目录
- 1.学习论文的总结
- Part1背景介绍:为什么要用CNN(卷积神经网络)对句子分类?
- Part2模型介绍
- Part3数据集
- Part4实验结论
- Part5论文复现
- 2.学习中遇到的问题及解决
- 3.参考资料
课程:《密码与安全新技术专题》
班级:1892
姓名:杨
学号:20189230
上课教师:王志强
上课日期:2019年5月21日
必修/选修:选修
1.学习论文的总结
论文名称:Convolutional Neural Networks for Sentence Classification(卷积神经网络用于句子分类)
论文来源:自然语言处理领域顶级国际会议EMNLP2014
| 文献原文,全篇翻译和课堂介绍所用PPT可以通过链接下载:https://pan.baidu.com/s/19uKDPYW5QtX_ky1ldMbvTg,提取码:m81o |
Part1背景介绍:为什么要用CNN(卷积神经网络)对句子分类?
(1)特征提取的高效性
机器学习首先需要选取好特征,每一个特征即为一个维度,特征数目过少,我们可能无法精确的分类出来,即我们所说的欠拟合;如果特征数目过多,可能会导致我们在分类过程中过于注重某个特征导致分类错误,即过拟合。这样就需要我们在特征工程上花费很多时间和精力,才能使模型训练得到一个好的效果。然而神经网络的出现使我们不需要做大量的特征工程,譬如提前设计好特征的内容或者说特征的数量等等,我们可以直接把数据灌进去,让它自己训练,自我“修正”,即可得到一个较好的效果。
(2)数据格式的简易性
在一个传统的机器学习分类问题中,我们“灌”进去的数据是不能直接灌进去的,需要对数据进行一些处理,譬如量纲的归一化,格式的转化等等,不过在神经网络里我们不需要额外的对数据做过多的处理。
(3)参数数目的少量性
在面对一个分类问题时,如果用SVM来做,我们需要调整的参数包括核函数,惩罚因子,松弛变量等等,不同的参数组合对于模型的效果也不一样,想要迅速而又准确的调到最适合模型的参数需要对背后理论知识的深入了解(当然,如果全部都试一遍也是可以的,但是花的时间可能会更多)。对于一个基本的三层神经网络来说(输入-隐含-输出),我们只需要初始化时给每一个神经元上随机的赋予一个权重w和偏置项b,在训练过程中,这两个参数会不断的修正,调整到最优质,使模型的误差最小。所以从这个角度来看,我们对于调参的背后理论知识并不需要过于精通(只不过做多了之后可能会有一些经验,在初始值时赋予的值更科学,收敛的更快罢了)。
