本次大作业,我们小组完成基本任务,扩展任务以及高级任务。下面是每个任务的说明。
一、基本任务
1、首先给出GitHub地址:https://github.com/DM-Star/WordCount-opt
2、PSP表格
| PSP2.1 |
PSP阶段 |
预估耗时 (分钟) |
实际耗时 (分钟) |
| Planning |
计划 |
10 | 15 |
| · Estimate |
· 估计这个任务需要多少时间 |
10 | 15 |
| Development |
开发 |
700 | 800 |
| · Analysis |
· 需求分析 (包括学习新技术) |
80 | 90 |
| · Design Spec |
· 生成设计文档 |
30 | 50 |
| · Design Review |
· 设计复审 (和同事审核设计文档) |
60 | 80 |
| · Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
20 | 30 |
| · Design |
· 具体设计 |
50 | 50 |
| · Coding |
· 具体编码 |
300 | 400 |
| · Code Review |
· 代码复审 |
40 | 50 |
| · Test |
· 测试(自我测试,修改代码,提交修改) |
30 | 50 |
| Reporting |
报告 |
100 | 80 |
| · Test Report |
· 测试报告 |
50 | 40 |
| · Size Measurement |
· 计算工作量 |
30 | 20 |
| · Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 | 30 |
3、主要代码与接口说明
在此次大作业中,我们组将整个任务分成4个模块,分别是核心模块、统计模块、状态模块和输入模块,和老师要求中说的有一点不同,但我们一起讨论觉得我们这个项目分成这样四个模块更加合理,我负责的是核心模块,核心模块主要是主函数和输出函数这两个部分(在这里也先提一下,就是这两个刚好用单元测试框架就很难实现,研究百度好久也不清楚怎么测main函数和代码中的output函数,于是没办法和其他模块一样用单元测试框架),下面给出部分代码和接口的解释。
①main函数主要代码
int main(int argc, char **argv) { fstream in; if (!inputCheck(argv[1], in)) { in.close(); return 0; } WordList wordList; wordCount(in, wordList); outPut("result.txt", wordList); in.close(); system("pause"); return 0; }
