用tensorflow实现一个卷积神经网络
学了一段深度学习,最近学了tensorflow,所以想自己去根据教程写一个简单的卷积神经网络。
CNN:卷积神经网络的实现
一个卷积神经网络的结构一般是由输入-->卷积-->池化-->卷积-->池化-->............-->全连接-->全连接-->输出,这样的一层层构建起来的网络。本代码构建了一个含有两个卷积层,两个池化层和两个全连接层的网络,在mnist手写数字分类任务上精度达到0.99
神经网络上一层的输出是下一层的输入,所有数据的shape必须要匹配上,否则到到计算数据时会报错。所有代码接受均在代码段注释中。
环境:windows10, 64位操作系统, python3.5, tensorflow1.11版本
'''实现mnist手写数字的分类'''
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets('MNIST_DATA',one_hot=True)#如果没有mnist数据就进行下载;使用one_hot编码
#定义权重初始化,偏置初始化
def weight_variable(shape):
#生成正态分布数据的一种形式。shape表示生成数据的维度,stddev为标准差
inital=tf.truncated_normal(shape,stddev=0.1)
return tf.Variable(inital)
def bias_variable(shape):
inital = tf.constant(0.1,shape=shape)
return tf.Variable(inital)
#定义卷积操作
def conv2d(x,W):
#strides[1,x_movement,y_movement,1],第一个和最后一个1是规定好的必须等于1
#strides=[1,1,1,1]中间两个1表示卷积在x,y两个方向的步长为1
#padding='SAME'表示输出尺寸与输入相同,有两个可选的值,另一个是VAILD,根据卷积核的大小相应产生变化
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')
#定义池化操作
def max_pool_2x2(x):
#strides[1,x_movement,y_movement,1],第一个和最后一个1是规定好的必须等于1
#ksize意为kernel size表示卷积核尺寸大小,strides=[1,2,2,1],与上面卷积层相似,只不过步长为2
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
#用placeholder先把网络输入数据先存起来
xs=tf.placeholder(tf.float32,[None,784]) #手写数字识别的图片尺寸为28*28=784
ys=tf.placeholder(tf.float32,[None,10]) #输出的类别为10类
keep_prob=tf.placeholder(tf.float32) #keep_prob适合dropout联合使用的,我发现将全文中的keep_prob去掉后,仅仅在下面的dropout处理的地方填上一个值,网络依然可以运行,结果还不错。
x_image=tf.reshape(xs,[-1,28,28,1]) #将传入的信息换成图片的信息,传入xs,将形状变为28*28*1, -1为所有传入的图片
#print(x_image.shape)#你可以运行这步,查看x_image的数据的shape
####conv1 layer构建第一层卷积层,后面紧跟一层池化操作
W_conv1=weight_variable([5,5,1,32]) #5,5为卷积核大小,1为输入的深度,32为输出深度
b_conv1=bias_variable([32])
h_conv1=tf.nn.relu(conv2d(x_image,W_conv1)+b_conv1)#此步骤输出的图片大小为28*28*32
h_pool1=max_pool_2x2(h_conv1) #池化后输出的大小为14*14*32
####conv2 layer构建第二层卷积层,后面再跟一层池化操作
W_conv2=weight_variable([5,5,32,64]) #5,5为卷积核大小,32为输入的深度,64为输出深度
b_conv2=bias_variable([64])
h_conv2=tf.nn.relu(conv2d(h_pool1,W_conv2)+b_conv2)#此步骤输出的图片大小为14*14*64
h_pool2=max_pool_2x2(h_conv2) #池化后输出的大小为7*7*64
####func1 layer构建一层全连接层
W_fc1=weight_variable([7*7*64,1024])
b_fc1=bias_variable([1024])
#[n_samples,7,7,64]---->[n_samples,7*7*64]相当于把后面的三个维度,拍平成一个一维向量。
h_pool2_flat=tf.reshape(h_pool2,[-1,7*7*64])
#全连接层:用relu激活函数,激活后面的Wx+b
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1)
h_fc1_drop=tf.nn.dropout(h_fc1,keep_prob) #即在这里将keep_prob替换为0-1之间的数,网络一样可以运行
####func2 layer构建第二层全连接层
W_fc2=weight_variable([1024,10])
b_fc2=bias_variable([10])
prediction=tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2)+b_fc2)
#使用了一个交叉熵损失函数
cross_entropy=tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1]))
#训练优化器选择的自适应的优化器,学习率为0.0001,
train_step=tf.train.AdamOptimizer(0.0001).minimize(cross_entropy)
#定义计算精度的函数
def compute_accuracy(v_xs,v_ys):
global prediction
#keep_prob是每个元素被保留的概率,keep_prob:1就是所有元素全部保留
y_pre = sess.run(prediction,feed_dict={xs:v_xs,keep_prob:1})
#函数tf.equal(x,y,name=None)对比x与y矩阵/向量中相等的元素,相等的返回True,不相等返回False,返回的矩阵/向量的维度与x相同;tf.argmax()返回最大值对应的下标(1表示每一列中的,0表示每一行),在此就是说y的预测和真实标签是否一致
correct_prediction = tf.equal(tf.argmax(y_pre,1),tf.argmax(v_ys,1))
#tf.cast()类型转换函数,将correct_prediction转换成float32类型,并对correct_prediction求平均值得到arruracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
result = sess.run(accuracy,feed_dict={xs:v_xs,ys:v_ys,keep_prob:1})
return result
with tf.Session() as sess:
#对所有定义变量进行初始化
sess.run(tf.initialize_all_variables())
#开始迭代训练数据
for i in range(10000):
#用两个变量接受数据集的返回值,batch_xs接受图片,batch_ys接收标签,每次接受100个数据
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys,keep_prob:1})
#每50次打印一次精度
if i % 50 == 0:
print(i,"accuracy:",compute_accuracy(mnist.test.images, mnist.test.labels)) 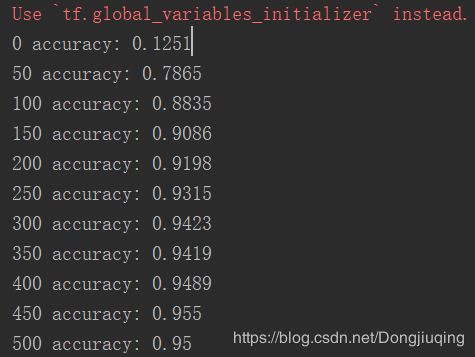

可以看出在前500次迭代的时候,精度大幅度的提升,在10000次左右达到饱和。
下一篇想写一个Alexnet网络。
参考tensorflow教学视频:https://www.bilibili.com/video/av16001891/?p=28