尤其是在图像领域,用传统的神经网络并不合适。因为图像是由一个个像素点构成,每个像素点有三个通道,分别代表RGB颜色,那么,如果一个图像的尺寸是(28,28,1),即代表这个图像的是一个长宽均为28,channel为1的图像(channel也叫depth,此处1代表灰色图像)。如果使用全连接的网络结构,即,网络中的神经与与相邻层上的每个神经元均连接,那就意味着我们的网络有28 * 28 =784个神经元,hidden层采用了15个神经元,那么简单计算一下,我们需要的参数个数(w和b)就有:7841510+15+10=117625个,这个参数太多了,随便进行一次反向传播计算量都是巨大的,从计算资源和调参的角度都不建议用传统的神经网络。
Part2模型介绍
下图是原论文中给出的用于句子分类的CNN模型:
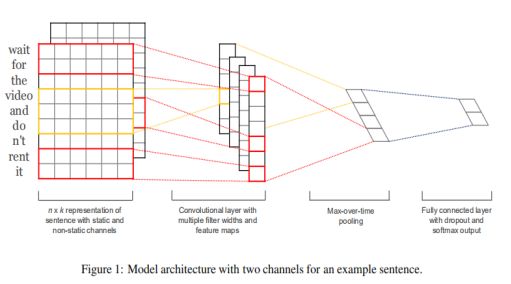
用一张释义更明确的图来讲解该模型的结构:

| 输入矩阵 |
CNN输入矩阵的大小取决于两个因素:
A.句子长度(包含的单词的个数)
B.每个字符的长度
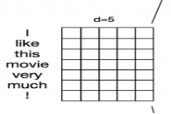
假设输入X包含m个单词,而每个单词的字嵌入(Word Embedding)长度为d,那么此时的输入就是m d的二维向量。对于I like this movie very much!来说,当字嵌入长度设为5时,输入即为75的二维向量。
| 卷积过程 |
文中使用了2种过滤器(卷积核),每种过滤器有三种高度(区域大小),即有6种卷积结构。每个卷积核的大小为filter_size embedding_size。

A.filter_size代表卷积核纵向上包含单词个数,即认为相邻几个词之间有词序关系,代码里使用的是[3,4,5]。
B.embedding_size就是词向量的维数。每个卷积核计算完成之后我们就得到了1个列向量,代表着该卷积核从句子中提取出来的特征。有多少卷积核就能提取出多少种特征。
| 池化过程 |
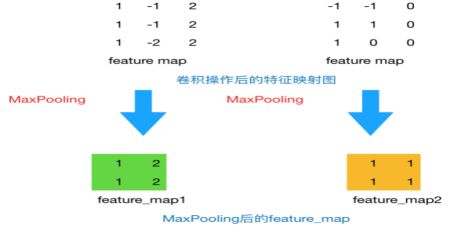
这篇文章使用MaxPooling的方法对Filter提取的特征进行降维操作,形成最终的特征。每个卷积的结果将变为一个特征值,最终生成一个特征向量。
以下图为例,池化层采用MaxPooling,大小为22,步长为1,取每个窗口的最大值更新,那么图片的尺寸会由3 3变成22。
注意:这一步统一了维度!
补充:池化方法一般有两种:MaxPooling:取滑动窗口里最大的值;AveragePooling:取滑动窗口内所有值的平均值。
| 全连接层(含Dropout和Softmax) |
A.要处理的问题
二分类问题:正面评价;负面评价。
B.全连接层
把权重矩阵与输入向量相乘再加上偏置,实际上就是三层神经网络的隐层到输出层的映射。

C.添加Dropout
由于实验中所用的数据集相对较小,很容易就会发生过拟合现象,所以要引入Dropout来减少过拟合现象。
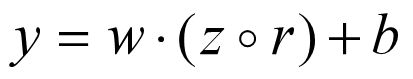
