综述 | SLAM回环检测方法
本文作者任旭倩,公众号:计算机视觉life成员,由于格式原因,公式显示可能出问题,建议阅读原文链接:综述 | SLAM回环检测方法
在视觉SLAM问题中,位姿的估计往往是一个递推的过程,即由上一帧位姿解算当前帧位姿,因此其中的误差便这样一帧一帧的传递下去,也就是我们所说的累积误差。一个消除误差有效的办法是进行回环检测。回环检测判断机器人是否回到了先前经过的位置,如果检测到回环,它会把信息传递给后端进行优化处理。回环是一个比后端更加紧凑、准确的约束,这一约束条件可以形成一个拓扑一致的轨迹地图。如果能够检测到闭环,并对其优化,就可以让结果更加准确。
在检测回环时,如果把以前的所有帧都拿过来和当前帧做匹配,匹配足够好的就是回环,但这样会导致计算量太大,匹配速度过慢,而且没有找好初值的情况下,需要匹配的数目非常巨大。因此回环检测是SLAM问题的一个难点,针对这个问题,在这里我们总结几种经典的方法供大家参考。
词袋模型(Bag Of Words,BOW)
原理
简介:现有的SLAM系统中比较流行的回环检测方法是特征点结合词袋的方法(如ORB-SLAM,VINS-Mono)等。基于词袋的方法是预先加载一个词袋字典树,通知这个预加载的字典树将图像中的每一局部特征点的描述子转换为一个单词,字典里包含着所有的单词,通过对整张图像的单词统计一个词袋向量,词袋向量间的距离即代表了两张图像之间的差异性。在图像检索的过程中,会利用倒排索引的方法,先找出与当前帧拥有相同单词的关键帧,并根据它们的词袋向量计算与当前帧的相似度,剔除相似度不够高的图像帧,将剩下的关键帧作为候选关键帧,按照词袋向量距离由近到远排序[1]。
字典、单词、描述子之间的关系是:
字 典 ⊃ 单 词 ⊃ 差 距 较 小 的 描 述 子 的 集 合 字典\supset单词 \supset 差距较小的描述子的集合 字典⊃单词⊃差距较小的描述子的集合
因此,可将基于词袋模型的回环检测方法分为以下三个步骤[2]:
1.提取特征
2.构建字典(所有单词的集合)
D = ( ω 1 , ω 2 , ω 3 … ω n − 1 , ω n ) D=\left(\omega_{1}, \omega_{2}, \omega_{3} \dots \omega_{n-1}, \omega_{n}\right) D=(ω1,ω2,ω3…ωn−1,ωn)
3.确定一帧中具有哪些单词,形成词袋向量 (1表示具有该单词,0表示没有)
F = 1 ⋅ ω 1 0 ⋅ ω 2 0 ⋅ ω 3 … 1 ⋅ ω n − 1 0 ⋅ ω n F=1 \cdot \omega_{1} 0 \cdot \omega_{2} 0 \cdot \omega_{3} \ldots 1 \cdot \omega_{n-1} 0 \cdot \omega_{n} F=1⋅ω10⋅ω20⋅ω3…1⋅ωn−10⋅ωn
4.比较两帧描述向量的差异。
下面分模块逐个介绍:
构建字典
相当于描述子聚类过程,可以用K近邻算法,或者使用已经探索过的环境中的特征在线动态生成词袋模型[3]。
(1)k近邻算法
根据已经离线采集的图像,提取特征描述子,用k近邻算法形成字典的流程是:
1.在字典中的多个描述子中随机选取k个中心点:
c 1 , … , c k c_{1}, \dots, c_{k} c1,…,ck
2.对于每一个样本,计算它与每个中心点之间的距离,取最小的中心点作为它的归类。
3.重新计算每个类的中心点。
4.如果每个中心点都变化很小,则算法收敛,退出,否则继续迭代寻找。
每个归好的类就是一个单词,每个单词由聚类后距离相近的描述子组成。
其他类似方法还有层次聚类法、K-means 等。
Kmeans 算法是基于Kmeans改进而来,主要改进点在于中心点的初始化上,不像原始版本算法的随机生成,它通过一些策略使得k个初始中心点彼此间距离尽量地远,以期获得这些中心点具有更好的代表性,有利于后面的分类操作的效果[8]。
Kmeans 算法中中心点初始化的流程如下:
