入手 Hive 需要知道的一些概念
一、前言
Hive 是什么? 与 HBase有什么不同 ? 为什么安装Hive 需要 安装MySQL?
二、 需要 解决的问题如下
1. Hive 是什么?
Hive是一个基于Hadoop的数据仓库平台, Hive可以看成是从SQL到Map-Reduce的 映射器 。 它的框架图如下:
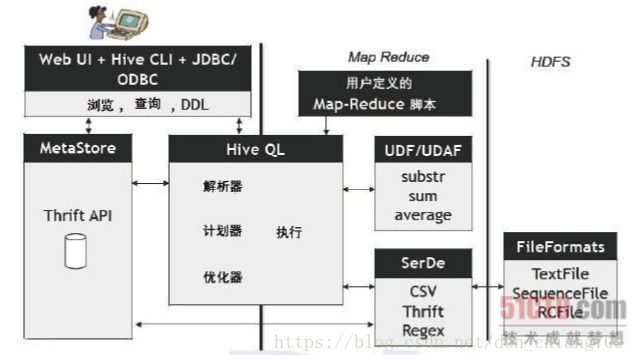
来张更清晰的图:
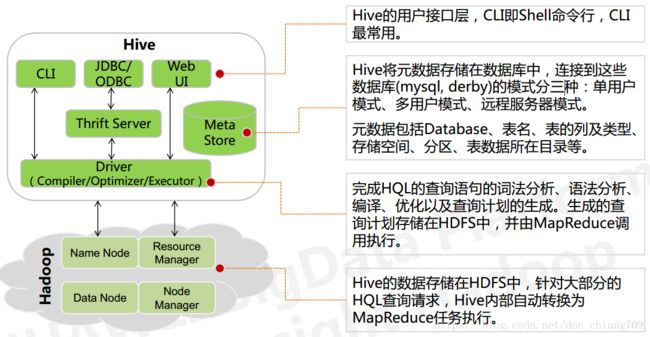
2. 与 HBase有什么不同
HBase是数据库(处理实时数据,实时性高,目前不支持SQL语句),而Hive 是数据仓库(处理离线数据)。
详细区别:https://blog.csdn.net/vipyeshuai/article/details/50847281
3. 为什么安装Hive 需要 安装MySQL?
默认情况下,Hive元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的测试。为了支持多用户多会话,则需要一个独立的元数据库,我们使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
那Hive的数据放在哪儿?
- 数据在HDFS的warehouse目录下,一个表对应一个子目录。
- 本地的/tmp目录存放日志和执行计划
- hive的元数据保存在MySQL 中(Derby )。
三、打通了以上概念后如同习武之人的任督二脉已通 。
四、深入思考
1. 怎么测试 Hive 性能? 有哪些BenchMark?
a) HiBench:
配置文件 aggregation.conf join.conf scan.conf
各个运行文件:
~/HiBench/bin/workloads/sql/aggregation/:
hadoop prepare spark
~/HiBench/bin/workloads/sql/join/:
hadoop prepare spark
~/HiBench/bin/workloads/sql/scan/:
hadoop prepare spark
~/HiBench/bin/workloads/sql/scan/prepare/prepare.sh
~/HiBench/bin/workloads/sql/scan/hadoop/run.sh
b) TPC
2. Spark 是否 对Hive 有改进?
SparkSQL的前身是Shark,给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,hive应运而生,它是当时唯一运行在Hadoop上的SQL-on-hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,降低的运行效率,为了提高SQL-on-Hadoop的效率,Shark应运而生,但又因为Shark对于Hive的太多依赖(如采用Hive的语法解析器、查询优化器等等),2014年spark团队停止对Shark的开发,将所有资源放SparkSQL项目上

其中SparkSQL作为Spark生态的一员继续发展,而不再受限于Hive,只是兼容Hive;而Hive on Spark是一个Hive的发展计划,该计划将Spark作为Hive的底层引擎之一,也就是说,Hive将不再受限于一个引擎,可以采用Map-Reduce、Tez、Spark等引擎。
hive on spark大体与SparkSQL结构类似,只是SQL引擎不同,但是计算引擎都是spark!敲黑板!这才是重点! hive on spark大体与SparkSQL结构类似,只是SQL引擎不同,但是计算引擎都是spark!
sparksql和hive on spark时间差不多,但都比hive on mapreduce快很多,官方数据认为spark会被传统mapreduce快10-100倍
参考:
http://www.itfly.pc-fly.com/article/p-hive%E6%95%B0%E6%8D%AE%E5%BA%93.html
https://blog.csdn.net/mrlevo520/article/details/76696073