这个主函数里主要就是包含了大家写的不同模块与接口,inputCheck是检查输入函数,WordList是为了记录单词及其词频的一个类,outPut就是输出函数,还有wordCount函数是对文件里面的单词进行词频统计和排序。首先用fstream in定义了一个文件对象(它封装了各种操作文件的方法),在接下来的函数中作为参数传入,在对文件输入判断检测后,对单词进行遍历统计,最后输出结果在result.txt文件上。
②outPut函数部分代码
void outPut(char outFile[], WordList &wordList) { ofstream outf(outFile); streambuf *default_buf = cout.rdbuf(); cout.rdbuf(outf.rdbuf()); wordList.outPut(); cout.rdbuf(default_buf); }
这是主运行函数中的输出代码,前三行输出重定向到文件,最后一行输出重定向到屏幕,中间一行负责用cout输出。
void WordList::outPut() { // 100 words are all output via cout Word *p = pWordHead->next; if (p != pWordTail) cout << p->word << ' ' << p->num; else return; p = p->next; for (int i = 0; i < 99; i++) { if (p != pWordTail) cout << endl << p->word << ' ' << p->num; else return; p = p->next; } }
这里是wordlist类中的一个输出函数,用于输出文件中的具体内容,根据其他组员设计的链表,这里的每个节点p是一个结构体,里面定义的char word和int num,我这里用p->word和p->num表示。这段代码首先,定义一个指针指向从表头之后的第一个节点(这才是正文的内容开始),判断是否是表的尾部,如果不是,就输出内容,即单词和单词数;然后p指向下一个节点,所有的输出用一个for循环,根据老师要求,输出词频前100位的单词。
4、测试用例设计