1.从n个样本中随机选取一个点作为第一个中心点;
2.计算样本中每个点和距离它最近的中心点之间的距离 D i D_{i} Di,根据策略选择新的中心点
3.重复2直至得到k个中心点。
(2)在线动态生成词袋模型:
传统的BOW模型生成离线的字典,更灵活的方法是动态地创建一个字典,这样没有在训练集中出现地特征可以被有效地识别出来。典型论文有[4],[5]。
在论文中将图像识别中词袋模型进行了扩展,并用贝叶斯滤波来估计回环概率。回环检测问题涉及识别已建图区域的困难,而全局定位问题涉及在现有地图中检索机器人位置的困难。当在当前图像中找到一个单词时,之前看到过这个单词的图片的tf-idf 分数将会更新。该方法根据探索环境时遇到的特征动态地构建字典,以便可以有效识别训练集中未表示的特征的环境。
字典树
因为字典太过庞大,如果一一查找匹配单词,会产生很大的计算量,因此可以用k叉树的方式来表达字典,建立字典树流程是这样的[6]:
-
对应用场景下的大量训练图像离线提取局部描述符(words)(每张图像可能会有多个描述符)
-
将这些描述符KNN聚成k类;
-
对于第一层的每一节点,继续KNN聚成k类,得到下一层;
-
按这个循环,直到聚类的层次数达到阈值d,叶子节点表示一个word,中间节点则是聚类的中心。
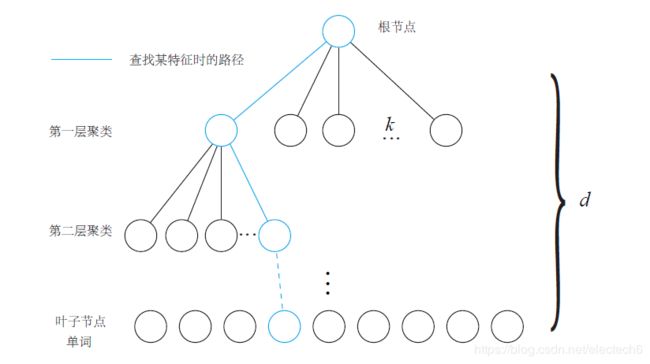
(图源:视觉SLAM十四讲)
然而建立词袋的一个主要缺点是,它需要预先载入一个训练好的词袋字典树,这个字典树一般包含大量的特征单词,为了保证有良好的区分能力,否则对图像检索结果有较大影响,但是这会导致这个字典文件比较大,对于一些移动应用来说会是一个很大的负担。为了解决这个问题,可以通过动态建立k-d树来避免预载入字典的麻烦。在添加关键帧的过程中维护一个全局的k-d树,将每个特征点以帧为单位添加到这个k-d树中。在图像检索过程中,寻找最接近的节点进行匹配,根据匹配结果对每个关键帧进行投票,获得的票数即可作为该帧的分数,从而生成与当前帧相似的关键帧候选集[1]。
词袋向量
关键帧和查询帧的相似度是通过词袋向量之间的距离来衡量的。假定一幅图像I的局部描述符集合是[6]
D I = { d 1 , d 2 , ⋯ , d n } D_{I}=\left\{d_{1}, d_{2}, \cdots, d_{n}\right\} DI={d1,d2,⋯,dn}
每个描述符 d i d_{i} di在字典树中查找距离最近的word,假定其word_id为 j j j,其对应的权重为 w j w_{j} wj。查找过程从字典树的根节点开始,每一层都找距离最近的节点,然后下一层中继续,直至到达叶子节点。
记词表的大小为 ∣ V ∣ |V| ∣V∣,定义这个在字典树中查找的映射为
V T ( ⋅ ) : D → { 1 , 2 , ⋯ , ∣ V ∣ } V T(\cdot) : D \rightarrow\{1,2, \cdots,|V|\} VT(⋅):D→{1,2,⋯,∣V∣}
如果两个描述符映射到同一个word,则权重相加,得到一个定长的向量:
V I = { v 1 , v 2 , ⋯ , v j , ⋯ , v ∣ V ∣ } V_{I}=\left\{v_{1}, v_{2}, \cdots, v_{j}, \cdots, v_{|V|}\right\} VI={v1,v2,⋯,vj,⋯,v∣V∣}
其中
v j = ∑ i , V T ( d i ) = j w j v_{j}=\sum_{i, V T\left(d_{i}\right)=j} w_{j} vj=i,VT(di)=j∑wj
这样在根据word查找关键帧时,就不用遍历所有的关键帧,只要把查询帧描述符映射的那些words索引的关键帧找到即可。
相似度计算
