最近在学习大数据技术,朋友叫我直接学习Spark,英雄不问出处,菜鸟不问对错,于是我就开始了Spark学习。
为什么要在Docker上搭建Spark集群
Spark本身提供Local模式,在单机上模拟多计算节点来执行任务。但不知道什么思想在做怪,总觉得不搭建一个集群,很不完美的感觉。
搭建分布式集群一般有两个办法:
- 找多台机器来部署。(对于一般的学习者,这不是很现实,我就是这一般这种,没有资源)
- 装虚拟机,在本地开多个虚拟机。这对宿主机器性能要求比较高,因为多个虚拟机开销也很大。同时安装多台虚拟机着实费时麻烦。(很多学习者可能会选择这个办法,但是我怕麻烦,我的电脑也不太给力)
上诉两个办法都不是我的菜,正好前段时间听同事聊天说到Docker。
百度百科对
Docker的解释如下:Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
于是就想到使用Docker来部署Spark集群了。
从0开始搭建Spark集群
安装ubuntu虚拟机
我的机器是 Macbook Pro 13.3寸,这里我选择的虚拟机是VMware Fusion 8.5.8,ubuntu 16.04
具体安装过程就不记录了,非常简单,也不需要教程。但在这里要针对MBP的安装虚拟机的配置做几点记录:
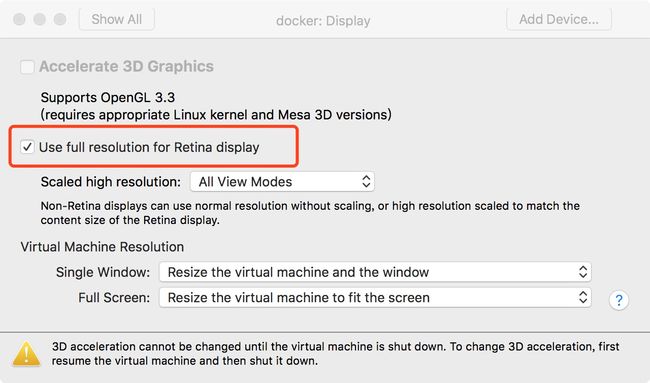
- 分辨率
虚拟机的配置,必须选择如图所示,不然ubuntu的UI会发虚:
 1.png
1.png
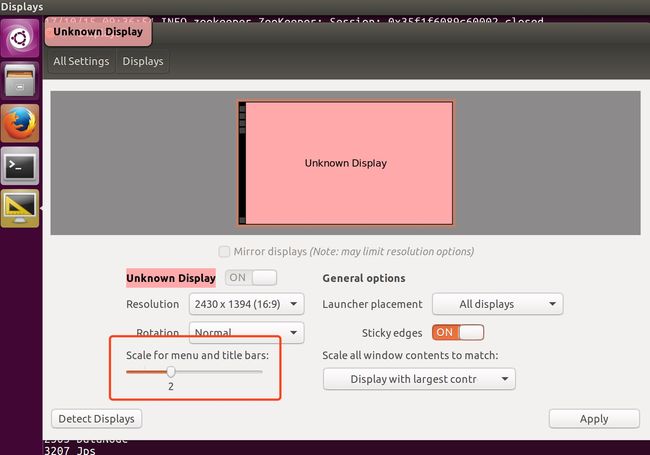
然后,打开启动ubuntu后,会发现图标和文字都非常小。原因是ubuntu的分辨率使用了宿主机MBP的分辨率,缩放scale=1. 在这里要针对ubuntu的分辨率做设置,将scale设置为2,如同:
 2.png
2.png
- VMware Fusion虚拟机Ubuntu中实现与主机共享(复制和粘贴)
- 在Ubuntu菜单上选择VM->install VMware tools。然后出现VMware tools的安装压缩包文件VMwareTools-9.2.0-799703.tar.gz。
- 在终端使用命令
tar xvzf VMwareTools-9.2.0-799703.tar.gz /root/vm解压- 命令
sudo ./root/vm/vmware-install.pl运行解压后的目录里的vmware-install.pl文件进行安装- 完成,重启。 命令
reboot
-
root用户登录
由于后面的很多操作基本都是需要root权限的,在这里是为了学习的,所以索性以root用户登录,但是由于默认的登录界面没有root用户,所以在这里要做一下配置.
