime – as long as the hardware and the kernel don’t crap out, stuff can run for ever. This is also why Windows 95 / 98 crashed so much: it’s not because “M$ sucks” but because important data structures were left accessible to user mode for compatibility reasons. It was probably a good trade-off at the time, albeit at high cost.
因为限制了内存和 IO 端口的访问,用户模式在不调用内核的情况下,对外部世界几乎没什么影响。不能打开文件、不能发送网络包、给屏幕打印东西、或者分配内存。用户进程运行在一个严格限制的沙盒内,沙盒由运行在 ring 0 的“上帝”创建。设计上,避免了进程退出后泄露内存或者遗漏打开的文件的可能性。控制内存分配、打开文件等等的数据结构都不能由用户代码直接创建,一旦进程退出,沙盒就被内核销毁。这就是为什么只要硬件和内核没问题,我们的服务器可以启动 600 多天,甚至可以永远运行。这也是为什么 windows 95/98 这么爱崩溃。不是因为 “M$ sucks”,而是因为兼容性的原因,给用户态留了访问重要数据结构的权限。这种保护机制代价很高,但这也许在那时是个很好的权衡。
The CPU protects memory at two crucial points: when a segment selector is loaded and when a page of memory is accessed with a linear address. Protection thus mirrors memory address translation where both segmentation and paging are involved. When a data segment selector is being loaded, the check below takes place:
cpu 在两个关键点保护内存:段选择子加载时,和用线性地址访问内存页时。因此,保护机制反映在分段和分页的内存地址转换上。在数据段选择子加载的时候,进行下面的检查:

Since a higher number means less privilege, MAX() above picks the least privileged of CPL and RPL, and compares it to the descriptor privilege level (DPL). If the DPL is higher or equal, then access is allowed. The idea behind RPL is to allow kernel code to load a segment using lowered privilege. For example, you could use an RPL of 3 to ensure that a given operation uses segments accessible to user-mode. The exception is for the stack segment register ss, for which the three of CPL, RPL, and DPL must match exactly.
所以更高的特权级代表更小的权限。上图中 MAX() 得到 CPL 和 RPL 权限较小的一个,然后和段描述符权限级别
( DPL )比较。如果 DPL 更大或相等,就允许访问(CPL <= DPL && RPL <= DPL允许访问)。RPL 背后的思想是允许内核代码用低权限加载段。例如:内核可以用 RPL 3 访问用户态的段。因此 CPL、RPL、DPL 必须精确匹配,只有栈寄存器(ss)例外。(我解释下这段话:CPL 代表当前程序权限,是内核还是应用程序,DPL 代表访问数据段的权限,CPL 必须 <= DPL 很好理解。RPL 是在为了检查用户态传入内核的内存地址。应用瞎传一个不属于自己内存的指针给内核,借着 OS 的权限破坏其他程序,做不可告人的秘密,这样是不行的,这时应该以传入的逻辑地址的 RPL 去判断权限。不过这都些是 386 的历史遗留问题了)。
In truth, segment protection scarcely matters because modern kernels use a flat address space where the user-mode segments can reach the entire linear address space. Useful memory protection is done in the paging unit when a linear address is converted into a physical address. Each memory page is a block of bytes described by a page table entry containing two fields related to protection: a supervisor flag and a read/write flag. The supervisor flag is the primary x86 memory protection mechanism used by kernels. When it is on, the page cannot be accessed from ring 3. While the read/write flag isn’t as important for enforcing privilege, it’s still useful. When a process is loaded, pages storing binary images (code) are marked as read only, thereby catching some pointer errors if a program attempts to write to these pages. This flag is also used to implement copy on write when a process is forked in Unix. Upon forking, the parent’s pages are marked read only and shared with the forked child. If either process attempts to write to the page, the processor triggers a fault and the kernel knows to duplicate the page and mark it read/write for the writing process.