一些词在用来识别两个图像是否显示同一个地方比其他词更加有用,而有一些词对识别贡献不大,为了区分这些词的重要性,可以为每个词分配特定权重,常见方案是TF-IDF。它综合了图像中的词的重要性(TF-Term Frequency)和收集过程中词的重要性(IDF-Inverse Document Frequency),用以评估一个词对于一个文件或者一个语料库中的一个领域文件集的重复程度。
对于单幅图像,假设在单幅图像中一共出现的单词次数为 n n n,某个叶子节点单词 w i w_{i} wi出现了 n i n_{i} ni次,则TF为[7]:
TF:某个特征在单幅图像中出现的频率,越高则它的区分度就越高
T F i = n i n T F_{i}=\frac{n_{i}}{n} TFi=nni
在构建字典时,考虑IDF,假设所有特征数量为 n n n,叶子节点 w i w_{i} wi的数量为 n i n_{i} ni,则IDF为
IDF:某单词在字典中出现的频率越低,则区分度越低
I D F i = ln ( n n i ) I D F_{i}=\ln \left(\frac{n}{n_{i}}\right) IDFi=ln(nin)
则 w i w_{i} wi的权重等于TF和IDF的乘积:
η i = T F i × I D F i \eta_{i}=T F_{i} \times I D F_{i} ηi=TFi×IDFi
考虑权重后,对于某个图像 A A A,它的特征点可以对应很多单词,组成它的词袋:
A = { ( w 1 , η 1 ) , ( w 2 , η 2 ) , … , ( w N , η N ) } ≜ v A A=\left\{\left(w_{1}, \eta_{1}\right),\left(w_{2}, \eta_{2}\right), \ldots,\left(w_{N}, \eta_{N}\right)\right\} \triangleq v_{A} A={(w1,η1),(w2,η2),…,(wN,ηN)}≜vA
这样便用单个向量 v A v_{A} vA描述了一个图像 A A A,这个向量是一个稀疏向量,非零部分代表含有哪些单词,这些值即为TF-IDF的值。
得到 A A A 、 B B B 两幅图像的 v A v_{A} vA和 v B v_{B} vB后,可以通过 L 1 L_{1} L1范式形式计算差异性:
s ( v A − v B ) = 2 ∑ i = 1 N ∣ v A i ∣ ∣ v B i ∣ − ∣ v A i − v B i ∣ s\left(v_{A}-v_{B}\right)=2 \sum_{i=1}^{N}\left|v_{A i}\right| \left|v_{B i}\right|-\left|v_{A i}-v_{B i}\right| s(vA−vB)=2i=1∑N∣vAi∣∣vBi∣−∣vAi−vBi∣
其中, v A i v_{A i} vAi表示只在 A A A中有的单词, v B i v_{B i} vBi表示只在 B B B中有的单词, v A i − v B i v_{A i}-v_{B i} vAi−vBi表示在 A A A、 B B B中都有的单词。 s s s越大,相似性越大,当评分 s s s足够大时即可判断两帧可能为回环。
此外,如果只用绝对值表示两幅图像的相似性,在环境本来就相似的情况下帮助并不大,因此,可以取一个先验相似度 S ( v t , v t − Δ t ) \boldsymbol{S}\left(\boldsymbol{v}_{t}, \boldsymbol{v}_{t-\Delta t}\right) S(vt,vt−Δt),它表示某时刻关键帧图像与上一时刻关键帧的相似性,然后,其他分之都参照这个值进行归一化:
s ( v t , v t j ) ′ = s ( v t , v t j ) / s ( v t , v t − Δ t ) s\left(\boldsymbol{v}_{t}, \boldsymbol{v}_{t_{j}}\right)^{\prime}=s\left(\boldsymbol{v}_{t}, \boldsymbol{v}_{t_{j}}\right) / s\left(\boldsymbol{v}_{t}, \boldsymbol{v}_{t-\Delta t}\right) s(vt,vtj)′=s(vt,vtj)/s(vt,vt−Δt)
因此,可以定义如果当前帧与之前某关键帧的相似度,超过当前帧与上一关键帧相似度的3倍,就认为可能存在回环。
此外,还有其他的方法,分为局部(Squared TF, Frequency logarithm, Binary,BM25 TF等等)和全局(Probabilistic IDF, Squared IDF)等,感兴趣可以继续搜索。
回环验证
词袋模型的另一个问题是它并不完全精确,会出现假阳性数据。在回环检测检索的后期阶段需要用其他方法加以验证。如果当前跟踪已经完全丢失,需要重定位给出当前帧的位姿来调整。在重定位的验证中,使用空间信息进行筛选,可以使用PnP进行后验校正,或者使用条件随机场。这个验证可以去掉那些和参考图像不符合几何一致性的图像[3]。得到准确的图像匹配后,可以根据匹配结果去求解相机位姿。
如果系统跟踪正常,发现了之前访问过的场景,需要进行回环检测添加新约束。基于词袋的回环检测方法只在乎单词有无,不在乎单词的排列顺序,会容易引发感知偏差,此外,词袋回环完全依赖于外观而没有利用任何的几何信息,会导致外观相似的图像容易被当作回环,因此需要加一个验证步骤,验证主要考虑以下三点[1]:
1)不与过近的帧发生回路闭合如果关键帧选得太近,那么导致两个关键帧之间的相似性过高,检测出的回环意义不大,所以用于回环检测的帧最好是稀疏一些,彼此之间不太相同,又能涵盖整个环境[7]。且为了避免错误的回环,某一位姿附近连续多次(ORB-SLAM中为3次)与历史中某一位姿附近出现回环才判断为回环;回环候选帧仍然要匹配,匹配点足够才为回环。
2)闭合的结果在一定长度的连续帧上都是一致的。如果成功检测到了回环,比如说出现在第1 帧和第 n n n 帧。那么很可能第 n 1 n 1 n1 帧, n 2 n 2 n2 帧都会和第1 帧构成回环。但是,确认第1 帧和第 n n n 帧之间存在回环,对轨迹优化是有帮助的,但再接下去的第 n 1 n 1 n1 帧, n 2 n 2 n2 帧都会和第1 帧构成回环,产生的帮助就没那么大了,因为已经用之前的信息消除了累计误差,更多的回环并不会带来更多的信息。所以,我们会把“相近”的回环聚成一类,使算法不要反复地检测同一类的回环。
3)闭合的结果在空间上是一致的。即是对回环检测到的两个帧进行特征匹配,估计相机的运动,再把运动放到之前的位姿图中,检查与之前的估计是否有很大出入。
经典词袋模型源码
DBOW
这个库已经很旧了,简要介绍:DBow库是一个开源C 库,用于索引图像并将图像转换为词袋表示。它实现了一个分层树,用于近似图像特征空间中的最近邻并创建可视词汇表。DBow还实现了一个基于逆序文件结构的图像数据库,用于索引图像和快速查询。DBow不需要OpenCV(演示应用程序除外),但它们完全兼容。
源码地址:https://github.com/dorian3d/DBow
DBOW2
DBoW2是DBow库的改进版本,DBoW2实现了具有正序和逆序指向索引图片的的图像数据库,可以实现快速查询和特征比较。与以前的DBow库的主要区别是:
- DBoW2类是模板化的,因此它可以与任何类型的描述符一起使用。
- DBoW2可直接使用ORB或BRIEF描述符。
- DBoW2将直接文件添加到图像数据库以进行快速功能比较,由DLoopDetector实现。
- DBoW2不再使用二进制格式。另一方面,它使用OpenCV存储系统来保存词汇表和数据库。这意味着这些文件可以以YAML格式存储为纯文本,更具有兼容性,或以gunzip格式(.gz)压缩以减少磁盘使用。
- 已经重写了一些代码以优化速度。DBoW2的界面已经简化。
- 出于性能原因,DBoW2不支持停止词。
