
当你初学编程时,通常是将数组作为 “主要的数据结构”来学习的。
最终,你也会学习到哈希表(hash tables)。如果你正在修计算机科学学位,你必须学习的一门课程是数据结构。你还会学习到链表(linked list),队列(queues)以及栈(stacks)。我们将这些数据结构称为“线性”数据结构,因为所有这些数据结构在逻辑上都有一个起点和终点。
当我们开始学习树(trees)和图(graphs)的时候,真的变得很困惑。我们不再以线性的方式存储数据。这两种数据结构都以一种特殊的方式来存储数据。
本文的目的是帮助你更好地理解树这种数据结构,并且澄清一些你可能存在的困惑。
在本文中,我们将学习以下内容:
- 什么是树
- 树的示例
- 它的术语定义以及它怎么运作
- 怎样编码实现树这一数据结构
让我们撸起袖子开始干吧。 :)
定义
在开始编码的时候,很常见的现象是对线性数据结构的理解要好于树和图的理解。
树是著名的非线性数据结构。它们不是以线性的方式存储数据。他们按照层级关系来组织数据。
一起来看一个生活中的真实例子
当我说层级关系的时候意味着什么?
想象一下包含几代人的家谱:祖父母、父母、孩子、兄弟姐妹等。我们通常按照层级关系来组织家谱。
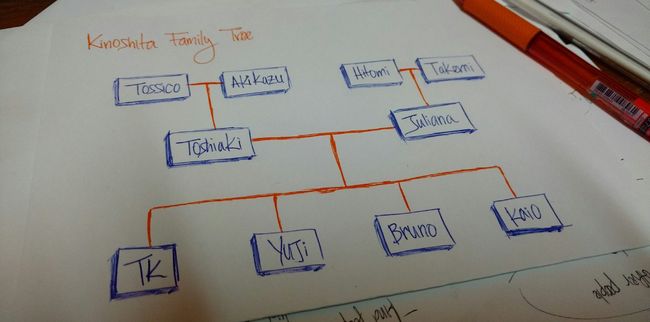
上面的这张图片就是我的家谱:Tossico, Akikazu, Hitomi, 和 Takemi 是我的祖父母.
Toshiaki 和 Juliana 是我的父母。
TK, Yuji, Bruno, 和 Kaio 是我父母的孩子(我和我的兄弟姐妹)。
一个组织的架构是层级关系的另一个范例。

在 HTML 中,Document Object Model (DOM) 也是按照树的方式运行。

HTML 标签会包含其他的标签。我们有一个 head 标签和一个 body 标签。这些标签包含特殊的组件。head 标签包含 meta 和 title 标签。body 标签包含用户界面展示使用的组件,如 h1、a、li 等。
技术定义
树是一系列节点(nodes)的集合。所有的节点通过边(edge)连接。每一个节点包含数据,每一个节点可能有也可能没有子节点。

我们将树的第一个节点称为根节点(root)。如果根节点与其他节点相连,那么这个根节点又是一个父节点,与它相连的节点称为子节点。

所有的树节点都是通过边相连。边是树很重要的一部分,因为树通过边来管理节点之间的关系。

叶节点(leaves)是树上最后的节点。叶节点就是那些没有子节点的节点。和真实的树一样,我们有树根,有树干,和树叶。

另外两个需要理解的重要概念是高度(height)和深度(depth)。
树的高度是指到达树叶的最长路径的长度。
一个节点的深度是该节点到达根节点的路径长度。
术语总结
- 根节点 是树上最顶部的节点
- 边 是节点之间的连接
- 子节点 是指拥有父节点的节点
- 父节点 是指和子节点之间有一条边连接的节点
- 叶节点 是指树中没有子节点的节点
- 高度 是指到到达叶节点最长路径的长度
- 深度 是指一个节点到达根节点路径的长度
二叉树(Binary trees)
现在我们来讨论一种特殊的树。我们称之为二叉树(Binary trees)。
"在计算机科学中,二叉树是每个节点最多只有两个分支(即不存在分支度大于2的节点)的树结构。通常分支被称作“左子树”或“右子树”。二叉树的分支具有左右次序,不能随意颠倒。" -- 维基百科
所以我们一起来看一个二叉树的示例:

