ceph搭建过程中遇到的问题汇总
目录
1. [ceph_deploy][ERROR ] RuntimeError: Failed to execute command: env DEBIAN_FRONTEND=noninteractive DEBIAN_PRIORITY=critical apt-get --assume-yes -q update
2. [ceph_deploy][ERROR ] RuntimeError: Failed to execute command: yum -y install ceph ceph-radosgw
3. [node1][DEBUG ] 12: Timeout on http://mirrorlist.centos.org/?release=7&arch=x86_64&repo=extras&infra=stock: (28, 'Operation too slow. Less than 1000 bytes/sec transferred the last 30 seconds')
4. No package ceph available
5. no active mgr(luminous版本)
6. rbd map 映射失败(RBD image feature set mismatch,image uses unsupported features: 0x38)
7. ceph -s: auth: unable to find a keyring on /etc/ceph/ceph.client.admin.keyring
8. ceph health: HEALTH_WARN application not enabled on 1 pool(s)
9. 命令mount -t ceph xxx 或者 mount.ceph xxx挂载cephfs时,提示"mount error 22 = Invalid argument"。
10. [ceph] Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
1. [ceph_deploy][ERROR ] RuntimeError: Failed to execute command: env DEBIAN_FRONTEND=noninteractive DEBIAN_PRIORITY=critical apt-get --assume-yes -q update
[admin-node][DEBUG ] 404 Not Found [IP: 158.69.68.124 80]
[admin-node][DEBUG ] Hit:6 http://cn.archive.ubuntu.com/ubuntu bionic-backports InRelease
[admin-node][DEBUG ] Reading package lists...
[admin-node][WARNIN] E: The repository 'http://download.ceph.com/debian-{ceph-stable-release} bionic Release' does not have a Release file.
[admin-node][ERROR ] RuntimeError: command returned non-zero exit status: 100
[ceph_deploy][ERROR ] RuntimeError: Failed to execute command: env DEBIAN_FRONTEND=noninteractive DEBIAN_PRIORITY=critical apt-get --assume-yes -q update分析:这个[ERROR ]是因为[WARNIN] E: The repository 'http://download.ceph.com/debian-{ceph-stable-release} bionic Release' does not have a Release file.造成的。
解决方法:在admin-node上修改/etc/apt/sources.list.d/ceph.list内容如下:
deb http://download.ceph.com/debian-{ceph-stable-release}/ bionic main =>deb http://download.ceph.com/debian-luminous/ bionic main
2. [ceph_deploy][ERROR ] RuntimeError: Failed to execute command: yum -y install ceph ceph-radosgw
[node1][INFO ] installing Ceph on node1
[node1][INFO ] Running command: sudo yum clean all
[node1][DEBUG ] Loaded plugins: fastestmirror, langpacks
[node1][DEBUG ] Cleaning repos: base extras updates
[node1][DEBUG ] Cleaning up list of fastest mirrors
[node1][INFO ] Running command: sudo yum -y install ceph ceph-radosgw
[node1][DEBUG ] Loaded plugins: fastestmirror, langpacks
[node1][DEBUG ] Determining fastest mirrors
[node1][DEBUG ] * base: ftp.sjtu.edu.cn
[node1][DEBUG ] * extras: ftp.sjtu.edu.cn
[node1][DEBUG ] * updates: ftp.sjtu.edu.cn
[node1][DEBUG ] No package ceph available.
[node1][DEBUG ] No package ceph-radosgw available.
[node1][WARNIN] Error: Nothing to do
[node1][ERROR ] RuntimeError: command returned non-zero exit status: 1
[ceph_deploy][ERROR ] RuntimeError: Failed to execute command: yum -y install ceph ceph-radosgw解决方法:node1上安装libunwind,命令:sudo yum install libunwind
3. [node1][DEBUG ] 12: Timeout on http://mirrorlist.centos.org/?release=7&arch=x86_64&repo=extras&infra=stock: (28, 'Operation too slow. Less than 1000 bytes/sec transferred the last 30 seconds')
[node1][DEBUG ] Could not retrieve mirrorlist http://mirrorlist.centos.org/?release=7&arch=x86_64&repo=extras&infra=stock error was
[node1][WARNIN]
[node1][DEBUG ] 12: Timeout on http://mirrorlist.centos.org/?release=7&arch=x86_64&repo=extras&infra=stock: (28, 'Operation too slow. Less than 1000 bytes/sec transferred the last 30 seconds')
[node1][WARNIN]
[node1][WARNIN] One of the configured repositories failed (Unknown),
[node1][WARNIN] and yum doesn't have enough cached data to continue. At this point the only
[node1][WARNIN] safe thing yum can do is fail. There are a few ways to work "fix" this:
...