DBoW2需要OpenCV和Boost::dynamic_bitset类才能使用BRIEF版本。
DBoW2和DLoopDetector已经在几个真实数据集上进行了测试,执行了3毫秒,可以将图像的简要特征转换为词袋向量量,在5毫秒可以在数据库中查找图像匹配超过19000张图片。
源码地址:https://github.com/dorian3d/DBoW2
DBoW3
DBoW3是DBow2库的改进版本,与以前的DBow2库的主要区别是:
- DBoW3只需要OpenCV。DLIB的DBoW2依赖性已被删除。
- DBoW3能够适用二进制和浮点描述符。无需为任何描述符重新实现任何类。
- DBoW3在linux和windows中编译。
- 已经重写了一些代码以优化速度。DBoW3的界面已经简化。
- 使用二进制文件。二进制文件加载/保存比yml快4-5倍。而且,它们可以被压缩。
- 兼容DBoW2的yml文件
源码地址:https://github.com/rmsalinas/DBow3
FBOW
FBOW(Fast Bag of Words)是DBow2 / DBow3库的极端优化版本。该库经过高度优化,可以使用AVX,SSE和MMX指令加速Bag of Words创建。在加载词汇表时,fbow比DBOW2快约80倍(参见tests目录并尝试)。在使用具有AVX指令的机器上将图像转换为词袋时,它的速度提高了约6.4倍。
源码地址:https://github.com/rmsalinas/fbow
FAB-MAP
是一种基于外观识别场所问题的概率方法。我们提出的系统不仅限于定位,而是可以确定新观察来自以前看不见的地方,从而增加其地图。实际上,这是一个外观空间的SLAM系统。我们的概率方法允许我们明确地考虑环境中的感知混叠——相同但不明显的观察结果来自同一地点的可能性很小。我们通过学习地方外观的生成模型来实现这一目标。通过将学习问题分成两部分,可以仅通过对一个地方的单个观察来在线学习新地点模型。算法复杂度在地图中的位置数是线性的,特别适用于移动机器人中的在线环闭合检测。
源码地址:https://github.com/arrenglover/openfabmap
词袋模型在V-SLAM上的实现
c 版本
博客介绍:https://nicolovaligi.com/bag-of-words-loop-closure-visual-slam.html
源码地址:https://github.com/nicolov/simple_slam_loop_closure
python版本
Loop Closure Detection using Bag of Words
源码地址:https://github.com/pranav9056/bow
matlab:
博客介绍:http://www.jaijuneja.com/blog/2014/10/bag-words-localisation-mapping-textured-scenes/
源码地址:https://github.com/jaijuneja/texture-localisation-matlab
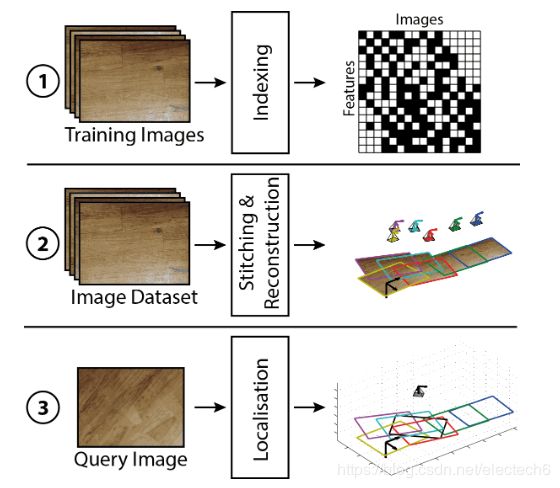
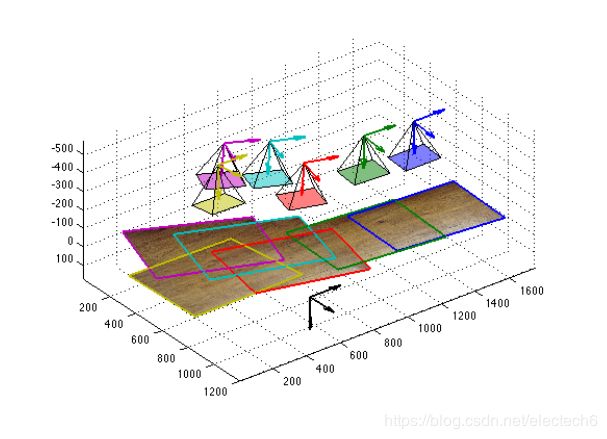
ORB-SLAM
源码地址:https://github.com/raulmur/ORB_SLAM
ORB-SLAM2
源码地址:https://github.com/raulmur/ORB_SLAM2
VINS-Mono
https://github.com/HKUST-Aerial-Robotics/VINS-Mono
kintinous
https://github.com/mp3guy/Kintinuous
文献资料
[1] 鲍虎军,章国峰 ,秦学英.增强现实:原理、算法与应用[M].科学出版社:北京,2019:114-115.