神经元激活的概率,可以在参数 dropout_keep_prob 中设置。这篇文章里选择的是0.5。
D.Softmax分类层
我们可以应用Softmax函数来将原始分数转换为归一化概率,从而得到概率最大的输出,最终达到预测的目的。
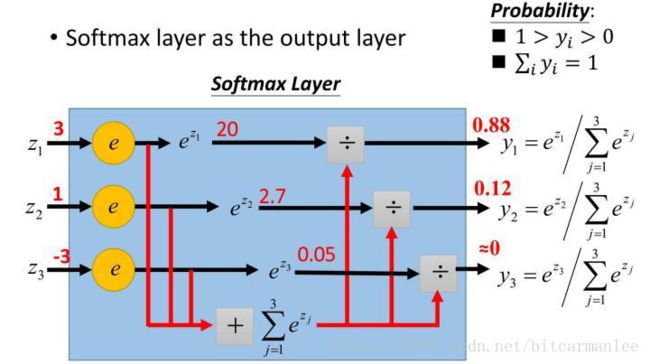
补充:Dropout的作用原理
按照一定的概率来“禁用”一些神经元的发放。这种方法可以防止神经元共同适应一个特征,而迫使它们单独学习有用的特征。
Part3数据集
(1)文章中使用的数据集包括:
•MR:电影评论,每次评论一句话。分类包括检测积极/消极的评论。
•SST-1:Stanford Perfection Treebank是MR的扩展,但提供了train/dev/test分割和细粒度标签(非常积极、积极、中立、消极、非常消极)。
•SST-2:与SST-1相同,但删除中立评论。•Subj:主观性数据集,将句子分类为主观性或客观性两种。
•TREC:数据集将问题分为6种类型(是否涉及人员、位置、数字信息)。
•CR:客户对各种产品(相机、MP3等)的正面/负面评论。
•MPQA:用于意见极性检测。
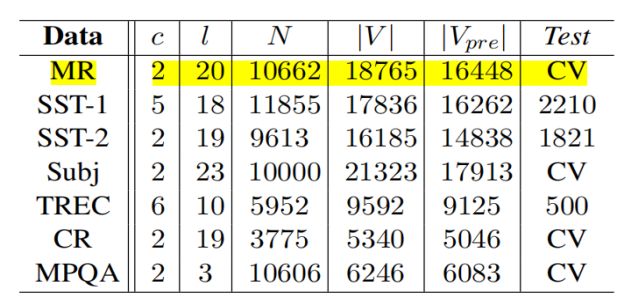
其中,c是目标类的数目;l是语句平均长度;N是数据集大小;|V|是词典大小;|Vpre|是预先训练过的单词向量集中出现的单词数;Test是测试集的大小(CV:没有训练/测试集的划分,因而采用十折交叉验证的方法。
(2)复现时使用的是MR(Movie Review data from Rotten Tomatoes),来自烂番茄的电影评论数据。数据集包含10662个示例评论句,半正半负。词汇表大小约为20k。由于此数据集非常小,使用强大的模型可能会造成过拟合。此外,数据集没有进行train/test分割,因此我们将数据集分成十份,轮流将其中9份作为训练数据,1份作为测试数据。10次结果的平均值作为对算法精度的估计(十折交叉验证)。
A.数据清洗:将重复、多余的数据筛选清除,将缺失的数据补充完整,将错误的数据纠正或者删除,最后整理成为我们可以进一步加工、使用的数据。
B.数据集里最大的句子长度为59,因此为了更方便地进行批处理,需要用0将其他句子填充到这个长度。填充操作并不会对结果造成大的影响,因为最后的MaxPooling会选取最大特征值。
C.构建词汇索引表,将每个单词映射到 0 ~ 18765 之间(18765是词汇量大小),那么每个句子都变成了一个向量。
D.批处理。
Part4实验结论
(1)Model Variations
A.CNN-rand:所有的word vector都是随机初始化的,同时当做训练过程中优化的参数;
