图的深度优先遍历DFS和广度优先遍历BFS
深度优先遍历(栈和递归)
即从初始节点开始访问,而初始节点与多个节点相连接,所以,深度优先遍历的策略就是首先访问第一个邻接结点,然后再以这个被访问的邻接结点作为初始结点,访问它的第一个邻接结点。
总结起来可以这样说:每次都在访问完当前结点后首先访问当前结点的第一个邻接结点。
思路:先以一个点为起点,这里假如是点A,那么就将A相邻的点放入堆栈,然后在栈中再取出栈顶的顶点元素(假如是点B),再将B相邻的且没有访问过的点放入栈中,不断这样重复操作直至栈中元素清空。这个时候你每次从栈中取出的元素就是你依次访问的点,以此实现遍历。
深度优先遍历是纵向搜索数据的。
具体流程如下:
- 1.访问初始结点v,并标记结点v为已访问。
- 2.查找结点v的第一个邻接结点w。
- 3.若w存在,则继续执行4,否则算法结束。
- 4.若w未被访问,对w进行深度优先遍历递归(即把w当做另一个v,然后进行步骤123)。
- 5.查找结点v的下一个邻接结点w,转到步骤3。

package com.duoduo.day316;
/*定义链表的节点类*/
public class Node {
int data; //节点中储存的数据
Node next; //下一节点
public Node(int data) {
this.data=data;
this.next=null;
}
}
public class GraphLink {
public Node first; //头节点
public Node last; //尾节点
/*判断链表是否为空*/
public boolean isEmpty() {
return first==null;
}
/*打印链表节点*/
public void print() {
Node current=first;
while(current!=null) {
System.out.print("["+current.data+"]");
current=current.next;
}
System.out.println();
}
/*插入链表节点*/
public void insert(int newData) {
Node newNode=new Node(newData); //新建节点
//判断链表是否为空
if(isEmpty()) {
first=newNode;
last=newNode;
}else {
last.next=newNode;
last=newNode;
}
}package com.duoduo.day316;
/**
* 图的深度优先遍历
* @author 多多
*
*/
import com.duoduo.day316.GraphLink;
public class TestDFS {
public static int[] run=new int[9]; //run数组用来标记顶点是否已经遍历
public static GraphLink[] head=new GraphLink[9]; //建立图链表数组 存放顶点
/*深度优先遍历子程序*/
public static void dfs(int current) {
run[current]=1; //标记当前顶点已遍历
System.out.print("["+current+"]"); //打印当前已遍历的顶点
while((head[current].first)!=null) { //从链表头结点开始
if(run[head[current].first.data]==0) //如果顶点尚未遍历 就进行DFS递归调用
dfs(head[current].first.data);
head[current].first=head[current].first.next; //如果已经遍历则后移
}
}
public static void main(String [] args) {
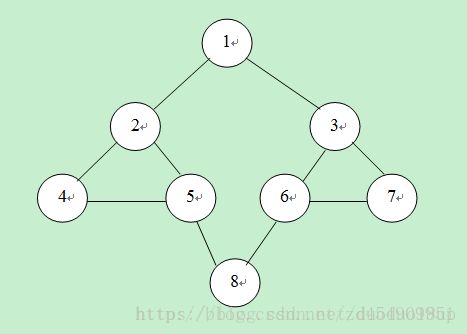
int [][] Data={{1,2},{2,1},{1,3},{3,1},{2,4},{4,2},{2,5},{5,2},{3,6},{6,3},{3,7},{7,3},{4,5},{5,4},{6,7},{7,6},{5,8},{8,5},{6,8},{8,6}};
int newData;
int i,j;
System.out.println("邻接表的内容是:");
for(i=1 ;i<9;i++) { //共有8个顶点
run[i]=0; //设定所有顶点均未遍历过
head[i]=new GraphLink(); //为第i个顶点创建链表
System.out.print("顶点"+i+"-->");
for(j=0;j<20;j++) { //20条边线
if(Data[j][0]==i) { //如果起点和链表首 相同 则把顶点插入链表
newData=Data[j][1];
head[i].insert(newData);
}
}
head[i].print(); //每个顶点处理完后输出该顶点的链表
System.out.println("深度优先遍历顶点:");
dfs(1);
System.out.println();
}
}
广度优先遍历(队列和递归)
类似于一个分层搜索的过程,广度优先遍历需要使用一个队列以保持访问过的结点的顺序,以便按这个顺序来访问这些结点的邻接结点。
具体算法表述如下:
- 1.访问初始结点v并标记结点v为已访问。
- 2 .结点v入队列
- 3.当队列非空时,继续执行,否则算法结束。
- 4.出队列,取得队头结点u。
- 5.查找结点u的第一个邻接结点w。
- 6.若结点u的邻接结点w不存在,则转到步骤3;否则循环执行以下三个步骤:
- (1). 若结点w尚未被访问,则访问结点w并标记为已访问。
- (2). 结点w入队列
- (3). 查找结点u的继w邻接结点后的下一个邻接结点w,转到步骤6。
public static void BFS(int current)代码如下:
package com.duoduo.day316;
import com.duoduo.day316.GraphLink;
import com.duoduo.day316.Node;
public class TestQueue {
public static int[] run=new int[9]; //用来记录各顶点是否遍历过
public static GraphLink[] head=new GraphLink[9];
public final static int MAXSIZE=10; //定义队列的最大容量
static int[] queue=new int[MAXSIZE]; //队列数组的声明
static int front=-1,rear=-1; //定义队列的头指针和尾指针
public static void main(String[] args) {
int data[][]= {{1,2},{2,1},{1,3},{3,1},{2,4},{4,2},{2,5},{5,2},{3,6},{6,3},{3,7},{7,3},{4,5},{5,4},{6,7},{7,6},{5,8},{8,5},{6,8},{8,6}};
System.out.println("图形的邻接表的内容:");
for(int i=1;i<9;i++) {
run[i]=0;
head[i]=new GraphLink();
System.out.print("顶点"+i+"=>");
for(int j=0;j=MAXSIZE) //队列已满
return;
rear++;
queue[rear]=value;
}
/*队列数据的取出*/
public static int dequeue() {
if(front==rear) //队列为空
return -1;
front++;
return queue[front];
}
}
class Node{
int data; //顶点
Node next;
public Node(int data) {
this.data=data;
this.next=null;
}
}
class GraphLink{
public Node first; //头节点
public Node last; //尾节点
public boolean isEmpty() {
return first==null;
}
public void print() { //打印链表
Node current=first;
while(current!=null) {
System.out.print("["+current.data+"]");
current=current.next;
}
System.out.println();
}
public void insert(int data) { //将节点插入链表
Node newNode=new Node(data);
if(this.isEmpty()) { //判断链表是否为空
first=newNode;
last=newNode;
}
else { //尾插法
last.next=newNode;
last=newNode;
}
}
}