[node1][WARNIN] Cannot find a valid baseurl for repo: extras/7/x86_64
[node1][ERROR ] RuntimeError: command returned non-zero exit status: 1
[ceph_deploy][ERROR ] RuntimeError: Failed to execute command: yum -y install ceph ceph-radosgw
解决方法:修改虚拟机的/etc/resolv.conf文件,nameserver为物理机的gateway(查询命令:ip route show)
# Generated by NetworkManager
nameserver 192.168.122.1 => 10.38.50.1
route add default gw 10.38.50.1 dev eth0
4. No package ceph available
[node1][INFO ] installing Ceph on node1
[node1][INFO ] Running command: sudo yum clean all
[node1][DEBUG ] Loaded plugins: fastestmirror, langpacks
[node1][DEBUG ] Cleaning repos: base extras updates
[node1][DEBUG ] Cleaning up list of fastest mirrors
[node1][INFO ] Running command: sudo yum -y install ceph ceph-radosgw
[node1][DEBUG ] Loaded plugins: fastestmirror, langpacks
[node1][DEBUG ] Determining fastest mirrors
[node1][DEBUG ] * base: mirrors.163.com
[node1][DEBUG ] * extras: ftp.sjtu.edu.cn
[node1][DEBUG ] * updates: mirrors.aliyun.com
[node1][DEBUG ] No package ceph available.
[node1][DEBUG ] No package ceph-radosgw available.
[node1][WARNIN] Error: Nothing to do
[node1][ERROR ] RuntimeError: command returned non-zero exit status: 1
[ceph_deploy][ERROR ] RuntimeError: Failed to execute command: yum -y install ceph ceph-radosgw
解决方法:修改虚拟机node1的/etc/yum.repos.d/CentOS-Base.repo,运行下面命令:
CentOS 7:
sudo wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
或者
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
再执行,sudo yum clean all && sudo yum makecache
sudo yum update
如果还不行,直接安装yum list出来的包。查看可以安装的ceph包,yum list | grep ceph
$yum list | grep ceph
centos-release-ceph-jewel.noarch 1.0-1.el7.centos extras
centos-release-ceph-luminous.noarch 1.1-2.el7.centos extras
centos-release-ceph-nautilus.noarch 1.1-6.el7.centos extras
ceph-common.x86_64 1:10.2.5-4.el7 base
运行下列命令安装:sudo yum -y install centos-release-ceph-luminous
sudo yum -y install ceph-common
安装完后,再查看安装过的安装包
$ yum list installed| grep ceph
centos-release-ceph-luminous.noarch 1.1-2.el7.centos @extras
ceph-common.x86_64 2:12.2.11-0.el7 @centos-ceph-luminous
leveldb.x86_64 1.12.0-5.el7.1 @centos-ceph-luminous
libbabeltrace.x86_64 1.2.4-3.1.el7 @centos-ceph-luminous
libcephfs2.x86_64 2:12.2.11-0.el7 @centos-ceph-luminous
librados2.x86_64 2:12.2.11-0.el7 @centos-ceph-luminous
libradosstriper1.x86_64 2:12.2.11-0.el7 @centos-ceph-luminous
librbd1.x86_64 2:12.2.11-0.el7 @centos-ceph-luminous
librgw2.x86_64 2:12.2.11-0.el7 @centos-ceph-luminous
lttng-ust.x86_64 2.10.0-1.el7 @centos-ceph-luminous
python-cephfs.x86_64 2:12.2.11-0.el7 @centos-ceph-luminous
python-rados.x86_64 2:12.2.11-0.el7 @centos-ceph-luminous
python-rbd.x86_64 2:12.2.11-0.el7 @centos-ceph-luminous
python-rgw.x86_64 2:12.2.11-0.el7 @centos-ceph-luminous
userspace-rcu.x86_64 0.10.0-3.el7 @centos-ceph-luminous
5. no active mgr(luminous版本)
$ ceph health
HEALTH_WARN no active mgr
yjiang2@admin-node:~/ceph-cluster$ ceph -s
cluster:
id: 027d5b3c-e011-4a92-9449-c8755cd8f500
health: HEALTH_WARN
no active mgr
services:
mon: 1 daemons, quorum node1
mgr: no daemons active
osd: 2 osds: 2 up, 2 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0B
usage: 0B used, 0B / 0B avail
pgs:
解决方法:进入ceph-cluster目录,运行ceph-deploy mgr create node1。node1为部署ceph-mgr节点的hostname.