B.CNN-static:所有的word vector直接使用无监督学习即Google的word2vector工具得到的结果,并且是固定不变的;
C.CNN-non-static:所有的word vector直接使用无监督学习即Google的word2vector工具得到的结果,但是会在训练过程中被微调;
D.CNN-multichannel:CNN-static和CNN-non-static的混合版本,即两种类型的输入。
本文实现的CNN模型及其变体在不同的数据集上和前人方法的比较:
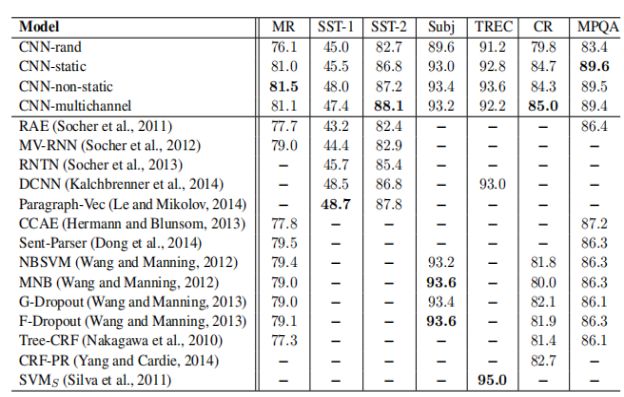
(2)结论
A.CNN-static优于CNN-rand,因为采用训练好的word2vector向量利用了更大规模的文本信息,提高acc;
B.CNN-non-static优于CNN-static,因为BP算法微调参数使得word2vector更加贴近于某一个具体的任务,提高acc;
C.CNN-multichannel在小规模数据集上的表现优于CNN-single。它体现的是一种折中思想,即既不希望微调参数后的word2vector距离原始值太远,但同时保留其一定的变化空间。
(3)其他结论(十分有趣哦❤)
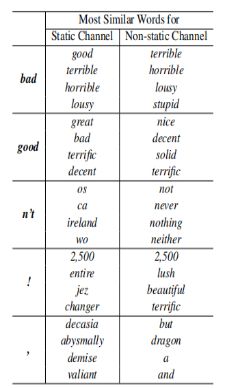
A.CNN-static中,bad对应的最相近词为good,原因是这两个词在句法上的使用是极其类似的(可以简单替换,不会出现语句毛病);而在CNN-non-static的版本中,bad对应的最相近词为terrible,这是因为在微调参数的过程中,word2vector的值发生改变从而更加贴切数据集(是一个情感分类的数据集),所以在情感表达的角度这两个词会更加接近;
B.句子中的!最接近一些表达形式较为激进的词汇,如lush(酷)等;而,则接近于一些连接词,这和我们的主观感受也是相符的。不过在某种程度上这种"过度推断"容易造成过拟合,因而作者将这两种词向量作为了输入层不同的channel来进行训练,取得了还不错的效果。
Part5论文复现
| 运行环境 |
Windows10;
Anaconda 2019.03;
Python 3.7.3;
Tensorflow1.13.1(CPU版);
TensorBoard 1.13.1。
| 训练/测试集的划分:activate tensorflow——导入数据集rt-polaritydata——python train.py——python eval.py |
十折交叉验证(10-fold cross-validation)是一种常用的测试方法:将数据集分成十份,轮流将其中9份作为训练数据,1份作为测试数据,进行试验。每次试验都会得出相应的正确率(或差错率)。10次的结果的正确率(或差错率)的平均值作为对算法精度的估计。