事实上,段保护几乎不是问题。因为现代内核使用了扁平地址空间( flat address space ),用户态可以访问整个线性地址空间。比较实用的内存保护方法是页面单元在线性地址转换成物理地址时进行。每个内个页都是由页表项的一堆数据维护,其中包含两个和内存保护相关的域:supervisor flag 和 读/写 flag。 supervisor flag 是内核使用的主要的 x86 内存保护机制,如果打开,就不能从 ring 3访问页面。读/写 flag 也很有用,不过对执行内存保护不重要。当一个进程加载的时候,存储二进制镜像(代码)的页面标记为只读,如果程序试图写入这些页面会 catch 一些指针错误。读/写 flag 也用于实现 unix 上 fork 进程的写时拷贝。在 fork 时,父进程的页标记为只读,并且和子进程共享。如果其中一个进程试图写入这些页面,处理器就会触发错误,内核知道后会给写入的进程复制页面,并把页面标记为可读写。
Finally, we need a way for the CPU to switch between privilege levels. If ring 3 code could transfer control to arbitrary spots in the kernel, it would be easy to subvert the operating system by jumping into the wrong (right?) places. A controlled transfer is necessary. This is accomplished via gate descriptors and via the sysenter instruction. A gate descriptor is a segment descriptor of type system, and comes in four sub-types: call-gate descriptor, interrupt-gate descriptor, trap-gate descriptor, and task-gate descriptor. Call gates provide a kernel entry point that can be used with ordinary call and jmp instructions, but they aren’t used much so I’ll ignore them. Task gates aren’t so hot either (in Linux, they are only used in double faults, which are caused by either kernel or hardware problems).
最后,我们需要一种 CPU 切换特权级的方法。如果 ring 3 的代码可以随意把控制权转换到内核里任意的代码,那跳到一个错误的地址,就能很容易的搞坏操作系统。所以受控的权限转换很必要。这点通过门描述符( gate descriptors)和 sysenter 指令实现。门描述符是类型系统的段描述符(不太清楚这句话什么意思,译者注),有四种子类型:调用门描述符,中断门描述符,陷阱门描述符和任务门描述符。调用门描述符提供普通的 call 和 jmp 指令进入内核的入口,但是现在不常用,我会忽略它。任务门描述符也不常用(linux 上只用于内核或者硬件问题导致的 double faults)。
That leaves two juicier ones: interrupt and trap gates, which are used to handle hardware interrupts (e.g., keyboard, timer, disks) and exceptions (e.g., page faults, divide by zero). I’ll refer to both as an “interrupt”. These gate descriptors are stored in the Interrupt Descriptor Table (IDT). Each interrupt is assigned a number between 0 and 255 called a vector, which the processor uses as an index into the IDT when figuring out which gate descriptor to use when handling the interrupt. Interrupt and trap gates are nearly identical. Their format is shown below along with the privilege checks enforced when an interrupt happens. I filled in some values for the Linux kernel to make things concrete.
还剩下两类神秘的门描述符:中断和陷阱门,它们用来处理硬件中断(比如,键盘、时钟、硬盘)和异常(比如,页面错误,除零)。我把它们都叫“中断”,中断描述符表(IDT)保存这些门描述符。每个中断都设置一个 0-255 的值,整个集合叫称为中断向量(vector,很讨厌翻译成中断向量,我更喜欢翻译成中断数组),在处理中断时,处理器用 IDT 的数组下标(index,数组索引)来查找用哪个门描述符。中断和陷阱门几乎一样。下图展示了中断发生时如何进行权限检查。其中某些值使用 linux 内核的情况来具体说明。

Both the DPL and the segment selector in the gate regulate access, while segment selector plus offset together nail down an entry point for the interrupt handler code. Kernels normally use the segment selector for the kernel code segment in these gate descriptors. An interrupt can never transfer control from a more-privileged to a less-privileged ring. Privilege must either stay the same (when the kernel itself is interrupted) or be elevated (when user-mode code is interrupted). In either case, the resulting CPL will be equal to to the DPL of the destination code segment; if the CPL changes, a stack switch also occurs. If an interrupt is triggered by code via an instruction like int n, one more check takes place: the gate DPL must be at the same or lower privilege as the CPL. This prevents user code from triggering random interrupts. If these checks fail – you guessed it – a general-protection exception happens. All Linux interrupt handlers end up running in ring zero.
