spark sql 的介绍
Spark SQL允许Spark执行用SQL, HiveQL或者Scala表示的关系查询。这个模块的核心是一个新类型的RDD-SchemaRDD。SchemaRDDs由行对象组成,行对象拥有一个模式(scheme)来描述行中每一列的数据类型。SchemaRDD与关系型数据库中的表很相似。可以通过存在的RDD、一个Parquet文件、一个JSON数据库或者对存储在Apache Hive中的数据执行HiveSQL查询中创建。
sql 里面的四种语言:
DDL (Data Definition Language) 数据定义语言 DML (Data Manipulation Language)数据处理语言 DQL (Data Query Language)数据查询语言 DCL (Data Control Language)数据控制语言
SparkSQL
1. Spark中原生的RDD是没有数据结构的
2. 对RDD的变换和操作不能采用传统的SQL方法
3. SparkSQL应运而生并建立在SHARK上,伯克利实验室spark生态环境的组件之一
4. SPARK最初很大程度上依赖性HIVE如语法解析器、查询优化器等
5. 改进的SparkSQL框架摆脱了对Hive的依赖性,所以无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便
SparkSQL的优势
数据兼容:数据结果集本身就是SPARKRDD,SparkSQL 可兼容Hive,JSON和parquet等文件,并可以获取RDBMS数据以及 访问Cassandra等NOSQL数据文件
性能优化:除了采取in-MemoryColumnar Storage、byte-code generation等优化技术外、将会引进cost model对查询进行 动态评估、获取最佳物理计划等等
组件扩展 :SQL的语法解析器、分析器还是优化器都可以重新定义,进行扩展,如HIVE SQL
SparkSQL运行框架
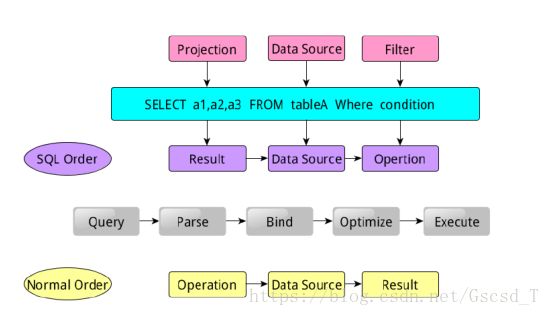
SparkSQL语句的顺序为:
1. 对读入的SQL语句进行解析(Parse),分辨出SQL语句的关键词(如select 、from、where并判断SQL语句的合法 性)
2. 将SQL语句和数据库的数据字典进行绑定(Bind)如果相关的projection、data source等都是存在的话,就表示这个 SQL语句是可以执行的
3. 数据库会在这个计划中选择一个最优计划(optimize)
4. 计划执行(Execute),按operation->data source->result的次序来进行的,在执行过程有时候不需要读取物理表 就可以返回结果,如果查询运行过刚运行过的SQl语句,可能直接从数据库的缓冲池中获取返回结果。
实现SparkSQL
1. 产生SchemaRDD--为了实现SPARKSQL必须将一般的RDD转换成带数据结构的数据集dataFrame
2. SchemaRDD本身是一个RDD,但它本身包含是由行对象(row object)组成。每个行对象代表一条记录
3. SchemaRDD提供了一些新的操作应用函数使得数据操作和分析更高效和简洁
4. 可以将SchemaRDD注册成表,这样就可以用SQL访问RDD数据了,而结果集本身也可以是SchemaRDD即dataFrame
5. 可以用各种方法生成SchemaRDD
产生DataFrame的方法
1. 由已存在的RDD产生SchemaRDD。有以下两种方法:
a) 从行对象推出数据结构并安插到原RDD上形成一SchemaRDD即DataFrame(语句较为简洁)
b) 用编程的方法产生数据结构并用在DataFrame生成函数的参数中以形成一SchemaRDD
2. 读入json,parquet,AVRO或CSV文件时读成SchemaRDD即dataFrame。这是因为这些文件本身就是带有结构的
3. 将python或R中的dataFrame装换成spark中的SchemaRDD
注意:如果在DataFrame上使用SQL必须将它注册成表。当然SPARK DataFrame有自己的一套数据操作和分析APIs. 这些APIs 类似于PYTHON PANDAS中的DataFrame方法。