PLSQL 批量更新数据效率问题
最近做报表项目遇到一个棘手问题,需要把旧系统的30w条数据更新到oracle数据库中,旧系统的数据保存在excel里面,结构如下:
| vipno | sss | ssss |
| 1 | aa | aaa |
| 2 | b | bbb |
... |
... | ... |
数据库的表t结构类似,但是我需要根据excel里面的vipno更新新oracle数据库sss 和 ssss列。其中t.vipno上建有索引
尝试过好几种方法,效率和工作量都不一样,特此记录下来
- 方法一
首先想到的方法是,大不了生成30w条update语句,一一更新每行数据呗,反正以前也这么干过。
直接在excel里面用CONCATENATE公式拼接出update语句,
update t set sss='aa', ssss='aaa' where vipno = '1';
一拉30w条update搞定。直接copy到PLSQL 窗口里,按Execute, 然后整个窗口卡在那里。后来我也尝试过1000条update,都会卡住。我已经对vipno去重,所以不应该出现重复update但未commit锁住的情况。

后来放在服务器上跑了一夜,一直是卡住,也不报内存满等问题,此方法不可行。
- 方法二:
将update语句放在Begin End 语句块中,每句update后加commit:
Begin
update t set sss='aa', ssss='aaa' where vipno = '1';
commit;
...
End;![]()
- 方法三
利用PLSQL 将excel表导入数据库,再连表批量更新。
Tools -> ODBC Importer
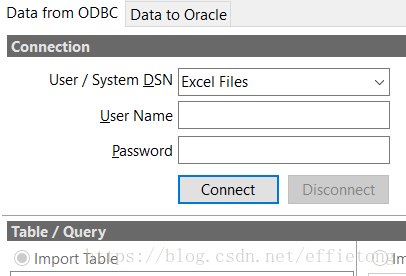

匹配好列就可以导入。30w+条大概20分钟导完,再在t2.userid上建个索引。
用一下语句更新:
update t
set (t.sss,t.ssss) = (select t2.sss,t2.ssss from t2 where t2.userid = t.userid)
where exists (select 1 from t2 where t2.userid = t.userid);
commit;然而还是很慢,一直是executing 状态,无法知道更新到多少行,所以无法知道大概用多久时间。
方法四:
仍然利用导进来的数据, 用游标方式进行更新,每更新一句就commit。
declare
cursor vi_cursor is (select * from t);
vi_row vi_cursor%rowtype;
begin
for vi_row in vi_cursor loop
update t
set (t.sss,t.ssss) = (
select t2.sss,t2.ssss from t2
where t2.userid= vi_row.userid
)
where t.userid = vi_row.userid;
COMMIT;
end loop;
end;我还没有找到更好的办法,希望有类似经验的分享一下,谢谢