大型网站技术架构 读书笔记4 高可用架构
说句掏心窝的话,高可用甚至比高性能更重要。为什么?
因为你把系统的性能优化10倍,你的老板可能会说:小董呀,干的不错。
可是,如果你负责的模块,三天两头就宕掉了,嘿嘿,你懂得。
可用性度量
99%-----网站年度不可用时间小于88个小时
99.9%---网站年度不可用时间小于9个小时
99.99%---网站年度不可用时间小于53分钟
所以,高可用架构的主要目的就是保证服务器硬件故障时,服务依然用。
主要手段就是冗余与备份。一旦某个服务器出了问题,就把服务切换到别的可用的服务器上。
典型的网站架构如下图:

数据层好解释,我这里就说说应用层与服务层。
应用层是具体的业务逻辑
而服务层就是可以复用额服务。
应用层的服务器是通过负载均衡设备组合到一起的,如果某个服务器不可用,负载均衡服务设备会通过心跳检测设备知道,并且把失效的服务器地址从自己的集群列表中剔除。
服用层的服务会被应用层的业务通过分布式服务框架调用(如dubbo),多个服务会通过注册中心管理(如zookeeper),当某个服务器失效了,注册中心就会剔除不可用的地址。
数据层的服务器一般进行数据同步复制。一旦一台服务器出问题了,新的请求就会被转发到还正常的服务器上。
另外,网站除了因为硬件故障会导致服务不可用外,系统升级更新也会出现不可用的问题,所以,系统的升级更新我们也要考虑。
下面我们就从,应用,服务,数据三个层次来说说如何具体实现高可用
对于没有状态的服务器来说,比较简单,直接最简单的负载均衡就OK
对于那些有状态的服务器,其实复杂的是session,第一次访问在服务器a,session也在服务器a上,第二次请求被分配到b上了,可b里面有吗session。
对于session的管理,也分几种
1 session复制,也就是说 n台服务器的集群中,每一台服务器都有所以的session信息。 如果服务器一多,用户量一多,这个方案就不合适了。
2 session绑定,让a用户只访问服务器a,用户b也只访问某一台服务器。 如果一旦服务器a宕掉了,用户a怎么办?
3 利用cookie,
除此之外,我们还有一些别的小建议
1 分级管理 让核心应用使用高性能的硬件 (用户付款就比之后的评价反馈要显得核心一些)
2 超时设置 如果n个单位时间内,没有响应,就重新发请求。
5 幂等性设计 这不能说是一个建议,而应该是一个要求,就是保证某个服务调用一次与调用n次的效果是一致的。
因为应用端如果没有收到反馈就会再次调用服务端(此时可能已经调用成功了,只是应用端没有收到而已)
数据备份与失效转移
前者保证数据不丢失,后者保证随时能访问到正确的数据。
那么具体的说,什么是高可用数据呢?或者说,高可用体现在哪里呢?
1 数据持久性 -----技术发生存储故障,数据也是存在的。
2 数据可访问性 ----某个数据服务器发生了问题,能很快(用户几乎没有感知)切换用户的访问到新的数据服务器
3 数据一致性
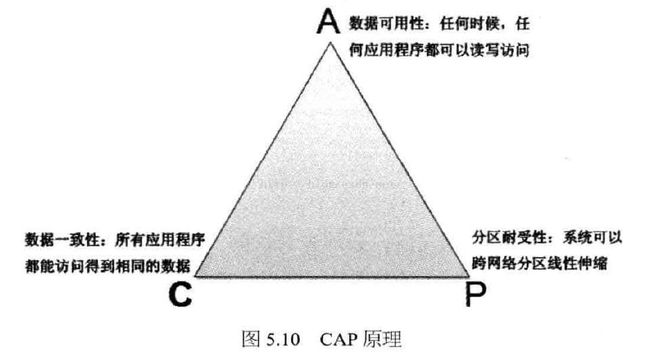
我们一般认为,系统无法同时满足数据一致性(Consistency),数据可用性(Availibility),分区耐受性(Partition Tolerance,跨网络分区的伸缩性)
一般来说数据一致性也分下面几个情况
3.1 数据强一致性 各个副本的数据是一样的,这一点在数据更新时保证
3.2 数据用户一致性 各个副本的数据是一样的,但是用户获得数据时会校验,保证用户得到的数据是正确的
3.3 数据最终一致性 物理存储的数据是不一样的,用户获得的数据也是不同的(同一用户多次访问,多个用户同时访问),不过过一段时间(通常较短),物理信息会自动一致。
大型网站一般会选择强化可用性与分区耐受性,一定程度上放弃一致性。
因为你把系统的性能优化10倍,你的老板可能会说:小董呀,干的不错。
可是,如果你负责的模块,三天两头就宕掉了,嘿嘿,你懂得。
可用性度量
99%-----网站年度不可用时间小于88个小时
99.9%---网站年度不可用时间小于9个小时
99.99%---网站年度不可用时间小于53分钟
高可用架构
一般的互联网公司大多采用pc级服务器,开源的数据库和操作系统,这样来说,当然节省成本,不过另一方面来说,服务器宕机就是一个大概率事件了。所以,高可用架构的主要目的就是保证服务器硬件故障时,服务依然用。
主要手段就是冗余与备份。一旦某个服务器出了问题,就把服务切换到别的可用的服务器上。
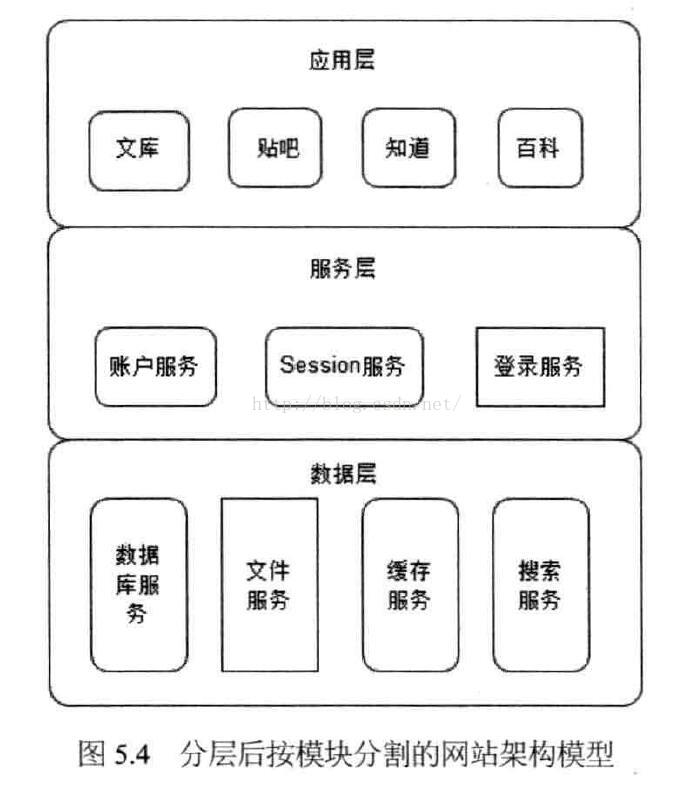
典型的网站架构如下图:
数据层好解释,我这里就说说应用层与服务层。
应用层是具体的业务逻辑
而服务层就是可以复用额服务。
举个简单的例子,百度的贴吧与文科分属不同的应用,但是他们都需要登陆操作,而登陆服务就是一个可以复用的服务。如下图:
应用层的服务器是通过负载均衡设备组合到一起的,如果某个服务器不可用,负载均衡服务设备会通过心跳检测设备知道,并且把失效的服务器地址从自己的集群列表中剔除。
服用层的服务会被应用层的业务通过分布式服务框架调用(如dubbo),多个服务会通过注册中心管理(如zookeeper),当某个服务器失效了,注册中心就会剔除不可用的地址。
数据层的服务器一般进行数据同步复制。一旦一台服务器出问题了,新的请求就会被转发到还正常的服务器上。
另外,网站除了因为硬件故障会导致服务不可用外,系统升级更新也会出现不可用的问题,所以,系统的升级更新我们也要考虑。
下面我们就从,应用,服务,数据三个层次来说说如何具体实现高可用
高可用的应用
这里的服务器得分两种1 有状态的服务器 2 没有状态的服务器对于没有状态的服务器来说,比较简单,直接最简单的负载均衡就OK
对于那些有状态的服务器,其实复杂的是session,第一次访问在服务器a,session也在服务器a上,第二次请求被分配到b上了,可b里面有吗session。
对于session的管理,也分几种
1 session复制,也就是说 n台服务器的集群中,每一台服务器都有所以的session信息。 如果服务器一多,用户量一多,这个方案就不合适了。
2 session绑定,让a用户只访问服务器a,用户b也只访问某一台服务器。 如果一旦服务器a宕掉了,用户a怎么办?
3 利用cookie,
4 使用session服务器。(大型网站架构最优)