[2] https://zhuanlan.zhihu.com/p/45573552
[3] J. Fuentes-Pacheco, J. Ruiz-Ascencio, and J. M. Rendón-Mancha, “Visual simultaneous localization and mapping: a survey,” Artif Intell Rev, vol. 43, no. 1, pp. 55–81, Jan. 2015.
[4] A. Angeli, S. Doncieux, J.-A. Meyer, and D. Filliat, “Real-time visual loop-closure detection,” in 2008 IEEE International Conference on Robotics and Automation, Pasadena, CA, USA, 2008, pp. 1842–1847.
[5] T. Botterill, S. Mills, A. Ltd, and C. St, “Bag-of-Words-driven Single Camera Simultaneous Localisation and Mapping,” p. 28.
[6] https://www.zhihu.com/question/49153462
[7] 高翔,张涛.视觉SLAM十四讲[M].电子工业出版社,2017:306-316.
[8] https://blog.csdn.net/lwx309025167/article/details/80524020
随机蕨法(Random ferns)
原理
这种重定位方法将相机的每一帧压缩编码,并且有效的对不同帧之间相似性进行评估。而压缩编码的方式采用随机蕨法。在这个基于关键帧的重定位方法中,采用基于fern的帧编码方式:输入一个RGB-D图片,在图像的随机位置评估简单的二进制测试,将整个帧进行编码,形成编码块,每个fern产生一小块编码,并且编码连接起来可以表达一个紧凑的相机帧。每一个编码块指向一个编码表的一行,和具有等效的编码、存储着关键帧id的fern关联起来,编码表以哈希表的形式存储。
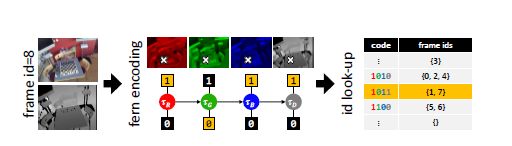
当不断采集新的图片时,如果不相似性大于阈值,新进来的帧的id将会被添加到行中。在跟踪恢复的时候,从哈希表中检索姿态,将最相似的关键帧关联起来。一个新的帧和之前所有编码帧之间的不相似程度通过逐块汉明距离(BlockHD)来度量。
BlockHD ( b C I , b C J ) = 1 m ∑ k = 1 m b F k I ≡ b F k J \operatorname{BlockHD}\left(b_{C}^{I}, b_{C}^{J}\right)=\frac{1}{m} \sum_{k=1}^{m} b_{F_{k}}^{I} \equiv b_{F_{k}}^{J} BlockHD(bCI,bCJ)=m1k=1∑mbFkI≡bFkJ
当返回值是0时,两个编码块是相似的。当返回值是1时,代表至少有一位不同。因此,BlockHD代表不同编码块的个数。块的长短不同,会直接影响到BlockHD在找相似帧时的精度/召回性质。判断一张图片是否满足足够的相似性需要设定一个最小BlockHD, 对于每一张新来的帧,计算
κ I = min ∀ J B lockHD ( b C I , b C J ) = min ∀ J ( m − q I J m ) \kappa_{I}=\min _{\forall J} \mathrm{B} \operatorname{lockHD}\left(b_{C}^{I}, b_{C}^{J}\right)=\min _{\forall J}\left(\frac{m-q_{I J}}{m}\right) κI=∀JminBlockHD(bCI,bCJ)=∀Jmin(mm−qIJ)
κ I \kappa_{I} κI表示新的一个帧提供了多少有用的信息,如果新的一帧 κ I \kappa_{I} κI值很低,代表该帧和之前的帧很相似,如果 κ I \kappa_{I} κI值高,表示这个姿态是从一个新的视角拍摄的,理应被存为关键帧。通过这样的观测,可以试试捕获追踪帧,并且自动决定哪些应该被存为关键帧。通过值 κ I \kappa_{I} κI和一个实现确定好的阈值 t t t,可以决定新来的一帧是应该添加到哈希表中,还是被剔除。这种找到关键帧并检索位姿的方法可以有效的减少三维重建的时间,并且适用于目前开源的slam算法。
代码
Random Fern在VSLAM中的应用
kinect fusion
https://github.com/Nerei/kinfu_remake
elastic fusion
https://github.com/mp3guy/ElasticFusion
PTAM
PTAM中的重定位方法和random ferns很像。PTAM是在构建关键帧时将每一帧图像缩小并高斯模糊生成一个缩略图,作为整张图像的描述子。在进行图像检索时,通过这个缩略图来计算当前帧和关键帧的相似度。这种方法的主要缺点是当视角发生变化时,结果会发生较大的偏差,鲁棒性不如基于不变量特征的方法。
https://github.com/Oxford-PTAM/PTAM-GPL
文献资料
[1] B. Glocker, S. Izadi, J. Shotton, and A. Criminisi, “Real-time RGB-D camera relocalization,” in 2013 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Adelaide, Australia, 2013, pp. 173–179.
