使用multinet的KittiBox部分进行车辆检测(demo,train,evalute)
使用KittiBox进行车辆检测,训练环境和配置:Ubuntu16.04,python3.5,TensorFlow1.4,i76700K+双GTX Titan X。由于不能直接用作者的源码直接跑,修改了一点点地方,整个过程挺艰辛的(新手刚上路),希望能给大家一点经验。
最近一直在看目标检测的论文和代码,这是一篇用于自动驾驶的论文,在kitti数据集上检测效果特别好,论文称超过了faster-rcnn,在速度和精度上都超越了。能实时检测。Multinet,顾名思义就是指多个网络,这里是指该网络能同时进行三项任务,分类,检测和语义分割。
网络结构如下:
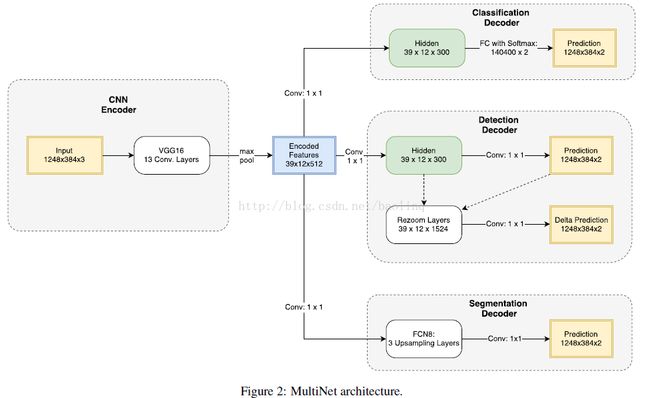
网络共用一个编码器,三个任务分别使用三个解码器。上图编码器部分使用VGG16为例进行编码部分的特征提取,也可以改为其他的网络结构,比如googlenet,resnet50,resnet101之类的替换。
主要看看检测解码器
检测解码器FastBox, 被设计为基于回归的检测系统。我们选择一种基于候选区域的解码器, 因为它可以进行端对端的训练, 并且可以非常有效地完成训练和推理。方法灵感来自ReInspect[39], Yolo [38]和Overfeat [44]。除了标准回归流程之外, 我们还包含一个ROI池化方法, 它允许网络利用更高分辨率的特征, 类似较慢的Faster-RCNN。
该解码器的第一步是产生bounding box的粗略估计。为了实现这一目标, 首先用500个滤波器的1×1卷积层传递编码的特征, 产生一个39×12×500大小的张量, 我们称之为隐藏层。随后该张量用另一个1×1卷积层处理, 输出6个分辨率为39×12的通道。我们称这个张量为prediction, 张量的值具有语义含义。该张量的前两个通道形成图像的粗分割。这些值表示感兴趣目标存在于39×12网格中的特定位置处的置信度。最后四个通道表示该单元周围区域中边界框的坐标。图3表示有cell的图像。
然而, 这种预测不是非常准确。在本文中, 我们认为这是由于编码器输出时的分辨率已经丢失。为了减轻这个问题, 我们引入了一个rezoom层, 它通过利用高分辨率特征来预测边界框位置上的残差。它通过将更高分辨率的VGG特征的子集(156×48)与隐藏特征(39×12)连接并在其上应用1×1卷积来完成。为了使其成为可能, 需要从高分辨率VGG特征产生39×12网格, 这些网格是通过应用ROI池化[40]使用由tensorprediction提供的粗预测来实现的。最后, 它与39×12×6特征连接, 并通过1×1卷积层以产生残差。

图3:可视化我们的标签编码。蓝色网格:单元(cells)。红细胞:含有汽车的细胞。灰色细胞:无关区域的细胞。绿色框:真实值
损失函数

训练过程
整个训练过程在作者的GitHub上面讲的蛮多的,很详细,但是吧有些代码是python2 的,如果你对环境是python3,直接按照步骤不能真确运行。需要对好几个文件做一些小小的修改,下面是我的一些训练记录和笔记。
首先是修改了哪些地方,具体文件和具体内容:
代码修改日志,改了5个地方
1.incl/utils/data_utils.py", line 71,in get_cell_grid
for iy in xrange(cell_height):
xrange改为range
2. "/incl/utils/data_utils.py",line 129, in annotation_jitter
if random.random > 0.8:
TypeError: unorderable types:builtin_function_or_method() > float()
random.random 改为random.random()
3.inputs/kitti_input.py", line 160
generator的next属性 gen.next()改为gen.__next__()
4.incl/tensorvision/train.py", line163, in _print_eval_dict
print_str = string.join([nam + ": %.2f" for nam ineval_names],