编码实现一个二叉树
当我们在实现一个二叉树的时候,我们需要记住的第一件事情是:二叉树是一系列节点的集合。每一个节点有3个属性:值(values),左子节点和右子节点。
我们怎么通过初始化这三个属性来实现一个简单的二叉树呢?
一起来看一看:
class BinaryTree(val value: Any) {
var leftChild: BinaryTree? = null
var rightChild: BinaryTree? = null
}
这就是我们的二叉树类。
当我们构建一个对象的时候,我们将 value (节点存储的数据)作为一个参数传递进去。注意 leftChild 和 rightChild 都被设置成了 null。
为什么?
因为当我们创建一个节点的时候,它没有任何子节点。我们仅有节点存储的数据。
我们来测试一下:
fun testBinaryTree(){
val tree = BinaryTree("a")
println(tree.value) //a
println(tree.leftChild) //null
println(tree.rightChild) //null
}
就是这样的。
我们可以将字符串 "a" 作为值传递给二叉树节点。如果我们打印 tree.value, tree.leftChild 和 tree.rightChild 可以看到它们的值。
我们继续插入部分。在这里我们需要做什么?
我们将实现一个方法,在左节点或者右节点插入一个节点。
规则是这样的:
- 如果当前节点没有左子节点,我们就创建一个新的节点,并将它设置成当前节点的左子节点。
- 如果当前节点有左子节点,我们创建一个新的节点并将它放在当前左子节点的位置。然后将左子节点放到新节点的左子节点。
我们来画一下:

这里是代码实现:
fun insertLeft(value: Any){
if (leftChild==null){
leftChild = BinaryTree(value)
}else{
val newNode = BinaryTree(value)
newNode.leftChild = leftChild
leftChild = newNode
}
}
再说明一下,如果当前节点没有左子节点,我们直接创建一个节点并将它赋值给左子节点。否则我们创建一个新的节点,将它的左子节点设置为当前左子节点,然后再将新的节点设置为左子节点。
插入右子节点的逻辑是一样的:
fun insertRight(value: Any){
if (rightChild==null){
rightChild = BinaryTree(value)
}else{
val newNode = BinaryTree(value)
newNode.rightChild = rightChild
rightChild = newNode
}
}
代码实现完成了。
但是并不完整。我们还需要测试一下。
我们来构建下面这样一棵树:

总结一下图中的这个树:
- a 节点是我们这个二叉树的根节点
- a 的左子节点是 b 节点
- a 的右子节点是 c 节点
- b 的右子节点是 d 节点(b节点没有左子节点)
- c 的左子节点是 e 节点
- c 的右子节点是 f 节点
- e 节点和 f 节点 都没有子节点
所以下面就是这个树的代码:
val aNode = BinaryTree("a")
aNode.insertLeft("b")
aNode.insertRight("c")
val bNode = aNode.leftChild
bNode?.insertRight("d")
val cNode = aNode.rightChild
cNode?.insertLeft("e")
cNode?.insertRight("f")
val dNode = bNode?.rightChild
val eNode = cNode?.leftChild
val fNode = cNode?.rightChild
println(aNode.value) //a
println(bNode?.value)//b
println(cNode?.value)//c
println(dNode?.value)//d
println(eNode?.value)//e
println(fNode?.value)//f
这样插入算法就算完成了。
现在我们一起来看看树的遍历。
树的遍历我们有两个选项:深度优先搜索(Depth-First Search (DFS)) 和 广度优先搜索(Breadth-First Search (BFS))
- DFS:沿着树的深度遍历树的节点,尽可能深的搜索树的分支。当节点v的所在边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止 ---维基百科
- BFS:是从根节点开始,沿着树的宽度遍历树的节点。如果所有节点均被访问,则算法中止 ---维基百科
我们一起来实现每一种遍历类型。
深度优先搜索(DFS)
DFS 先要遍历完到叶节点的所有路径,然后再返回(backtracking'),之后再遍历另外一个分支。我们来看一下这种遍历的示例:

这个算法的结果是 1-2-3-4-5-6-7。
为什么?
我们来分解一下:
- 从根节点(1)开始。打印
- 进入左子节点(2),并打印
- 继续进入左子节点(3),并打印。(这个节点没有任何子节点)。
- 返回并进入右子节点(4)并打印。(这个节点也没有任何子节点)。
- 返回到根节点并进入它的右子节点(5),并打印。
- 进入左子节点(6)并打印。(这个节点没有任何子节点)。
- 返回并进入右子节点(7)并打印。(这个节点也没有任何子节点)。
- 结束
当我们沿着树的深度方向探索叶节点然后再返回时。这就是所谓的 DFS 算法。
现在我们已经了解了这种遍历算法,我们将讨论三种类型的 DFS:前序、中序和后序。
前序
我们在上面一个例子是中使用的就是前序。
- 先打印当前节点的值。
- 如果当前节点有左子节点(也只有它有左子节点时)则进入左子节点并打印。
- 如果当前节点有右子节点(也只有它有右子节点时)则进入右子节点并打印。
fun preOrder(){
println(value)
leftChild?.preOrder()
rightChild?.preOrder()
}
中序