[2] B. Glocker, J. Shotton, A. Criminisi, and S. Izadi, “Real-Time RGB-D Camera Relocalization via Randomized Ferns for Keyframe Encoding,” IEEE Trans. Visual. Comput. Graphics, vol. 21, no. 5, pp. 571–583, May 2015.
[3] https://blog.csdn.net/fuxingyin/article/details/51436430
基于深度学习的方法
基于深度学习的图像检索方法是全局检索方法,需要大量的数据进行预训练,但对场景变化容忍度好。一些端到端的相机位姿估计方法取得了不错的成果。深度学习和视觉定位结合的开创性工作PoseNet就使用的是神经网络直接从图像中得到6自由度的相机位姿。相较于传统的视觉定位方法,省去了复杂的图像匹配过程,并且不需要对相机位姿进行迭代求解,但是输入图像必须在训练场景中。后来在此基础上,他们又在误差函数中使用了投影误差,进一步提高了位姿估计的精度。同样,MapNet使用了传统方法求解两张图象的相对位姿,与网络计算出来的相对位姿对比得到相机的相对位姿误差,将相对位姿误差添加到网络的损失函数中,使得求解出来的相机位姿更加平滑,MapNet还可以将连续多帧的结果进行位姿图优化,使得最终估计出的相机位姿更为准确。
有监督的方法
基本都是用周博磊的Places365
原理介绍:Places365是Places2数据库的最新子集。Places365有两个版本:Places365-Standard和Places365-Challenge。Places365-Standard的列车集来自365个场景类别的约180万张图像,每个类别最多有5000张图像。我们已经在Places365-Standard上训练了各种基于CNN的网络,并将其发布如下。同时,一系列的Places365-Challenge列车还有620万张图片以及Places365-Standard的所有图片(总共约800万张图片),每个类别最多有40,000张图片。Places365-Challenge将与2016年的Places2挑战赛一起举行ILSVRC和COCO在ECCV 2016上的联合研讨会。
Places3-标准版和Places365-Challenge数据在Places2网站上发布。
Places365-Standard上经过预先培训的CNN模型:
- AlexNet-places365
- GoogLeNet-places365
- VGG16-places365
- VGG16-hybrid1365
- ResNet152-places365
- ResNet152-hybrid1365
源码地址:https://github.com/CSAILVision/places365

无监督的方法
CALC原理
在大型实时SLAM中采用无监督深度神经网络的方法检测回环可以提升检测效果。该方法创建了一个自动编码结构,可以有效的解决边界定位错误。对于一个位置进行拍摄,在不同时间时,由于视角变化、光照、气候、动态目标变化等因素,会导致定位不准。卷积神经网络可以有效地进行基于视觉的分类任务。在场景识别中,将CNN嵌入到系统可以有效的识别出相似图片。但是传统的基于CNN的方法有时会产生低特征提取,查询过慢,需要训练的数据过大等缺点。而CALC是一种轻量级地实时快速深度学习架构,它只需要很少的参数,可以用于SLAM回环检测或任何其他场所识别任务,即使对于资源有限地系统也可以很好地运行。
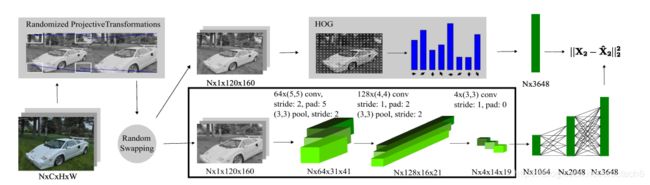