| step=30000(步进值为1) |
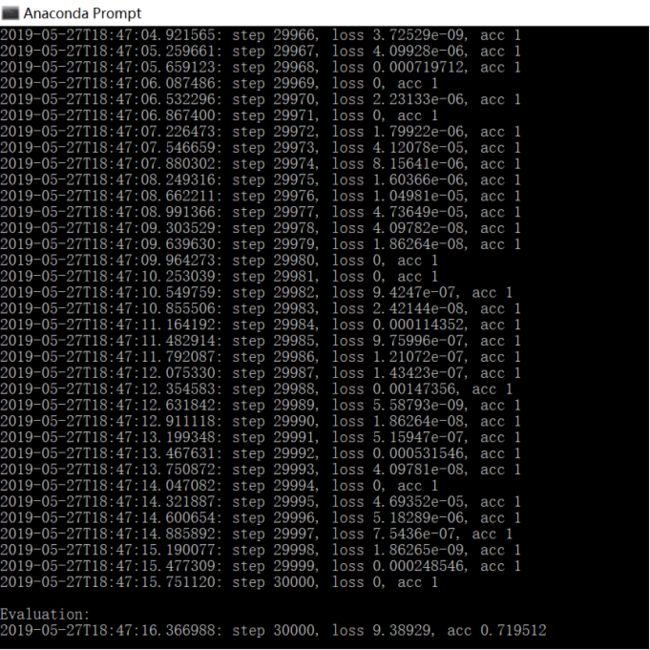

从图中可以看出,loss值不断下降,acc值最终达到0.753982。
| Tensorboard可视化 |
tensorboard.exe--logdir="C:\Users\yangxiaopang\Desktop\cnn-text-classification-tf-master\runs\1558944107\summaries\train"——用Chrome浏览器打开http://LAPTOP-4731L8IJ:6006即可

A.卷积神经网络结构图(含节点及关联关系)
Main Graph和Auxiliary Nodes——
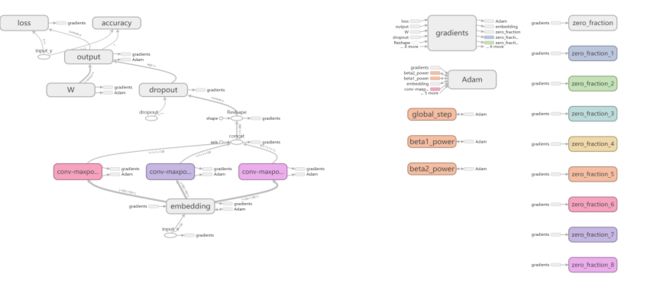
conv maxpooling4局部节点——
B.Model Variations(4种)的acc和loss值
命令语句分别为:
使用随机初始化的词向量进行训练:python train.py --input_layer_type 'CNN-rand';
使用与训练好的GloVe 词向量训练,在训练过程中词向量不可训练,是固定的:python train.py --input_layer_type 'CNN-static';
使用与训练好的GloVe 词向量训练,在训练中微调词向量:python train.py --input_layer_type 'CNN-non-static';
使用两个词向量组成双通道作为输入,一个固定,另一个可以微调:python train.py --input_layer_type 'CNN-multichannel'。
acc值:
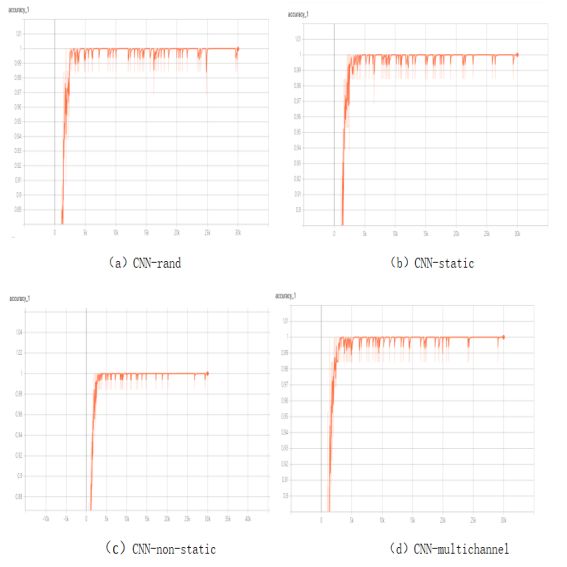

loss值:
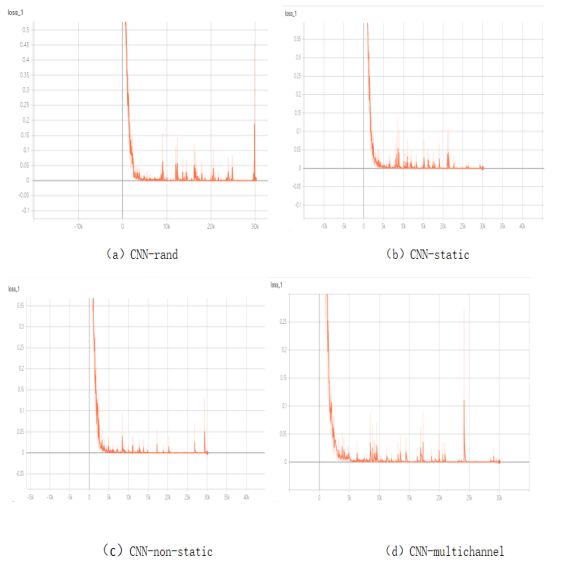
由上面的图表可知,四种Model Variations的acc值较原论文中偏小,但是相互间的大小关系和原论文中一致。
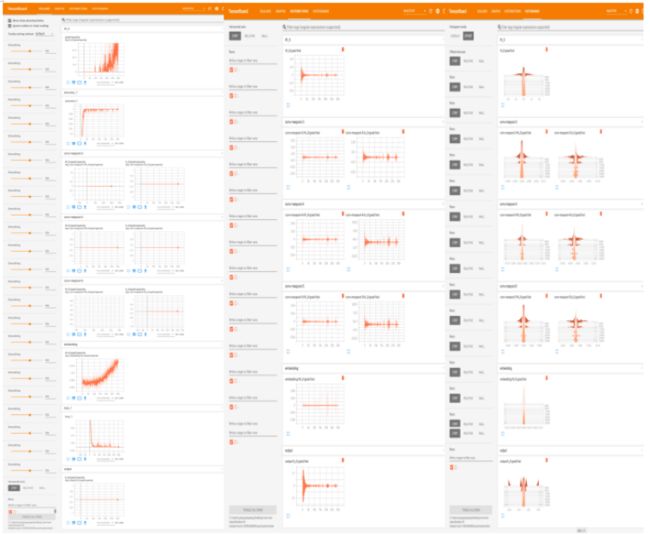
C.其他可视化结果
标量Scalars/数据分布Distribution /直方图Histograms
D.改进方向
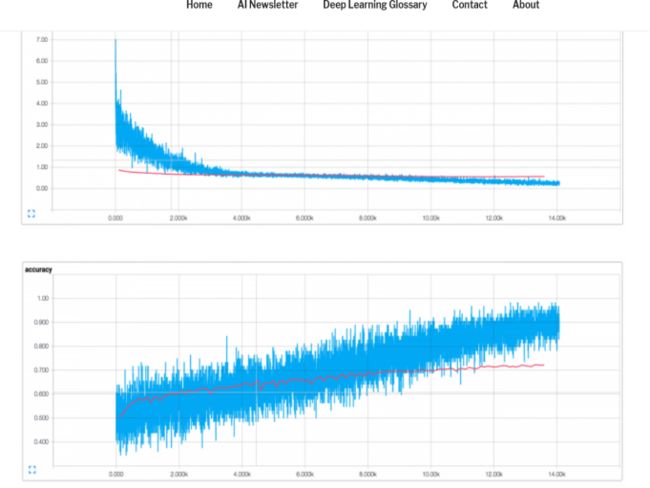
如上图,测试集(红)的精度明显低于训练集(蓝)(CNN-static),表明过拟合了。要想改进实验,我们需要更多的数据、更强的正则化或更少的模型参数。
2.学习中遇到的问题及解决
- 问题1:究竟什么是Word Embedding?
