实验楼实验
跟踪分析Linux内核的启动过程
1.使用实验楼的虚拟机打开shell
2.用cd LinuxKernel/命令进入LinuxKernel目录
3.执行命令qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd roofs.img会发现弹出新的窗口,代表启动构建好了的linux内核
启动结果如下图:

加载根文件系统,init执行后,就看到了MenuOS,内核启动完成后进入menu程序,支持三个命令help、version和quit。可以输入一个help,就可以看到三个命令。

接下来是使用gdb跟踪调试内核
1.执行命令qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd roofs.img -S -s
其中-S是表示在CPU初始化之前就冻结起来,-s是指在-gdb tcp::1234端口上创建了一个gdb server。
冻结结果如下图:

2.再打开一个窗口,用gdb命令打开gdb

3.执行命令file linux-3.18.6/vmlinux把gdb带有debug信息的内核镜像加载进来。

4.执行命令target remote:1234连接到刚刚被冻结的linux系统。
5.执行命令break start_kernel在内核启动的起点设置断点。
![]()
6.执行命令c系统就开始执行了,启动到start_kernel的位置。

7.执行命令list可以查看start_kernel函数。

掌握了方法之后我们还可以设置更多的断点来跟踪内核的启动过程。
简单分析一下start_kernel
输入网址http://codelab.shiyanlou.com/xref/linux-3.18.6/init/main.c查看500行的start_kernel