~/ceph-cluster$ ceph-deploy mgr create node1
[ceph_deploy.conf][DEBUG ] found configuration file at: /home/yjiang2/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (1.5.38): /usr/bin/ceph-deploy mgr create node1
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] mgr : [('node1', 'node1')]
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : create
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf :
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] func :
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.mgr][DEBUG ] Deploying mgr, cluster ceph hosts node1:node1
[node1][DEBUG ] connection detected need for sudo
[node1][DEBUG ] connected to host: node1
[node1][DEBUG ] detect platform information from remote host
[node1][DEBUG ] detect machine type
[ceph_deploy.mgr][INFO ] Distro info: CentOS Linux 7.6.1810 Core
[ceph_deploy.mgr][DEBUG ] remote host will use systemd
[ceph_deploy.mgr][DEBUG ] deploying mgr bootstrap to node1
[node1][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[node1][WARNIN] mgr keyring does not exist yet, creating one
[node1][DEBUG ] create a keyring file
[node1][DEBUG ] create path if it doesn't exist
[node1][INFO ] Running command: sudo ceph --cluster ceph --name client.bootstrap-mgr --keyring /var/lib/ceph/bootstrap-mgr/ceph.keyring auth get-or-create mgr.node1 mon allow profile mgr osd allow * mds allow * -o /var/lib/ceph/mgr/ceph-node1/keyring
[node1][INFO ] Running command: sudo systemctl enable ceph-mgr@node1
[node1][WARNIN] Created symlink from /etc/systemd/system/ceph-mgr.target.wants/[email protected] to /usr/lib/systemd/system/[email protected].
[node1][INFO ] Running command: sudo systemctl start ceph-mgr@node1
[node1][INFO ] Running command: sudo systemctl enable ceph.target
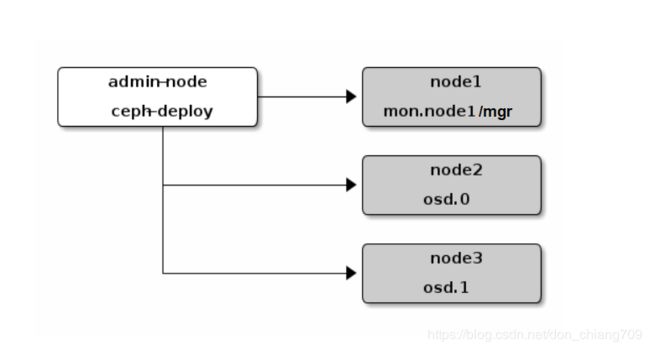
部署的拓扑结构:
6. rbd map 映射失败(RBD image feature set mismatch,image uses unsupported features: 0x38)
yjiang2@admin-node:/etc/ceph$ sudo rbd map image1
rbd: sysfs write failed
RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable image1 object-map fast-diff deep-flatten".
In some cases useful info is found in syslog - try "dmesg | tail".