AttributeError: module 'string' has noattribute 'join'
改为print_str=", ".join([nam + ": %.2f" for nam ineval_names])
5.tensorflow.python.framework.errors_impl.InvalidArgumentError:0-th value returned by pyfunc_0 is uint8, but expects float
修改fastBox.py的evaluaction函数
473行
pred_log_img = tf.py_func(log_image,
[images,test_pred_confidences,
test_pred_boxes,global_step, 'pred'],
[tf.float32])
改为
pred_log_img = tf.py_func(log_image,
[images,test_pred_confidences,
test_pred_boxes,global_step, 'pred'],
[tf.uint8])
修改完后。就可以按照GitHub上面的步骤进行训练了。我复制了一下
- Clone this repository: git clone https://github.com/MarvinTeichmann/KittiBox.git
- Initialize all submodules: git submodule update --init --recursive
- Run cd submodules/utils && make to build cython code
- [Optional] Download Kitti Object Detection Data
- Retrieve Kitti data url here: http://www.cvlibs.net/download.php?file=data_object_image_2.zip
- Call python download_data.py --kitti_url URL_YOU_RETRIEVED
- [Optional] Run cd submodules/KittiObjective2/ && make to build the Kitti evaluation code (seesubmodules/KittiObjective2/README.md for more information)
数据集是KITTI 数据集,上面有下载链接,点击会让你输入一个邮箱,邮箱里有下载的具体地址。当然你也可以取kitti官网直接下载数据和标签。
没有数据集你可以先跑个demo看看效果,跑demo你需要下载KittiBox_pretrained.zip(下载目录ftp://mi.eng.cam.ac.uk/pub/mttt2/models/),demo.py程序是可以自己下载的有点大,2G左右,我是自己下载好的,解压放到新建的RUNS(根据demo.py可以看到)。Run: pythondemo.py --input_image data/demo.png toobtain a prediction using demo.png asinput.
Demo.py还是很容易跑通的。它会输出一大堆信息,然后在demo.png目录下生成一个demo_rects.png就是检测结果。
python demo.py --input_image data/5.png--logdir RUNS/kittiBox_VGG_2017_12_16_19.14 --gpus 0,1
--logdir指定model路径,可以使用任意训练好的model
正式开始训练前还要下载一个vgg.npy(下载链接ftp://mi.eng.cam.ac.uk/pub/mttt2/models/),这是针对用于VGG16训练需要的
现在就可以正式开始训练了
python train.py --hypes hypes/kittiBox_VGG.json --gpus 0,1 指定hypes文件,关于网络的一些参数信息
后面还可以指定一些其他的东西,比如hypes信息,通常是一个json文件,关于model、训练参数等一些信息;
还可以指定GPU训练等等
正常训练的截图:
第一次训练我没有修改参数,全是选用默认参数,训练了很久,双GTX-Titan x训练了40个小时左右吧。
训练完后对模型进行评估
evaluate.py文件
python evaluate.py --hypes hypes/kittiBox_VGG.json --RUNkittiBox_VGG_2017_12_16_19.14 --gpus 0,1 评估,指定hypes文件和model目录
我自己训练的模型评估截图
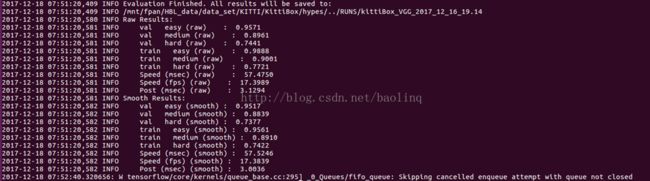
下面是作者提供的pre_trained的评估结果:
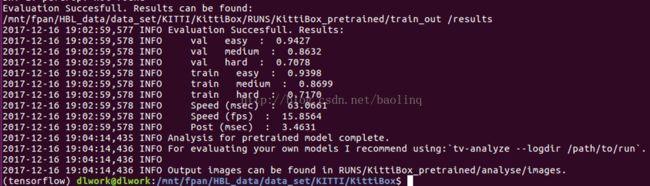
从上图的对比可以看到,我训练的效果竟然比它更好,平均要高1-3的百分点,简直出乎我的意料。
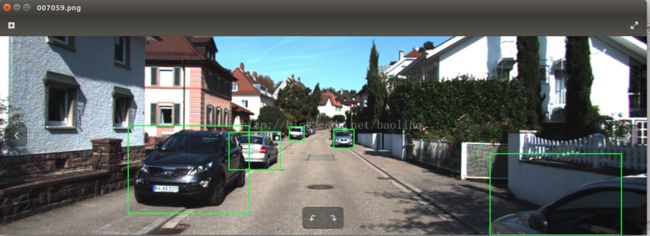
再贴几张检测结果的截图吧

参考
[1] https://github.com/MarvinTeichmann/KittiBox
[2] https://arxiv.org/abs/1612.07695multinet论文
[3] http://blog.csdn.net/hanging_gardens/article/details/72724258一篇翻译
这是我训练KittiBox的一些笔记,不知道会不会适合其他人,有问题欢迎底下交流。
以下是 https://github.com/MarvinTeichmann/KittiBox
代码使用翻译
文章来源:GitHub 作者:Marvin Teichmann 翻译:张妮娜
MultiNet模型分析
MultiNet能够同时完成道路分割、汽车检测和道路分类的任务。MultiNet模型的实时存档速度和分割性能都处于最先进水平。详细的模型描述请查阅我们的论文。
优化后的MultiNet模型在实时速度下表现良好,其要素KittiSeg在道路分割方面设置了一项新的最先进技术,而另一要素KittiBox在推理速度和检测性能上对基线Faster-RCNN进行了改进。
该模型被设计为encoder-decoder架构,在每项任务中使用一个VGG编码器和几个独立解码器。此存储库包括允许在一张网络中将几个tensorflow模型的通用代码组合在一起,不可视任务的代码由KittiSeg、KittiBox和KittiClass存储库提供,这些存储库在该项目中作为子模块。该项目的构建旨在与TensorVision后端兼容,后端能够以十分简洁的方式组织实验。
要求
代码需要Tensorflow 1.0版本以及以下python库:
matplotlib
numpy
Pillow
scipy
runcython
这些模块可以通过以下代码进行安装:
pip install numpy scipy pillowmatplotlib runcythonorpip install -r requirements.txt。
建立
1、克隆该存储库:https://github.com/MarvinTeichmann/MultiNet.git
2、将所有子模块初始化:git submodule update--init --recursive
3、通过'cd submodules / KittiBox /submodules / utils / && make构建cython代码
4、[可选]下载KittiRoad数据:
ⅰ. 这里检索 kitti 数据url网址:http://www.cvlibs.net/download.php?file=data_road.zip
ⅱ.指令python download_data.py --kitti_url URL_YOU_RETRIEVED
5、[可选]运行cdsubmodules / KittiBox / submodules / KittiObjective2 / && make构建Kitti评估代码(更多详细信息请参阅子模块/ KittiBox/submodules / KittiObjective2 / README.md)
使用demo.py运行模型只需要完成步骤1至3。只有当您想使用train.py训练模型时,才需要步骤4和5。需要注意的是,我建议使用download_data.py,而不是自行下载数据。该脚本还将提取并准备相应的数据。如果您想控制数据的存储位置,请参阅“管理数据存储”这部分内容。
教程
入门