在前面也提到了,在我提出main函数该怎么测试这个问题后,我们大家都思考的情况下,都觉得不知道怎么用框架去测试,后来组长也上去问了老师,老师的回答也是跟我们一致的。后来我想,主函数和输出函数要测试的话,其实就是测试整个作业的输入输出了,于是我就设计了20个测试用例,相当于测试了我们这整个作业的功能是否完全完成,是否在遇到什么特殊情况是都能正确输出结果,以及这个项目的性能。
我设计测试用例的思想及整个过程如下:
首先对整个项目进行一个总体的测试,判断是否能正常输出想要的结果,如下图,与预期相同
然后老师任务要求中写只对txt文件进行分析,那对于其他格式的文件肯定是没办法解析的,所以这里我选择的几种比较典型的文件格式试运行,例如.cpp文件、.h文件、word文件等,结果与预期一样,如图

![]()

然后就是测试的重点,功能测试,测试我们的代码是否能完全正确的运行想要的结果,在这,我设计的十几个测试用例,分别检测了特殊情况,如老师例子中给出的
有关单词识别的部分典型情况的说明:
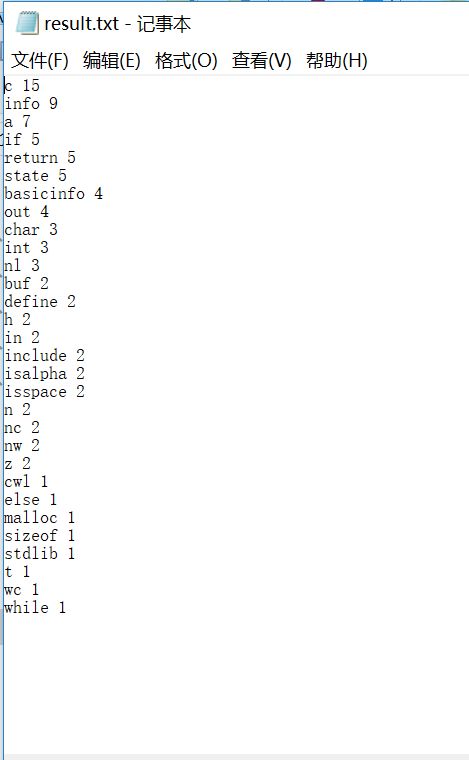
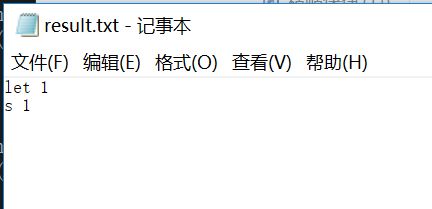
第一,Let’s,这种包含单引号的情况,视为2个单词,即let和s。
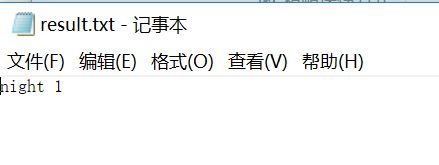
第二,night-,带短横线的单词,视为1个单词,即night。
第三,“I,带双引号的单词,视为1个单词,即i。
第四,TABLE1-2,带数字的单词,视为1个单词,即table。
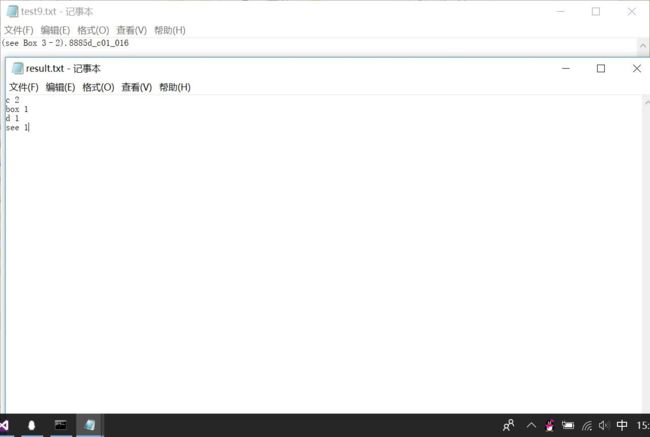
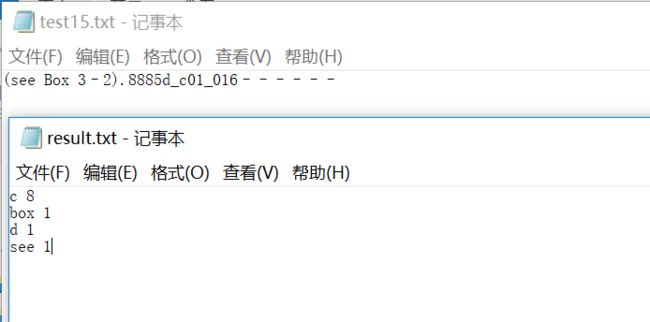
第五,(see Box 3–2).8885d_c01_016,带数字、常用字符和单词的情况,视为4个单词,即see, box, d, c。
前四种情况运行的蛮顺利,截图


在最后一种情况时,发现的一处问题,运行结果跟预期不同,如下图,c单词明明只出现了一次,词频确实2。后来发现应该这个测试用例中“3–2”中的扩展字符,它都会读成单词c。
这个问题引发我又有了一个新的测试用例,即更明确验证一下是不是那个“–”引起的问题,于是我在上面的测试用例后面又加了好几个“–”,结果表明猜想是正确的,
然后我将以上测试放在同一个文件里,每种数量也翻倍,来进行综合测试,输出结果与预期相同。

然后还进行了对空文件的测试,如果文件为空,看会输出什么结果,运行如图

最后的测试就进行了一个简单的性能测试,特意制造了一个1M以上的大文件进行测试,通过对比原文件与不停复制粘贴后的大文件输出结果,发现结果无误,即也通过了小小的性能的测试。(具体的压力测试还在高级任务中)