rbd: map failed: (6) No such device or address
yjiang2@admin-node:/etc/ceph$ dmesg | tail
[373619.793727] perf: interrupt took too long (6299 > 6258), lowering kernel.perf_event_max_sample_rate to 31750
[685452.247262] Key type ceph registered
[685452.247374] libceph: loaded (mon/osd proto 15/24)
[685452.249635] rbd: loaded (major 252)
[686654.432589] libceph: mon0 192.168.122.157:6789 session established
[686654.432959] libceph: client4156 fsid 027d5b3c-e011-4a92-9449-c8755cd8f500
[686654.438274] rbd: image image1: image uses unsupported features: 0x38
[686674.996309] libceph: mon0 192.168.122.157:6789 session established
[686674.996536] libceph: client4158 fsid 027d5b3c-e011-4a92-9449-c8755cd8f500
[686675.002651] rbd: image image1: image uses unsupported features: 0x38
解决方法1:
查看image的features,可以看到image1拥有: layering, exclusive-lock, object-map, fast-diff, deep-flatten。不过遗憾的是使用的内核仅支持其中的layering feature,其他feature概不支持。我们需要手动disable这些
yjiang2@admin-node:/etc/ceph$ rbd info image1
rbd image 'image1':
size 1GiB in 256 objects
order 22 (4MiB objects)
block_name_prefix: rbd_data.10356b8b4567
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
flags:
create_timestamp: Wed Jun 19 16:05:40 2019
disable掉kernel不支持的feature
yjiang2@admin-node:/etc/ceph$ rbd feature disable image1 exclusive-lock, object-map, fast-diff, deep-flatten
yjiang2@admin-node:/etc/ceph$ rbd info image1
rbd image 'image1':
size 1GiB in 256 objects
order 22 (4MiB objects)
block_name_prefix: rbd_data.10356b8b4567
format: 2
features: layering
flags:
create_timestamp: Wed Jun 19 16:05:40 2019
yjiang2@admin-node:/etc/ceph$ sudo rbd map image1
/dev/rbd0
当然,在单个创建rbd的时候我们也可以通过修改format的版本来实现挂载,这里把format指定为1之后其实上面的rbd的很多功能都已经去掉了:
rbd create foo --size 10G --image-format 1 --image-feature layering
解决方法2:
每次这么来disable可是十分麻烦的,一劳永逸的方法是在各个cluster node的/etc/ceph/ceph.conf中加上这样一行配置:
rbd_default_features = 1 #仅是layering对应的bit码所对应的整数值设置完后,通过下面命令查看配置变化:
# ceph --show-config|grep rbd|grep featuresrbd_default_features = 17. ceph -s: auth: unable to find a keyring on /etc/ceph/ceph.client.admin.keyring
[yjiang2@node3 ~]$ ceph -s
2019-06-20 21:58:34.063820 7f9c93e30700 -1 auth: unable to find a keyring on /etc/ceph/ceph.client.admin.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,: (2) No such file or directory
2019-06-20 21:58:34.063824 7f9c93e30700 -1 monclient: ERROR: missing keyring, cannot use cephx for authentication
2019-06-20 21:58:34.063825 7f9c93e30700 0 librados: client.admin initialization error (2) No such file or directory
[errno 2] error connecting to the cluster
解决方法: 把管理节点admin-node生成的五个keyring文件copy到所有ceph节点node1/2/3的/etc/ceph/目录下,不然连接集群时,会出现失败。
admin-node生成的五个keyring文件,如下:
yjiang2@admin-node:~/ceph-cluster$ ll
total 232
drwxrwxr-x 2 yjiang2 yjiang2 4096 Jun 20 16:18 ./
drwxr-xr-x 38 yjiang2 yjiang2 4096 Jun 20 16:18 ../
-rw------- 1 yjiang2 yjiang2 71 Jun 13 09:07 ceph.bootstrap-mds.keyring
-rw------- 1 yjiang2 yjiang2 71 Jun 13 09:07 ceph.bootstrap-mgr.keyring
-rw------- 1 yjiang2 yjiang2 71 Jun 13 09:07 ceph.bootstrap-osd.keyring
-rw------- 1 yjiang2 yjiang2 71 Jun 13 09:07 ceph.bootstrap-rgw.keyring
-rw------- 1 yjiang2 yjiang2 63 Jun 13 09:07 ceph.client.admin.keyring
-rw-rw-r-- 1 yjiang2 yjiang2 281 Jun 20 16:18 ceph.conf
-rw-rw-r-- 1 yjiang2 yjiang2 194032 Jun 21 10:02 ceph-deploy-ceph.log
-rw------- 1 yjiang2 yjiang2 73 Jun 12 11:18 ceph.mon.keyring
copy命令如下:
yjiang2@admin-node:~/ceph-cluster$ scp *.keyring yjiang2@node1:/etc/ceph/
yjiang2@admin-node:~/ceph-cluster$ scp *.keyring yjiang2@node2:/etc/ceph/
yjiang2@admin-node:~/ceph-cluster$ scp *.keyring yjiang2@node3:/etc/ceph/
最后,确保admin-node节点的ceph.client.admin.keyring有读权限:
yjiang2@admin-node:~/ceph-cluster$ sudo chmod +r /etc/ceph/ceph.client.admin.keyring
8. ceph health: HEALTH_WARN application not enabled on 1 pool(s)
~$ ceph health detail
HEALTH_WARN application not enabled on 1 pool(s)
POOL_APP_NOT_ENABLED application not enabled on 1 pool(s)
application not enabled on pool 'rbd'
use 'ceph osd pool application enable ', where is 'cephfs', 'rbd', 'rgw', or freeform for custom applications.