这个模型将高维的原始数据映射到有旋转不变性的低维的描述子空间。在训练之前,图片序列中的每一个图片进行随机投影变换,重新缩放成120×160产生图像对,为了捕捉运动过程中的视角的极端变化。然后随机选择一些图片计算HOG算子,采用固定长度的HOG描述子可以帮助网络更好地学习场景的几何。将训练图片的每一个块的HOG存储到堆栈里,定义为 X 2 X_{2} X2维度为 N × D N \times D N×D,其中 N N N是块大小, D D D是每一个HOG算子的维度。网络有两个带池化层的卷积层,一个纯卷积层,和三个全连接层,同时用ReLU做卷积层的激活单元。在该体系结构中,将图片进行投影变换,提取HOG描述子的操作仅针对整个训练数据集计算一次,然后将结果写入数据库以用于训练。在训练时,批量大小N设置为1,并且仅使用boxed区域中的层。
相关文献
[1] N. Merrill and G. Huang, “Lightweight Unsupervised Deep Loop Closure,” in Robotics: Science and Systems XIV, 2018.
代码
CALC
原理介绍:用于回环检测的卷积自动编码器。它该代码分为两个模块。TrainAndTest用于训练和测试模型,DeepLCD是一个用于在线回环检测或图像检索的C 库。
源码地址:https://github.com/rpng/calc
关注公众号,点击“学习圈子”,“SLAM入门“”,从零开始学习三维视觉核心技术SLAM,3天内无条件退款。早就是优势,学习切忌单打独斗,这里有教程资料、练习作业、答疑解惑等,优质学习圈帮你少走弯路,快速入门!
推荐阅读
如何从零开始系统化学习视觉SLAM?
从零开始一起学习SLAM | 为什么要学SLAM?
从零开始一起学习SLAM | 学习SLAM到底需要学什么?
从零开始一起学习SLAM | SLAM有什么用?
从零开始一起学习SLAM | C 新特性要不要学?
从零开始一起学习SLAM | 为什么要用齐次坐标?
从零开始一起学习SLAM | 三维空间刚体的旋转
从零开始一起学习SLAM | 为啥需要李群与李代数?
从零开始一起学习SLAM | 相机成像模型
从零开始一起学习SLAM | 不推公式,如何真正理解对极约束?
从零开始一起学习SLAM | 神奇的单应矩阵
从零开始一起学习SLAM | 你好,点云
从零开始一起学习SLAM | 给点云加个滤网
从零开始一起学习SLAM | 点云平滑法线估计
从零开始一起学习SLAM | 点云到网格的进化
从零开始一起学习SLAM | 理解图优化,一步步带你看懂g2o代码
从零开始一起学习SLAM | 掌握g2o顶点编程套路
从零开始一起学习SLAM | 掌握g2o边的代码套路
从零开始一起学习SLAM | 用四元数插值来对齐IMU和图像帧
零基础小白,如何入门计算机视觉?
SLAM领域牛人、牛实验室、牛研究成果梳理
我用MATLAB撸了一个2D LiDAR SLAM
可视化理解四元数,愿你不再掉头发
最近一年语义SLAM有哪些代表性工作?
视觉SLAM技术综述
汇总 | VIO、激光SLAM相关论文分类集锦
研究SLAM,对编程的要求有多高?
2018年SLAM、三维视觉方向求职经验分享
2018年SLAM、三维视觉方向求职经验分享
深度学习遇到SLAM | 如何评价基于深度学习的DeepVO,VINet,VidLoc?
AI资源对接需求汇总:第1期
AI资源对接需求汇总:第2期
计算机视觉是人工智能之眼。公众号已原创170篇文章,兼具系统性,严谨性,易读性,菜单栏点击“汇总分类”查看原创系列包括:三维视觉、视觉SLAM、深度学习、机器学习、深度相机、入门科普、CV方向简介、手机双摄、全景相机、相机标定、医学图像、前沿会议、机器人、ARVR、行业趋势等。同时有入门基础、项目实战、面试经验、教学资料等干货。一键关注星标,加技术交流群,一起进步。