- 问题1解决方案:
Word Embedding本质是将文本数据转换为数值型数据,可以看成一种映射。
举例——“apple on a apple tree”
(1)Word Embedding的输入是原始文本中的一组不重叠的词汇,即一个dictionary:["apple", "on", "a", "tree"]。
(2)Word Embedding的输出就是每个word的向量表示。使用最简单的one hot编码方式,那么每个word都对应了一种数值表示。
例如,apple对应的vector就是[1, 0, 0, 0],a对应的vector就是[0, 0, 1, 0]。
由上例,Word Embedding实质上是特征提取器,在指定维度中编码语义特征。
语义相近的词, 它们的欧氏距离或余弦距离也比较近。
这时候的句子就自然而然地成为了自然语言处理中的“图像”。
Word Embedding主要分为以下两类:
基于频率的Word Embedding(Frequency based embedding);
基于预测的Word Embedding(Prediction based embedding)。 - 问题2:究竟什么是Word2Vector?
- 问题2解决方案:
Word2Vector本质就是进行词向量化,使得机器能够处理文字类型的数据(文本)。
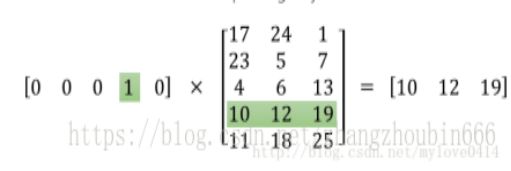
(1)发展历史:在Word2Vector出现之前,对于自然语言的处理的词的向量化使用的是One-Hot Encoder。它的特点是:词向量维度大小为整个词汇表的大小,对于每个具体的词汇表中的词,将对应的位置置为1。比如我们有下面的5个词组成的词汇表,词"Queen"的序号为2, 那么它的词向量就是(0,1,0,0,0)(0,1,0,0,0)。同样的道理,词"Woman"的词向量就是(0,0,0,1,0)(0,0,0,1,0)。
(2)One-Hot Encoder的缺点:过于稀疏;不能体现词与词之间的关系;对于词量大时会出现维度灾难。
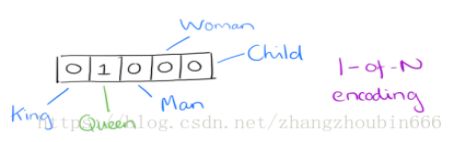
(3)解决办法:使用Vector Representations可以有效解决这个问题。Word2Vector可以将One-Hot Encoder转化为低维度的连续值,也就是稠密向量,并且其中意思相近的词将被映射到向量空间中相近的位置。 我们可以发现,华盛顿和纽约聚集在一起,北京上海聚集在一起,且北京到上海的距离与华盛顿到纽约的距离相近。也就是说模型学习到了城市的地理位置,也学习到了城市位置之间的关系。

有了用Dristributed representation表示的较短的词向量,我们就可以较容易的分析词之间的关系了,比如我们将词的维度降维到2维,有一个有趣的研究表明,用下图的词向量表示我们的词时,我们可以发现:King−Man+Woman=Queen。
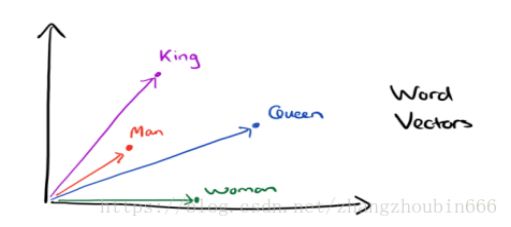
(4)模型拆解
Word2Vector模型其实就是简单化的神经网络。
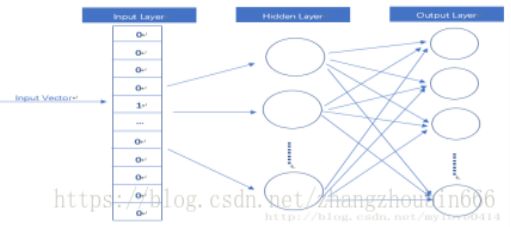
输入是One-Hot Vector,Hidden Layer没有激活函数,也就是线性的单元。Output Layer维度跟Input Layer的维度一样,用的是Softmax回归。我们要获取的dense vector其实就是Hidden Layer的输出单元。有的地方定为Input Layer和Hidden Layer之间的权重,其实说的是一回事。