段选择子加上偏移量一起确定中断处理代码的入口,门的段选择子和 DPL 共同控制其访问。这些门描述符通常使用内核代码段选择子。中断不能把 CPU 控制权从高权限转到低权限 ring,必须待在相同权限的 ring(当内核处理自身中断的时候),或者提升权限(用户模式的代码产生中断)。任何一种情况,都会让 CPL 与目标代码段的 DPL 相同。如果 CPL 改变,也叫进行栈切换(比如从用户态切换到内核态)。如果中断是由代码触发(比如 int n 指令),会进行多个检查:门描述符的 DPL 必须小于等于 CPL。这阻止了用户代码随机触发中断。你能猜到,如果检查失败就会触发 general-protection。所有 linux 中断处理代码最终都运行在 ring 0。
During initialization, the Linux kernel first sets up an IDT in setup_idt() that ignores all interrupts. It then uses functions in [include/asm-x86/desc.h (http://lxr.linux.no/linux+v2.6.25.6/include/asm-x86/desc.h#L322) to flesh out common IDT entries in arch/x86/kernel/traps_32.c. In Linux, a gate descriptor with “system” in its name is accessible from user mode and its set function uses a DPL of 3. A “system gate” is an Intel trap gate accessible to user mode. Otherwise, the terminology matches up. Hardware interrupt gates are not set here however, but instead in the appropriate drivers.
在初始化的时候,linux 内核首先在 setup_idt() 建立屏蔽所有中断的 IDT。然后在arch/x86/kernel/traps_32.c
使用 include/asm-x86/desc.h 里的函数(这里指中断处理函数)填充一般 IDT 条目。在 linux ,一个叫 “system” 的门描述符可以从用户态访问,并设置中断处理函数使用 DPL 3。“system gate”是用户态可访问的 intel 陷阱门(系统调用,译者注)。硬件中断门不在这里设置,而是由合适的驱动设置。
Three gates are accessible to user mode: vectors 3 and 4 are used for debugging and checking for numeric overflows, respectively. Then a system gate is set up for the SYSCALL_VECTOR , which is 0x80 for the x86 architecture. This was the mechanism for a process to transfer control to the kernel, to make a system call, and back in the day I applied for an “int 0x80” vanity license plate :). Starting with the Pentium Pro, the sysenter instruction was introduced as a faster way to make system calls. It relies on special-purpose CPU registers that store the code segment, entry point, and other tidbits for the kernel system call handler. When sysenter is executed the CPU does no privilege checking, going immediately into CPL 0 and loading new values into the registers for code and stack (cs, eip, ss, and esp). Only ring zero can load the sysenter setup registers, which is done in enable_sep_cpu()
用户态可以访问三个门:3号 和 4号中断向量,3 号中断用来调试,4 号用来检查数值溢出。然后,在 x86 体系上设置 0x80 号中断作为 SYSCALL_VECTOR(系统调用中断)。系统调用是进行 CPU 控制权转换的机制,早些时候我还申请了个贼牛逼的车牌号 “int 0x80” :)。(作者开了个程序员玩笑,“int 0x80” 在中国可不能作为车牌号,不过看样子在作者的国家可以) 。从奔腾 Pro 开始,引入 sysenter 指令,可以让系统调用更快。sysenter 依靠特殊的 CPU 寄存器保存代码段、调用入口和其他(硬件)周边(tidbits)实现内核系统调用处理。执行 sysenter 指令时 CPU 不做权限检查、直接进入 CPL 0 加载新的代码和栈寄存器值(cs,eip,ss 和 esp)。只有在 ring 0 可以设置 sysenter 使用的寄存器,这个在 enable_sep_cpu() 处理。
Finally, when it’s time to return to ring 3, the kernel issues an iret or sysexit instruction to return from interrupts and system calls, respectively, thus leaving ring 0 and resuming execution of user code with a CPL of 3. Vim tells me I’m approaching 1,900 words, so I/O port protection is for another day. This concludes our tour of x86 rings and protection. Thanks for reading!
最后,我们是时候回到 ring 3了,内核执行 iret 和 sysexit 从中断和系统调用返回,离开 ring 0 继续用 CPL 3 执行用户代码。Vim 告诉我现在接近 1900 个单词了,所以 I/O 端口保护放在后面讲吧。x86 ring 和保护机制的总结就到这里,谢谢阅读!
参考资料:
1.http://www.cis.syr.edu/~wedu/Teaching/CompSec/LectureNotes_New/Protection_80386.pdf
2.https://stackoverflow.com/questions/36617718/difference-between-dpl-and-rpl-in-x86