NAS论文笔记(aging evolution):Regularized Evolution for Image Classifier Architecture Search
文章目录
- 论文主要工作
- 解决的问题
- 解决方案
- 定义神经网络搜索空间
- 什么是NASNet Search space
- 固定的网络结构
- Cell的结构
- pairwise combination
- Normal Cell
- Reduction Cell
- Cell细胞结构的理解
- 神经网络结构的超参数
- Aging evolution算法
- 算法流程
- 演化操作(MUTATE函数)
- hidden state mutation
- Op mutation
- 为什么如此定义hidden state mutation与Op mutation
- 可用的op操作
- 实验结果
- 在CIFAR-10上比对强化学习和随机搜索的结果
- FLOPS对比
- Aging Evolution在ImageNet上的运用
- 为什么Aging Evolution表现如此优异
- 该算法的不足(个人观点)
论文主要工作
在阅读本论文前,先了解遗传算法的基本操作:遗传算法详解(GA)(个人觉得很形象,很适合初学者)
解决的问题
通过设计一种算法,自动在神经网路架构搜索空间中搜索神经网络,该算法搜索的神经网络需具有较好的准确率,并且运行速度要较快。
解决方案
论文通过对遗传算法中的锦标赛选择法(相应方法请查看:遗传算法-锦标赛选择法)进行改进,将其变为基于年龄的选择法,即aging evolution算法,使得遗传算法更加偏爱年轻个体。实验显示,在相同硬件条件上,该算法相比于强化学习与随机搜索,具有更快的搜索速度。
定义神经网络搜索空间
首先,我们必须得定义一个搜索空间,这个搜索空间含有所有可能搜索到的神经网络结构,由于搜索到的每个神经网络结构都需要通过训练确认准确率,太大的搜索空间会导致算法的运行时间很长,论文选择的搜索空间为NASNet Search space。
什么是NASNet Search space
先来看一幅图
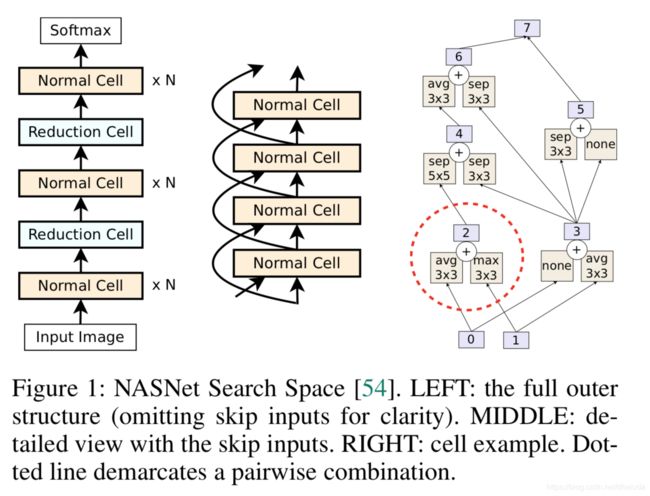
以下讲解均针对上图
固定的网络结构
NASNet Search Space的网络结构如左边图的显示,该搜索空间固定了神经网络的总体结构,通过超参数N控制网络的深度,如中间的图所示,每个cell之间的连接采用残差结构,该搜索空间只搜索对应的Normal Cell与Reduction Cell的结构,企图找到最适合本任务的Normal Cell与Reduction Cell结构
Cell的结构
每个Cell其实由多组操作(op)组成,例如池化、卷积操作等,关于cell的例子可以查看右图,紫色方块表示隐藏状态,其实就是特征图。一个cell的构造过程如下:
- 一个Cell一开始只有两个隐藏状态,即0和1,定义pairwise combination操作的次数
- 随机选择两个隐藏状态,对这两个隐藏状态施加pairwise combination操作,从而得到新的隐藏状态
- 重复步骤二,直到用完pairwise combination操作次数
pairwise combination
pairwise combination的操作如下
- 对两个隐藏状态分别施加一个op操作,例如avg操作、max操作、卷积操作
- 将步骤一的结果相加,得到新的隐藏状态
pairwise combination的例子可以查看右图中的虚线框部分,最后,所有未使用过的隐藏状态将concat在一起,例如图中的隐藏状态5和6
Normal Cell
在NASNet Search Space中,所有的Normal Cell具有相同的结构,Normal Cell不会降低特征图的大小
Reduction Cell