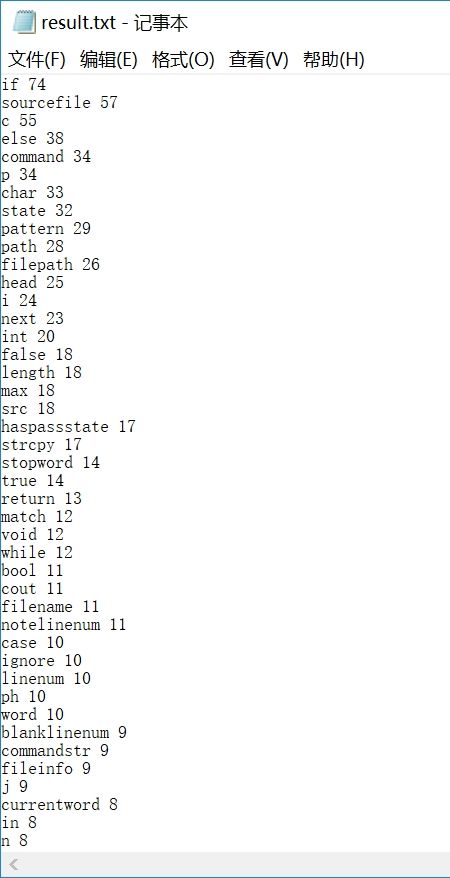
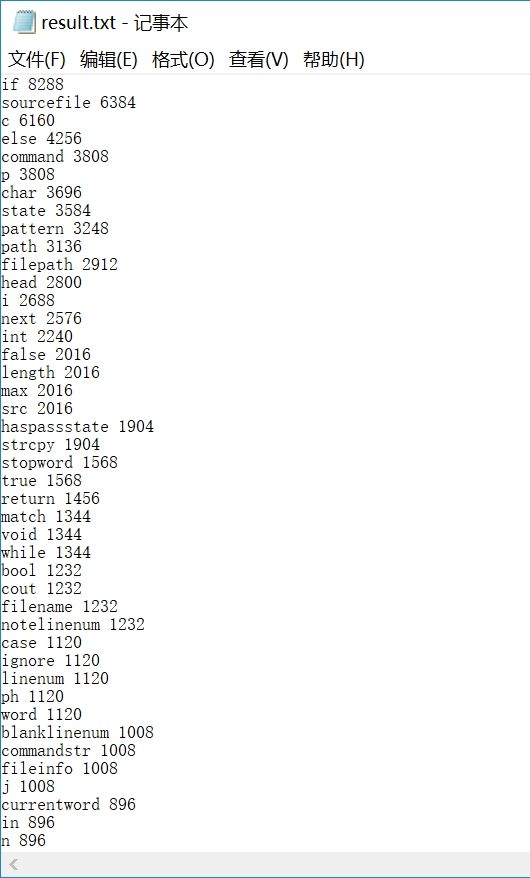
综上,除了上面“–”引起的问题,其他所有测试用例输出都与预期相同,即完成了测试任务。
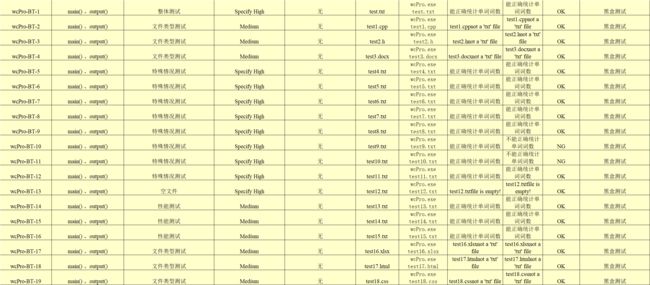
测试用例清单表如下图:
二、扩展任务
使用静态测试是为了确保代码符合行业规范。在这个项目中,我们参考了Google给出的C++风格指南,并且对所有的代码进行了检查。Google给出的代码规范涉及的范围十分全面,从头文件、命名空间,一直到if……else……语句,到注释、空格、花括号,都给出了详尽的规范。我们本来想使用Google提供的所有规范,但后来失败了。一方面,有些规范我们不是很能理解,例如Google对于命名空间提出的规范,我们并不能完全地理解;另一方面,规范中的某些内容我们并不认可,比如对于变量的命名,Google推荐使用下划线分隔变量中的每个单词,而我们认为变量命名使用变量首字母小写、单词首字母大写,中间不使用空格分隔的方式也很好(而且这是面向对象程序设计老师推荐的命名方式)。
综上,最后我们仅使用了头文件、注释、格式上的规范对整个项目进行代码检查。
进行代码检查,我们使用的是一款也是由Google提供的代码检查工具cpplint(下载地址为https://github.com/google/styleguide/tree/gh-pages/cpplint)。这款工具十分方便,对于一款配置好Python环境的电脑来说,只要将被测文件和脚本文件cpplint.py放在同一目录下,然后使用控制台运行Python脚本(被测文件路径作为参数),就能够快速地进行测试。
下面进行的第一次测试:
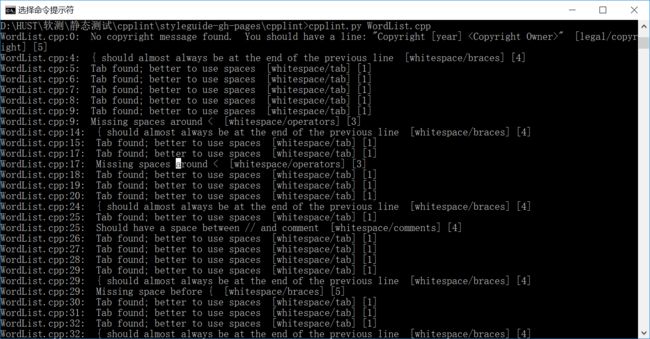
可以看出我们的代码主要存在的问题就是格式,以及一点点头文件的问题。Google规定代码中所有用Tab制表符的地方都得使用空格,每个花括号之前都要有一个空格,以及对于if……else……语句来说,只要一个分支使用了花括号,那么所有的分支都要使用花括号,而且else分支必须和前后两个花括号处在同一行。对于注释,注释内容和双斜杠之间必须要留有一个空格(我也不知道为什么)。
// 符合Google 规范的代码
if ((c >= 'a') && (c <= 'z')) { state = INNERWORD; } else if (c == '-') { if (state == INNERWORD) state = CRITICAL; else state = OUTERWORD; } else { state = OUTERWORD; }对于头文件而言,每个头文件都必须给出版权声明,还要进行#define保护。