解决方法:
ceph osd pool application enable rbd rbd
enabled application 'rbd' on pool 'rbd'
yjiang2@admin-node:~$ ceph health
HEALTH_OK
9. 命令mount -t ceph xxx 或者 mount.ceph xxx挂载cephfs时,提示"mount error 22 = Invalid argument"。
$ sudo mount -t ceph node1:6789:/ ~/client_cephfs_mnt/
mount error 22 = Invalid argument
问题分析:我的OS是Ubuntu 7.4.0,查看文件 /var/log/kern.log(如果是centos系统,查看/var/log/messages log 文件)的error log,显示如下:
Jul 16 11:59:55 admin-node kernel: [587627.598176] libceph: no secret set (for auth_x protocol)
Jul 16 11:59:55 admin-node kernel: [587627.598180] libceph: error -22 on auth protocol 2 init
分析是认证问题导致,挂载是指定secret file.
解决方法:
- 查看密钥,可知用户名admin的密钥如下:
$ sudo cat ./ceph.client.admin.keyring
[client.admin]
key = AQDYoQFd0Xr+CRAAIwRmwD7yWim2Nzq44wRwqw==
- 方法 一,直接指定密钥挂载
sudo mount.ceph node1:6789:/ ~/client_cephfs_mnt/ -o name=admin,secret=AQDYoQFd0Xr+CRAAIwRmwD7yWim2Nzq44wRwqw==- 方法 二,存储密钥到文件,指定密钥文件
$ vim ~/admin.keyring
AQDYoQFd0Xr+CRAAIwRmwD7yWim2Nzq44wRwqw==
挂载:
sudo mount.ceph node1:6789:/ ~/client_cephfs_mnt/ -o name=admin,secretfile=~/admin.keyring
10. [ceph] Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
$ceph osd pool delete rbd rbd --yes-i-really-really-mean-it
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
解决方法:
更新 monitor 节点的ceph.conf文件,
[mon]
mon allow pool delete = true
$ cat ceph.conf
[global]
fsid = 832e67c7-e0c8-45b1-b841-2f5df0d0dbe6
mon_initial_members = ubuntu-sebre
mon_host = 10.110.141.30
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
pool default size = 1
[mon]
mon allow pool delete = true重启后再执行删除命令
$ sudo cp ceph.conf /etc/ceph/ceph.conf
$ sudo systemctl restart ceph-mon.target
$ ceph osd pool delete rbd rbd --yes-i-really-really-mean-it
pool 'rbd' removed
11. [ceph] pgs inactive/pgs undersized:
$ ceph -s
cluster:
id: 832e67c7-e0c8-45b1-b841-2f5df0d0dbe6
health: HEALTH_WARN
Reduced data availability: 100 pgs inactive
Degraded data redundancy: 100 pgs undersized
services:
mon: 1 daemons, quorum ubuntu-sebre
mgr: ubuntu-sebre(active)
osd: 1 osds: 1 up, 1 in
data:
pools: 1 pools, 100 pgs
objects: 0 objects, 0B
usage: 1.17GiB used, 8.83GiB / 10GiB avail
pgs: 100.000% pgs not active
100 undersized+peered
分析:参考pg状态表,可知undersize是因为真实副本数少于配置的最少副本数,查看是否有osd挂掉了。如果是设置的问题,直接修改副本数和最少副本数。
解决方法:
sudo ceph osd pool set [poolname] size 1
sudo ceph osd pool set [poolname] min_size 1
//查看指定的pool副本数
sudo ceph osd pool get [poolname] min_size
sudo ceph osd pool get [poolname] size12. OS磁盘已满,启动不了ceph-mon
sudo /usr/bin/ceph-mon -f --cluster ceph --id ubuntu-sebre --setuser ceph --setgroup ceph
2019-07-24 14:06:55.682166 ffff85086010 -1 error: monitor data filesystem reached concerning levels of available storage space (available: 0% 1.00GiB)
you may adjust 'mon data avail crit' to a lower value to make this go away (default: 5%)解决方法:不用说了。