其中510行的init_task即手共创造的PCB,0号进程即最终的idle进程。不管分析内核的哪一个部分都会涉及到start_kernel,基本上所有的模块都是经过statr_kernel进行初始化。
trap_init()是初始化一些中断向量,mm_init()是内存管理模块的初始化,还有调度模块初始化sched_init()等等如下图所示:
![]()
然后我们看函数的最后一句rest_init()
![]()
进入rest_init()可以发现403行kernel_thread(kernel_init, NULL, CLONE_FS)中有一个kernel_init
向后翻可以看到kernel_init()函数部分代码如下所示:
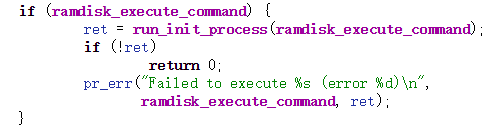
其中run_init_process()是linux系统中的1号进程,就是第一个用户态进程。接下来还创建了一个kthreadd内核线程,管理系统的资源。rest_init()启动完成之后进入cpu_start_entry(),当系统没有进程需要执行时就调度到idle进程。cpu_start_entry()中的cpu_idel_loop()函数中的while(0)就是0号进程。
阅读教材第4、6章
教材主要讲述了进程调度以及内核数据结构的相关知识。
进程调度
多任务
1.多任务操作系统就是能同时并发地交互执行多个进程的操作系统。
2.多任务系统可以划分为两类:非抢占式多任务和抢占式多任务。
Linux的进程调度
1.在Linux2.5开发系统的内核中,调度程序做了大手术。开始采用了一种叫做O(1)调度程序的新调度程序,最终在2.6.23内核版本中代替了O(1)调度算法,它此刻被称为“完全公平调度算法”,或者简称CFS。
策略
1.策略决定调度程序在何时让什么进程运行。
2.进程可以被分为I/O消耗型和处理器消耗型。前者提交I/O请求或是等待I/O请求,后者把时间大多用在执行代码上。
3.调度策略通常要在两个矛盾的目标中间寻找平衡:进程响应迅速(响应时间短)和最大系统利用率(高吞吐量)。
4.Linux采用了两种不同的优先级范围:nice值和实时优先级。越大的nice值意味着更低的优先级,与nice值意义相反,越高的实时优先级数值意味着进程优先级越高。
5.时间片是一个数值,它表明进程在被抢占前所能持续运行的时间。
6.文字编辑程序是I/O消耗型,视频编码程序是处理器消耗型的。
Linux调度算法
1.Linux调度器是以模块方式提供的,这种模块化结构被称为调度器类。
2.完全公平调度(CFS),是一个针对普通进程的调度类,在Linux中称为SCHED_NORMAL,CFS算法实现定义在文件kernel/sched_fair.c中。
Linux调度的实现
1.所有调度器都必须对进程运行时间做记账。
2.进程调度的主要入口点是函数schedule()。
3.休眠的进程处于一个特殊的不可执行状态。进程把自己标记成休眠状态,从可执行红黑书中移出,放入等待队列,然后调用schedule()选择和执行一个其他进程。唤醒的过程刚好相反:进程被设置为可执行状态,然后再从等待队列中移到可执行红黑树中。
4.唤醒操作通过函数wake_up()进行,它会唤醒指定的等待队列上的所有进程。
抢占和上下文切换
1.上下文切换,也就是从一个可执行进程切换到另一个可执行进程。
2.内核即将返回用户空间的时候,如果need_resched标志被设置,会导致schedule()被调用,此时就会发生用户抢占。
3.用户抢占在以下情况时产生:
1)从系统调返回用户空间时。
2)从中断处理程序返回用户空间时。
4.内核抢占会发生在:
1)中断处理程序正在执行,且返回内核空间之前。
2)内核代码再一次具有可抢占性的时候。
3)如果内核中的任务显示地调用schedule()。
4)如果内核中的任务阻塞。
实时调度策略
1.Linux提供了两种实时调度策略:SCHED_FIFO和SCHED_RR。
1)SCHED_FIFO实现了一种简单的、先入先出的调度算法:它不使用时间片。处于可运行状态的SCHED_FIFO级的进程会比任何SCHED_NORMAL级的进程都先得到调度。
2)SCHED_RR与SCHED_FIFO大体相同,只是SCHED_RR级的进程在耗尽事先分配给它的时间后就不能再继续执行了。
内核数据结构
链表
1.链表是Linux内核中最简单、最普通的数据结构。链表是一种存放和操作可变数量元素(常称为节点)的数据结构。
1)双向链表:可以同时向前向后互相连接的链表。
2)单向链表:只能向后连接的链表。
3)环形链表:末尾元素并不指向特殊值,相反,它指回链表的首元素。这种链表因为首尾相连,所以被称为环形链表。环形链表也存在双向链表和单向链表两种形式。
队列
1.任何操作系统内核都少不了一种编程模型:生产者和消费者。生产者将数据推进给队列,然后消费者从队列中摘取数据。
2.第一个进入队列的数据一定是第一个离开队列的。队列也称为FIFO。
3.Linux内核通用队列实现称为kfifo,它提供了两个主要操作:enqueue(入队列)和dequeue(出队列)。
映射
1.一个映射,也常称为关联数组,其实是一个由唯一键组成的集合。,而每个键必然关联一个特定的值。这种键到值的关联称为映射。
二叉树
1.树结构是一个能提供分层的树型数据结构的特定数据结构。
2.一个二叉搜索树(通常简称为BST)是一个节点有序的二叉树,其顺序通常遵循下列法则:
1)根的左分支节点值都小于根节点值。
2)右分支节点值都大于根节点值。
3)所有的子树也都是二叉搜索树。
3.一个平衡二叉搜索树是一个所有叶子结点深度不超过1的二叉搜索树。一个自平衡二叉搜索树是指其操作都试图维持(半)平衡的二叉搜索树。
4.红黑树是一种自平衡二叉搜索树。
数据结构以及选择
1.如果对数据集合的主要操作是遍历数据。就使用链表。
2.如果代码符合生产者/消费者模式,则使用队列。
3.如果需要映射一个UID到一个对象,就使用映射。
4.如果你需要存储大量数据,并且检索迅速,那么红黑树最好。
5.要是上述数据结构都不能满足需要,内核还实现了一些较少使用的数据结构,比如基数和位图。
算法复杂度
1.渐进行为是指当算法的输入变得非常大或接近于无限大时算法的行为。
2.算法就是一系列的指令,它可能有一个或多个输入,最后产生一个结果或输出。
遇到的问题
target remote是加载之前的符号表,符号表主要用来存放源程序中各种有用的信息。包括:变量名、目标地址、类型等。在编译各个阶段需要对这些信息进行访问、增加和更新。但是对于target命令是什么意思就不太清楚了,man target发现并没有target手册页条目,网上也没有解释的很清楚。