// Copyright[2018]
#ifndef WCPRO_WORDLIST_H_ #define WCPRO_WORDLIST_H_ // 在这里添加代码... #endif // WCPRO_WORDLIST_H_ 不得不说,Google给出的规范真的是面面俱到。然而真的要实现它的所有规范我也不是很愿意。就拿#define保护来说吧,这三行代码,在VS编译器下,只需要用 #pragma once 这一条指令就可以实现。对于if……else……分支的种种规范,我觉得都很多余。我个人本身也有一套自己的格式规范,我的if语句看起来本来也相当顺眼,非常整齐,改成Google规范后反而看着不舒服了。就我们所采用的那部分Google规范而言,我们实际上都是差不多的。原因就是,在VS编辑器中,调整代码格式可以很方便地使用一组组合键来完成(Ctrl+K 和 Ctrl+F),使用这个组合键,可以快速地将我们的代码调整至VS的代码规范。对于没有采用Google规范的那部分(即,变量命名),我自认为胜他一筹,我对于变量命名,都会确实使用变量的含义命名,如pIndex, wordState等等,不会使用形如c, p, q 这样的简单的单字母来命名。
静态测试上面这部分的内容引自我们组长的博客,因为这个静态检查是从我开始做的,而开始检查的时候,他也一起正旁边看,然后一起讨论一起改正,所以我们想法一致,尤其是那个if……else……分支的种种规范,我们改了很久,才改成了符合要求的规范。
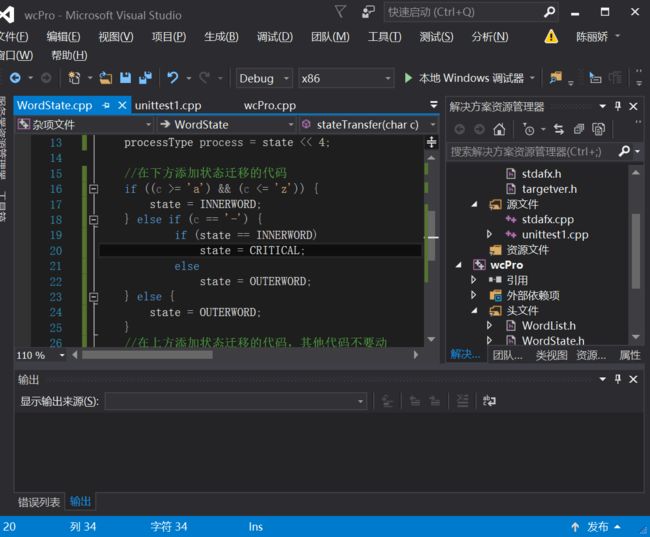

因为开始检查的时候就是随便选了一个文件检查,截图的代码不是自己写的那部分,后面就没有截图,因为问题和改正方法都相似。
三、高级任务
本次作业在我的mian函数和输出函数中性能优化中体现不大,但是在别的组员如输入模块上,对文件读取方面性能优化就比较需要,在读一个很大的文件时需要耗费的时间上就有体现。
四、总结
本次大作业,相比个人作业,感觉学习到的东西更多了,因为这次作业涉及到的知识面也多,学到了框架测试,静态测试,还有各种规范等等。第一次接触静态测试工具,跑出来结果的时候感觉都惊呆了,竟然几乎每行代码都是不符合规范的,于是一行一行的改,感觉这个工具也是蛮神奇的。还有,一个团队作业时,不同的同学都有不同的想法,互相交流讨论,感悟也很多。最后,要谢谢组长,带领我们学习,圆满完成这次大作业!