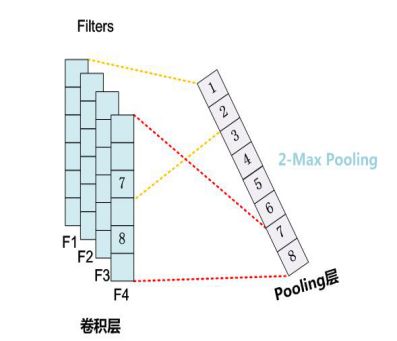
- 问题3:池化层还可以进一步改进以提高模型提取特征的能力么?
问题3解决方案:用其他池化方法
(1)K-MaxPooling——
原先的Max Pooling从Convolution层一系列特征值中只取最强的那个值,那么我们思路可以扩展一下,K-Max Pooling可以取所有特征值中得分在Top-K的值,并保留这些特征值原始的先后顺序,就是说通过多保留一些特征信息供后续阶段使用。
很明显,K-Max Pooling可以表达同一类特征出现多次的情形,即可以表达某类特征的强度;另外,因为这些Top-K特征值的相对顺序得以保留,所以应该说其保留了部分位置信息,但是这种位置信息只是特征间的相对顺序,而非绝对位置信息。
(2)Chunk-Max Pooling——
把某个Filter对应的Convolution层的所有特征向量进行分段,切割成若干段后,在每个分段里面各自取得一个最大特征值,比如将某个Filter的特征向量切成3个Chunk,那么就在每个Chunk里面取一个最大值,于是获得3个特征值。
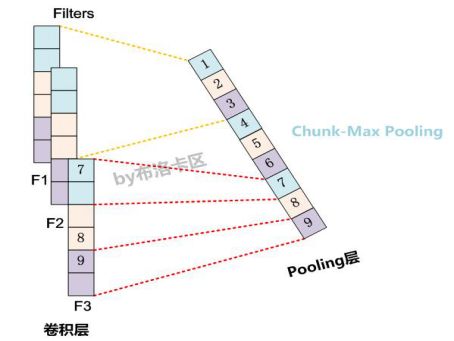
K-Max Pooling是一种全局取Top-K特征的操作方式,而Chunk-Max Pooling则是先分段,在分段内包含特征数据里面取最大值,所以其实是一种局部Top-K的特征抽取方式。3.学习感想和体会
通过这次论文学习与报告总结的工作,我收获良多。
(1)在选择论文进行复现的阶段,我选择了我一直特别感兴趣的深度学习领域的论文来进行复现,但是说到底,这种“兴趣”一直停留在“兴趣”层面。研一一年,我的研究方向一直集中在指静脉识别领域,所阅读的论文和复现的工作一直是使用传统的方法来进行特征的提取,进而加密。但是指静脉领域当前的研究热点主要集中在通过机器学习方法来对样本数较少的数据集进行识别。
出于为将来的工作打基础的考虑,我选择了一篇用卷积神经网络对句子进行分类的自然语言处理领域的经典文章来进行复现。在查找选择的过程中,我了解到有许多提供开源代码和相应论文的网站,上面的种类也有很多,比如:Papers with Code。首先在自然语言处理(NLP)领域,我了解到分类主要包括:Machining Translation,Language Modeling,Question Answering,Sentiment Analysis以及Natural Language Inference等等。其次。在选择论文的过程中,我了解到7种基本的深度学习工具的基础知识及使用。其中常用的有以下几种:
A.TensorFlow
TensorFlow是Google基于DistBelief进行研发的第二代人工智能学习系统,其命名来源于本身的运行原理。Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,TensorFlow为张量从图像的一端流动到另一端的计算过程。TensorFlow是将复杂的数据结构,传输至人工智能神经网中进行分析和处理过程的系统。TensorFlow表达了高层次的机器学习计算,可被用于语音识别或图像识别等多项机器深度学习领域。TensorFlows对2011年开发的深度学习基础架构DistBelief进行了各方面的改进,可在小到一部智能手机,大到数千台数据中心服务器的各种设备上运行。TensorFlow完全开源。