上面这个树执行中序算法后的结果是:3-2-4-1-6-5-7.
先左子树,然后自己,最后右子树。
来看一下代码:
fun inOrder(){
leftChild?.inOrder()
println(value)
rightChild?.inOrder()
}
- 当且仅当有左子树时,进入左子树并打印。
- 打印当前节点的值。
- 当且仅当有右子树时,进入右子树并打印。
后序

这个树执行后序算法以后的结果是: 3-4-2-6-7-5-1。
先左子树、然后右子树,最后是当前节点。
代码如下:
fun postOrder(){
leftChild?.postOrder()
rightChild?.postOrder()
println(value)
}
广度优先搜索(Breadth-First Search(BFS))
BFS 算法按照层次一级一级的遍历树

这个例子可以帮助我们更好地理解这个算法:

那么我们按层遍历,在这个例子中产生的结果就是 1-2-5-3-4-6-7。
- 第0层/级:只有一个节点,值是 1
- 第1层/级:有两个节点:2 和 5
- 第3层/级:有4个节点:3, 4, 6 和 7
我们来看一下编码实现:
fun bfs(){
val queue = ArrayQueue(10)
queue.add(this)
while (queue.isNotEmpty()){
val currentNode = queue[0]
queue.remove(currentNode)
println(currentNode.value)
currentNode.leftChild?.let { queue.add(it) }
currentNode.rightChild?.let { queue.add(it) }
}
}
为了实现 BFS 算法,我们借助了队列数据结构。
怎么实现的呢?
上图:

- 首先将根节点放入队列。
- 只要队列不为空就一直迭代。
- 取出队列中的第一个节点并打印它的值。
- 将当前队列的左右子节点放进队列(如果它有子节点的话)。
- 结束。在队列的帮助下我们最终将打印出每一个节点的值。
二叉查找树(Binary Search tree)
二叉查找树又称为有序二叉树, 它按照有序的方式存储数据,所以查找以及其他操作都可以使用而二分查找的方式进行。
二叉查找树很重要的一个属性是:二叉树节点中的值要大于左子树中的值但是小于右子树中的值。

我们来分析一下上图中的几个树:
- A 是反转后的二叉查找树,7-5-8-6 子树应该在右边,2-1-3 子树应该在左边。
- B 是唯一正确的选项。它满足二叉查找树的属性。
- C 有一个问题,数值为4的那个节点应该位于根节点的左边,因为它小于 5。
我们来编码实现一个二叉查找树
在这一节我们将了解在二叉查找树中插入节点、搜索指定值、删除节点以及树的平衡。
插入往树中添加一个新的节点
假设我们有一个空的树,我们想按照以下顺序添加这些值:50,76,21,4,32,100,64,52。
第一件事是我们需要确认 50 是否是我们这个树的根。

然后我们就可以一个一个地添加节点。
- 76 比 50 大,所以 76 插入到右边
- 21 比 50 小,所以 21 插入到坐标
- 4 比 50 小,50 这个节点有左子节点 21,由于 4 比 21 小,所以将 4 插入到 节点 21 的左边
- 32 比 50小,50 这个节点有左子节点 21,由于 32 比21 大,所以将 32 插入到 21 的右边
- 100 比 50 大,50 这个节点有右子节点 76,由于 100 比 76 大,所以将 100 插入到 76 的右边
- 64 比 50 大,50 这个节点有右子节点 76,64 比76小,所以将 64 插入到 76 的左边
- 52 比 50 大,50 这个节点有右子节点 76,52 比 76 小,76 有左子节点 64,52 比 64 小,所以将 52 插入到 64 的左侧