高可用服务
服务本身是无状态的(如果服务被设计成有状态的,那你就去反省吧),那么使用简单的负载均衡就OK。除此之外,我们还有一些别的小建议
1 分级管理 让核心应用使用高性能的硬件 (用户付款就比之后的评价反馈要显得核心一些)
2 超时设置 如果n个单位时间内,没有响应,就重新发请求。
3 异步调用

5 幂等性设计 这不能说是一个建议,而应该是一个要求,就是保证某个服务调用一次与调用n次的效果是一致的。
因为应用端如果没有收到反馈就会再次调用服务端(此时可能已经调用成功了,只是应用端没有收到而已)
高可用数据
保证数据高可用一般有两种方式数据备份与失效转移
前者保证数据不丢失,后者保证随时能访问到正确的数据。
那么具体的说,什么是高可用数据呢?或者说,高可用体现在哪里呢?
1 数据持久性 -----技术发生存储故障,数据也是存在的。
2 数据可访问性 ----某个数据服务器发生了问题,能很快(用户几乎没有感知)切换用户的访问到新的数据服务器
3 数据一致性
我们一般认为,系统无法同时满足数据一致性(Consistency),数据可用性(Availibility),分区耐受性(Partition Tolerance,跨网络分区的伸缩性)
一般来说数据一致性也分下面几个情况
3.1 数据强一致性 各个副本的数据是一样的,这一点在数据更新时保证
3.2 数据用户一致性 各个副本的数据是一样的,但是用户获得数据时会校验,保证用户得到的数据是正确的
3.3 数据最终一致性 物理存储的数据是不一样的,用户获得的数据也是不同的(同一用户多次访问,多个用户同时访问),不过过一段时间(通常较短),物理信息会自动一致。
大型网站一般会选择强化可用性与分区耐受性,一定程度上放弃一致性。