B.Caffe
Caffe是一个清晰而高效的深度学习框架,作者是毕业于UC Berkeley的贾扬清。Caffe的全称应该是Convolutional Architecture for Fast Feature Embedding,它是开源的,核心语言是C++,支持命令行、Python和MATLAB接口。既可以在CPU上运行也可以在GPU上运行。License是BSD 2-Clause。Caffe可以应用在视觉、语音识别、机器人、神经科学和天文学领域。
C.Torch
Torch已经存在了十多年的时间,是一个广泛支持机器学习算法的科学计算框架,具有简单和快速的脚本语言LuaJIT和底层C/CUDA实现, Facebook开源了Torch深度学习库包。
Torch的特点包括:具有强大的n维数组;具有丰富的索引、切片和transposing的例程;通过LuaJIT的C接口;线性代数例程;基于能量的神经网络模型;数值优化例程;支持快速高效的GPU;可移植嵌入到iOS、Android和FGPA平台。
❤最终我选择用Tensorflow来实现一个简单的用于文本分类的卷积神经网络❤
(2)在整个阅读论文、理解论文、复现论文的过程中,我意识到自己在“读论文”这方面还存在很大的不足。拿到一篇论文,先翻译成中文读一遍,在读一遍英文确认细节,看似好像没有问题,也算是“完成了任务 ”,但是对于一篇好论文来说是远远不够的。论文中的精髓部分还是没有学习和领会到,只是草草了事罢了。我认为要想读好一篇论文,读懂表面意思只是第一步,第二步也是最重要的一步就是尝试去复现论文里所作的工作。在复现的过程中,一遍遍地去读论文,五遍十遍都不为过,每一遍都能有新的体会,新的思考,读完每一遍都能发现上一遍自己陷入了哪些误区,哪些知识点自以为懂了,但是其实没有。我觉得这个过程是令人欣喜的,令人不断地思考自己在学习的过程中存在哪些不足。作者为什么要选取这种方法,作者是如何建立模型的,针对某一类问题选择这个模型的依据在哪里。为了复现论文里的工作,首先我的数据集从哪里来,在这样一个小数据集的情况下,我怎么去划分训练集和测试集。我如何选取一个单变量,从而形成对比。在训练时,参数如何选取,这个参数是始终确定的,还是不断根据模型更新的。这些都是需要考虑的问题。我一开始觉得这些都是细节,但是时间久了才发现,“由小见大”,“因小失大”说的都是细节处见真知的道理。
(3)在这次论文复现的过程中,我的另一个重要感想就是凡事不能到了眼前再打算。一开始觉得一周时间搞定一篇论文绰绰有余,可是当事情真的逼到眼前了,才发现这个时候可能还有其他事的存在会影响自己的进度。不知不觉中,研一已经过去了。在这一年里,有收获也有对不足的反思。希望从现在开始,抓紧时间,多读论文,投身科研吧!
3.参考资料
Papers with Code
深度学习工具介绍
Convolutional Neural Networks for Sentence Classifification
Convolutional Neural Network for Text Classification in Tensorflow
Word Embedding的发展和原理简介
Word2Vector
TensorBoard可视化工具
softmax函数详解
自然语言处理中CNN模型几种常见的Max Pooling操作
Implementing a CNN for Text Classification in TensorFlow