你有注意到这个规律吗?
我们来分解一下:
- 新的值比当前节点的值大还是小?
- 如果比当前节点的值大,进入右子树。如果当前节点没有右子节点,则将它插入到右子节点,否则回到第一步。
- 如果比当前节点的值小,进入左子树。如果当前节点没有左子节点,则将它插入到左子节点,否则回到第一步。
- 有一种情况我们没有处理,那就是新插入的值和当前节点的值相等。这个时候我们使用规则3,将相等的值插入到左子树。
一起来看一下编码:
class BinarySearchTree(private var value: Int){
var leftChild : BinarySearchTree? = null
var rightChild: BinarySearchTree? = null
fun insertNode(insertValue: Int){
if (insertValue <= value){
leftChild?.insertNode(insertValue)
if (leftChild == null) {
leftChild = BinarySearchTree(insertValue)
}
}
if (insertValue > value){
rightChild?.insertNode(insertValue)
if (rightChild==null){
rightChild = BinarySearchTree(insertValue)
}
}
}
看起来非常简单。
这个算法的强大之处是递归部分,也就是第 7 行和第 12 行。这两行分别调用了左右子节点的 insertMode 方法。第 9 行和第 14 行就是将新插入的值放入当前节点的子节点。
我们再来看一下查找
查找算法就是有关搜索。对于给定的值(整数),我们需要确认我们的二叉查找树中是否包含这个值。
在插入算法中有一个很重要的点需要我们注意。首先我们有一个根节点,然后所有左子树节点中的值都比根节点要小,所有右子树节点中的值都要大于根节点。
我们一起来看一个例子。
假设我们有这样一个树:
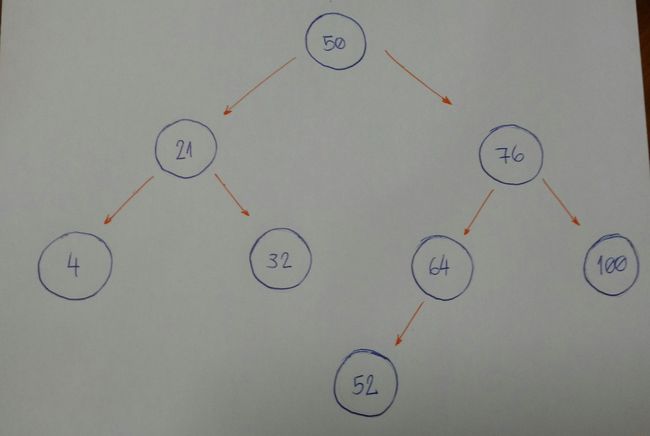
现在我们需要确认树中是否有一个节点的值是52.