运行:python demo.py --gpus 0 --inputdata / demo / um_000005.png使用demo.png作为输入指令以获取预测信息。
运行:python evaluate.py对一个训练模型进行评估。
运行:python train.py --hypes hypes /multinet2.json训练一个multinet2模型
如果您想理解这些代码,我建议先查看demo.py。我已经在文件中尽可能地记录下每个步骤。
只有MultiNet3(同时完成检测和分割任务)的训练是开箱即用的。用于训练分类模型的数据是不公开的,不能用于训练完整的MultiNet3(用于检测、分割和分类任务)模式。完整的代码已在此提供,因此,如果您有自己的数据,您仍然可以训练MultiNet3模型。
管理数据存储
MultiNet允许将数据存储与代码分离。这在许多服务器环境中非常受用。默认情况下,数据存储在MultiNet / DATA文件夹和MultiNet / RUNS中运行输出。可以通过设置bash环境变量$ TV_DIR_DATA和$ TV_DIR_RUNS来更改此行为。
在.profile中,包括导出TV_DIR_DATA =“/ MY / LARGE / HDD / DATA”在内,所有数据将被下载到/ MY / LARGE / HDD / DATA /。在您的.profile中包括导出TV_DIR_RUNS =“/ MY / LARGE / HDD / RUNS”,所有运行将保存到/ MY / LARGE / HDD / RUNS / MultiNet
修改模型并在您自己的数据上进行训练
该模型由文件hypes / multinet3.json控制。此文件将代码指向对子模型的实现过程中。使用MultiNet代码,将已提供的所有模型进行加载,并将解码器集成到一个神经元网络中。要在您自己的数据上进行训练,足以修改子模型的hype文件。从KittiSeg入手将是最佳选择,KittiSeg是有据可查的。
RUNDIR和实验组织
MultiNet可帮助您组织大量实验。为此,每次运行的输出都存储在MultiNet的rundir中。每个rundir包含:
output.log 打印到屏幕上的一个训练输出副本
tensorflowevents可在rundir中运行
tensorflow checkpoints,训练模型可从rundir中加载
[dir]images一个包含示例输出图像的文件夹。 image_iter控制整个验证集的转储频率
[dir] model_files为构建模型所需的所有源代码的副本。如您有很多版本的模型,此项操作对您是很有帮助的。
为跟踪所有实验,您可以以—name为flag,为每个rundir建立独特的名称。--project flag将运行存储在单独的子文件夹中,可以运行不同系列的实验。例如,运行python train.py --project batch_size_bench --name size_5将使用dir作为rundir:$ TV_DIR_RUNS/ KittiSeg / batch_size_bench / size_5_KittiSeg_2017_02_08_13.12。
使用flag--nosave非常有用,而非在rundir中插入垃圾信息。
有用的Flag&Variabels
以下Flag在使用KittiSeg和TensorVision时将会起到帮助,所有Flag可用于所有脚本。
--hypes:指定hype文件的使用
--logdir:指定logdir的使用
--gpus:指定在哪些GPU上运行代码
--name:为运行程序分配一个名称
--project:将项目分配给运行程序
--nosave:调试运行,logdir将被设置为debug
此外,以下TensorVision环境中的Variables将非常有用:
$ TV_DIR_DATA:指定数据的元目录
$ TV_DIR_RUNS:指定输出的元目录
$ TV_USE_GPUS:指定默认GPU行为
在集群上,设置$ TV_USE_GPUS = force是有用的。这将使flag—gpus变为强制性操作,并确保在正确的GPU上运行。
论文地址:https://arxiv.org/pdf/1612.07695.pdf
GitHub资源:https://github.com/MarvinTeichmann/MultiNet