在NASNet Search Space中,所有的Reduction Cell具有相同的结构,Reduction Cell的过后会使用步伐数为2的卷积,会降低特征图的大小
Cell细胞结构的理解
为什么要选择两个特征图(隐藏状态),对其进行op操作后相加呢?在某些情况下,这其实是一个残差结构,意味着在NASNet Search Space中进行搜索时,算法会自动探索如何添加残差结构,但是这种残差结构不一定就是何凯明大佬论文中所说的直接映射后相加,而是更加的灵活,可以是直接映射相加,也可以是施加了op操作相加,例如右图所示的0、1、3节点,就是经典的残差结构(0号节点比1号节点浅,1号节点通过avg操作得到一个新的特征图,设为temp,temp与比自己要浅的0号节点相加,就是一个经典的残差结构)
神经网络结构的超参数
该神经网络结构含有两个超参数
- N:一个stack中Normal Cell的个数
- F:卷积操作中过滤器的个数
Aging evolution算法
算法流程
伪代码如下:

具体而言,算法具体步骤如下
- 随机初始化P个神经网络结构,将其加入到队列中,形成一个种群,并进行训练
- 对种群进行采样,选择S个神经网络
- 采样得到S个神经网络,选择其中准确率最高的神经网络作为父母
- 对其进行演化(变异)操作,获得新的神经网络结构,训练该网络,将其加入到种群中,即队列的最右侧
- 去除种群中年龄“最大”的神经网络,其实就是队列最左边的元素
- 回到步骤二,循环一定次数
该算法中的P、C、S的值自行指定
Aging evolution算法模拟了自然界中的物种繁衍的操作
- 自然界中,表现优异的个体往往更加容易留下后代。Aging evolution算法通过采样形成一个候选集,选择候选集中准确率最高的神经网络(表现最优异的个体)进行繁衍,以此模拟这个过程
- 在自然界中,年轻的个体相比于年老的个体一般具有更好的潜能,更有可能留下后代。Aging evolution算法每次会去除种群中一个最老的个体,并加入一个新个体,以此模拟这个过程
- 在自然界中,后代往往会遗传父母的一些特征,并在此基础上进行变异。Aging evolution算法选定一个神经网络,对该神经网络进行MUTATE操作,得到的新神经网络的结构既有与父母神经网络相同的部分(遗传),又有不同的部分(变异),以此模拟这个过程
演化操作(MUTATE函数)
演化操作具体步骤如下:
- 判断是否对Normal Cell或是Reduction Cell进行演化操作
- 选定演化操作,演化操作分为两类:hidden state mutation和op mutation,每次循环只会选中其中一个演化操作
hidden state mutation
该演化过程的步骤如下:
- 随机选定该cell的一个pairwise combination,对其进行操作
- 选中一个element,一个element由一个隐藏状态与其对应的op操作组成,将该op操作的对象变为另外一个隐藏状态
具体的例子例子如下:

隐藏节点3与avg操作构成一个element,经过hidden state mutation操作后,avg操作的对象变为了隐藏节点4
Op mutation
该演化过程的步骤如下:
- 随机选定该cell的一个pairwise combination,对其进行操作
- 选中一个op操作,将该op操作替换为另外一个随机op操作
具体的例子例子如下:
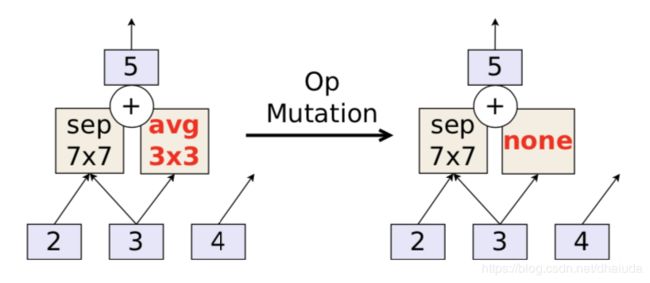
为什么如此定义hidden state mutation与Op mutation
这两个演化操作其实可以探索定义的NASNet Search space,我们的目的是为了搜索Normal Cell与Reduction Cell的结构,一个Cell的结构由五对pairwise combination组成,一个pairwise combination需要解决下面两个问题:
- 两个隐藏状态是什么
- 对两个隐藏状态施加的op操作是什么
而hidden state mutation解决了第一个问题,Op mutation解决了第二个问题,通过交替使用这两个演化操作,即可探索NASNet Search space中可能的神经网络结构
可用的op操作
Op mutation需要随机选定一个用于替换原op操作的op操作,具体如下:
- 不改变
- 3x3, 5x5 and 7x7 sep conv
- 3x3 average pool
- 3x3 max pool
- 3x3 dilated sep conv
- 1x7 then 7x1 conv
实验结果
在CIFAR-10上比对强化学习和随机搜索的结果

比对不同算法运行速度的指标:在相同硬件上生成20k个模型所需要的运行时间
结果:可以看到aging evolution的速度比RL和RS要快,并且探索到的模型准确率较高
这幅对比图没有将模型的计算成本显示出来
FLOPS对比
论文将FLOPS定义为前向传播中所需的总操作数,操作数越少越好(论文并未具体解释这里的操作数是指什么,应该是计算成本吧),与RL和RS训练好的模型的对比如下:
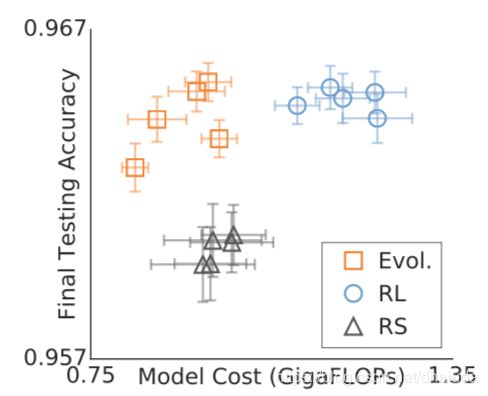
由此可以见,相比于RS,Aging Evolution具有更好的测试准确率,且两者模型的FLOPS近似,相比于RL,Aging Evolution具有更低的FLOPS,两者模型具有相似的测试准确率
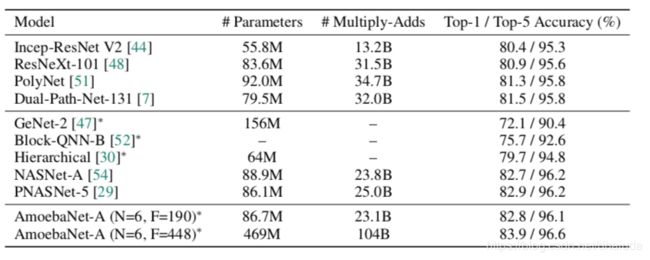
Aging Evolution在ImageNet上的运用
值得注意的是,在ImageNet上训练的网络AmoebaNet-A的细胞结构是基于CIFAR-10上发现的,而不是在ImageNet上运行Aging Evolution算法,根据下表,可知AmoebaNet-A具有最高的准确率。
为什么Aging Evolution表现如此优异
论文作者认为Aging Evolution有利于抵抗训练噪声,训练噪声是指某些模型由于运气好,达到了较高的准确率,这种准确率并不是由于网络架构好引起的,在锦标赛算法中,此类模型可能存在于整个算法运行过程中,留下大量后代,由于后代更多,算法会更加偏好于此类架构,从而减少对于搜索空间的充分探索,而在Aging Evolution中,模型不断更新换代,即使某一类架构由于运气好达到了较好的准确率,最终也会被淘汰,并且采样数S的存在意味着运气好的架构不一定就能留下后代。
由于种群更新换代的速度很快,只有让自己的后代不断保持较好的准确率,该类网络架构才能长期存在于种群之中,一定程度上抵抗训练噪声,即正则化。因此,Aging Evolution更加关注模型的架构,而不是模型本身,因为再高准确率的模型最终也会被淘汰
论文构造了一个Toy Search space,在该搜索空间上使用了Aging Evolution,最终取得了较好的结果,由此证明了上述猜测
该算法的不足(个人观点)
- 算法一开始需要随机初始化一批网络架构,有可能此类网络结构都是很糟糕的,没有利用任何先验知识,可能导致算法的运行结果很糟糕
- 算法的运行时间会很长,因为得到一个新网络架构就需要重新训练,此类问题可以通过神经网络的性能预测解决(没看),Aging Evolution本质上也只是随机搜索➕选择操作
- 算法运行后得到的Cell结构很难解释为何这种结构具有优越性
论文没解释该算法为什么要在NASNet Search Space上进行搜索,关于NASNet Search Space需要自行阅读另一篇文献《 Learning transferable architectures for scalable image recognition》
另外自己对于该算法的收敛速度不是很自信,论文中并没有对该算法的实现公开具体的代码,公开的代码是Toy Search Space上的操作