我们来分解一下
- 我们从根节点开始,也就是当前节点是根节点。给定的值比当前节点的值小?如果是,我们进入左子树开始查找。
- 给定的值比当前节点的值大?如果是,则进入右子树开始查找。
- 如果规则1和2都不满足,我们将给定值和当前节点值比较,两者是否相等?如果相等,返回 true,否则返回 false。
一起来看一下代码:
fun findNode(searchValue : Int): Boolean{
if (searchValue value && rightChild != null){
return rightChild!! .findNode(searchValue)
}
return searchValue == value
}
- 第 2、3 行是遵循规则1
- 第 6、7 行是遵循规则2
- 第 9 行是遵循规则3
我们怎么来测试一下呢?
我们先创建一个二叉搜索时,并将根节点的值初始化为 15。
val tree = BinarySearchTree(15)
然后再插入很多新的节点。
bsfTree.insertNode(10)
bsfTree.insertNode(8)
bsfTree.insertNode(20)
bsfTree.insertNode(12)
bsfTree.insertNode(17)
bsfTree.insertNode(25)
bsfTree.insertNode(19)
对于已经插入的每一个节点,我们可以测试一下我们的 findMode 方法是否正常运行。
println(tree.findNode(15))
println(tree.findNode(10))
println(tree.findNode(8))
println(tree.findNode(12))
println(tree.findNode(20))
println(tree.findNode(17))
println(tree.findNode(25))
println(tree.findNode(19))
不错,对于这些给定的值都能够正常的查找到。我们来试一下二叉查找树中没有的值:
println(tree.findNode(0))
完美!
删除:移除以及重新组织节点
删除操作要复杂得多,因为我们要考虑各种不同的情况。对于给定的值,我们需要找到值和它一样的节点并删除它。想象一下这个节点有以下这样一些场景:它没有子节点,它有一个子节点,它有两个子节点。
- 场景1: 这个节点没有子节点(它是一个叶节点)
# |50| |50|
# / \ / \
# |30| |70| (DELETE 20) ---> |30| |70|
# / \ \
# |20| |40| |40|
如果我们需要删除的节点没有子节点,我们只需要简单的将它删除就可以。这个时候不需要重新组织数据。
- 场景2:这个节点只有一个节点(左子节点或者右子节点)
# |50| |50|
# / \ / \
# |30| |70| (DELETE 30) ---> |20| |70|
# /
# |20|
这种情况下,我们需要将当前节点的父节点指向子节点。如果当前节点是左子节点,我们需要将父节点的左子节点指向当前节点的子节点。如果当前节点是右子节点,我们需要将父节点的右子节点指向子节点。
- 场景3:这个节点有两个子节点
# |50| |50|
# / \ / \
# |30| |70| (DELETE 30) ---> |40| |70|
# / \ /
# |20| |40| |20|
当一个节点有两个子节点的时候,我们需要从它的右子节点开始找到右子树中值最小的那个节点,然后将这个当前节点的值用查找到的最小值替换,将最小的那个节点删除。
还是来看一看代码吧
fun removeNode(deleteValue: Int, parent: BinarySearchTree?): Boolean{
if (deleteValue < value) {
//待删除的值比当前节点小
//当前节点只有左子节点,在左子节点中继续删除
leftChild?.let { return it.removeNode(deleteValue,this) }
//无左子节点,直接返回删除失败
return false
}else if (deleteValue > value) {
//待删除的值比当前节点大
//当前节点只有右子节点,在右子节点中继续删除
rightChild?.let { return it.removeNode(deleteValue, this) }
//无右子节点,直接返回删除失败
return false
}else {
//待删除的值与当前节点相等,需要删除当前节点
if (leftChild == null && rightChild == null && parent?.leftChild === this){
//当前节点无子节点,为父节点的左子节点,将父节点的左子节点置空
parent.leftChild = null
}else if (leftChild == null && rightChild == null && parent?.rightChild === this){
//当前节点无子节点,为父节点的右子节点,将父节点的右子节点置空
parent.rightChild = null
}else if (leftChild != null && rightChild == null && parent?.leftChild === this){
//当前节点有一个子节点(左),为父节点的左子节点,将父节点的左子节点置为当前节点的左子节点
parent.leftChild = leftChild
}else if (leftChild != null && rightChild == null && parent?.rightChild === this){
//当前节点有一个子节点(左),为父节点的右子节点,将父节点的右子节点置为当前节点的左子节点
parent.rightChild = leftChild
}else if (rightChild != null && leftChild == null && parent?.leftChild === this){
//当前节点有一个子节点(右),为父节点的左子节点,将父节点的左子节点置为当前节点的右子节点
parent.leftChild = rightChild
}else if(rightChild != null && leftChild == null && parent?.rightChild === this){
//当前节点有一个子节点(右),为父节点的右子节点,将父节点的右子节点置为当前节点的右子节点
parent.rightChild = rightChild
}else{
//当前节点有两个子节点,将当前节点的值设为右子树中的最小值,并将这个最小值从右子树中删除
val minValue = rightChild!!.findMiniumValue()
value = minValue
rightChild!!.removeNode(minValue, this)
}
return true
}
}
- 首先:注意参数 deleteValue 和 parent。我们要找到保存 deleteValue 的节点,并且要将这个节点从它的父节点中移除。
- 第二:注意返回值。我们的算法会返回一个布尔值。如果查找成功并删除则返回 true。否则返回 false。
- 从第3行到第17行:我们开始搜索持有 deleteValue 的节点。如果 deleteValue 比当前节点的值小,进入左子树然后递归(当然这必须是在当前节点有左子节点的情况)。如果 deleteValue 比 当前节点的值大,进入右子树然后递归。
- 第18行:我们开始删除算法。详细的步骤就不啰嗦了,都写在注释里了。
为了找到右子树中的最小值,我们定义了 findMiniumValue 方法,沿着左字节点一直往下,当不再有左子节点时,我们就找到了最小值:
fun findMiniumValue(): Int{
return leftChild?.findMiniumValue()?:value
}
现在我们来测试一下:
我们将使用下面这个树来测试我们的removeNode 方法
# |15|
# / \
# |10| |20|
# / \ / \
# |8| |12| |17| |25|
# \
# |19|
首先来删除值为8的节点,这个节点没有子节点。
fun testDeleteNode(){
val bsfTree = BinarySearchTree(15)
bsfTree.insertNode(10)
bsfTree.insertNode(8)
bsfTree.insertNode(20)
bsfTree.insertNode(12)
bsfTree.insertNode(17)
bsfTree.insertNode(19)
bsfTree.insertNode(25)
bsfTree.preOrder()
println(bsfTree.removeNode(8, null))
bsfTree.preOrder()
}
# |15|
# / \
# |10| |20|
# \ / \
# |12| |17| |25|
# \
# |19|
接下来删除值为17的节点,它只有一个子节点。
println(bsfTree.removeNode(17, null))
bsfTree.preOrder()
# |15|
# / \
# |10| |20|
# \ / \
# |12| |19| |25|
最后我们删除一个有两个子节点的节点,那就是我们这个树的根节点。
println(bsfTree.removeNode(15, null))
bsfTree.preOrder()
# |19|
# / \
# |10| |20|
# \ \
# |12| |25|
本文译自:Everything you need to know about tree data structures,原文编码为 python,翻译过程中使用了 kotlin 语言。