- 重置root用户密码,在终端输入
sudo passwd root,一路输入新密码即可- 在系统登录界面以 root 用户登录
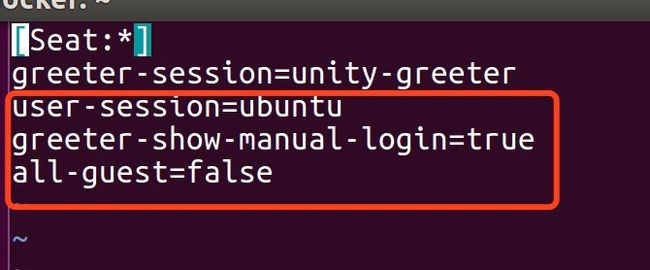
vim /usr/share/lightdm/lightdm.conf.d/50-unity-greeter.conf打开50-unity-greeter.conf文件,并在文件末尾添加:user-session=ubuntu greeter-show-manual-login=true all-guest=false如图:
 1.png
1.png
保存退出
- 终端输入
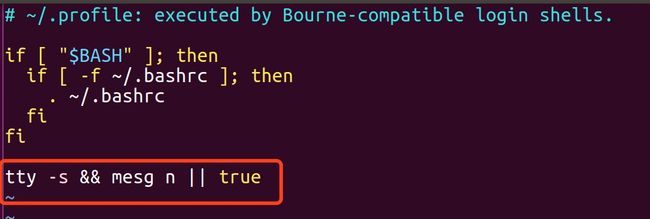
vim /root/.profile命令 打开 .profile 文件,并修改其最后一行为tty -s && mesg n || true
如图:
 2.png
2.png
保存退出。
重启系统,reboot。
然后在登录页面 Login username处可以输入root, 回车,然后输入密码即可登录 root 用户
ubuntu虚拟机的安装和配置到此基本完成了。下面就是正式进入Docker集群的搭建了。
Docker 安装
Docker是什么?有什么用?在这里就不抄过来了,因为我们这里主要是使用Docker来部署Spark集群的,我就暂时不深究了,以后再深入了解下。附Docker 百科
我使用的是 ubuntu 16.04 , 具体安装命令如下:
$ apt update
$ apt-get install apt-transport-https
$ apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys 36A1D7869245C8950F966E92D8576A8BA88D21E9
$ bash -c "echo deb https://get.docker.io/ubuntu docker main > /etc/apt/sources.list.d/docker.list"
$ apt update
$ apt install lxc-docker
安装完成后,校验是否安装成功
使用
docker version命令,如果输出如下信息,证明成功安装: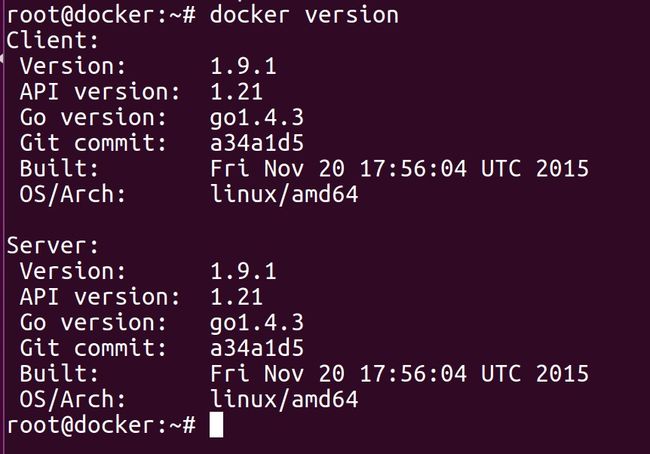 1.png
1.png
下载ubuntu 镜像
$ docker pull ubuntu:16.04
这条命令的作用是从Docker仓库中获取ubuntu的镜像
下载完成后,使用下面命令可以列出所有本地的镜像:
$ docker images如图:
 2.png
2.png当然,图中的另外一条 ubuntu:hadoop 是我安装了hadoop/spark集群后打的tag
启动一个容器
使用如下命令启动一个容器
$ docker run -ti ubuntu:16.04
启动一个容器后,将看到如图效果:
 3.png
3.png
容器启动后,接下来就要安装java,及进行相关配置
安装 java
使用如下命令安装一个java环境
$ apt update
$ apt install software-properties-common python-software-properties
$ add-apt-repository ppa:webupd8team/java
$ apt update
$ apt install oracle-java8-installer
$ java -version
$ apt install oracle-java8-installer这条命令有可能失败,多试几次就可以了
在$ java -version命令后你将看到java的版本信息
如图:
 4.png
4.png
安装完
java后,下面就要进行环境变量的配置了
修改~/.bashrc文件。在文件末尾加入下面配置信息:
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
如图:
接下来是安装集群了,包括
zookeeper、hadoop、spark.
接下来的工作可能会用到如下命令:
wget http://...,用于下载资源文件ifconfig用于查看当前容器ip信息vim用于编辑文件所以我们在这里可以先进行安装这些工具:
$ apt update $ apt install wget $ apt install vim $ apt install net-tools # ifconfig $ apt install iputils-ping # ping
都安装好后,可以将此装好环境变量的镜像保存为一个副本,以后可以基于此副本构建其它镜像:
docker commit -m "java install" 009cf5ac0834 ubuntu:hadoop如图:
 1.png
1.png
然后使用docker images命令将会看到保存好的本地副本:
 2.png
2.png
安装 Zookeeper、 Hadoop、Spark、Scala
下载集群资源
我们计划将集群的 Zookeeper、Hadoop、Spark 安装到统一的目录 /root/soft/apache下。
所以在这里我们要先构建这个目录:
$ cd ~/
$ mkdir soft
$ cd soft
$ mkdir apache
$ mkdir scala #这个目录是用来安装 scala 的
$ cd apache
$ mkdir zookeeper
$ mkdir hadoop
$ mkdir spark
下载 zookeeper
然后到这里下载 zookeeper 到
/root/soft/apache/zookeeper目录下, 我这里下载的是zookeeper-3.4.9$ cd /root/soft/apache/zookeeper $ wget http://archive.apache.org/dist/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.tar.gz
下载 hadoop
然后到这里下载 hadoop 到
/root/soft/apache/hadoop目录下, 我这里下载的是hadoop-2.7.4$ cd /root/soft/apache/hadoop $ wget http://mirrors.sonic.net/apache/hadoop/common/hadoop-2.7.4/hadoop-2.7.4.tar.gz
下载 spark
然后到这里下载 spark 到
/root/soft/apache/spark目录下, 我这里下载的是spark-2.2.0-bin-hadoop2.7$ cd /root/soft/apache/spark $ wget https://d3kbcqa49mib13.cloudfront.net/spark-2.2.0-bin-hadoop2.7.tgz
下载 scala
然后到这里下载 scala 到
/root/soft/scala目录下, 我这里下载的是scala-2.11.11$ cd /root/soft/scala $ wget https://downloads.lightbend.com/scala/2.11.11/scala-2.11.11.tgz
安装 Zookeeper
- 进入 zookeeper 目录,然后解压下载下来的
zookeeper-3.4.9.tar.gz$ cd /root/soft/apache/zookeeper $ tar xvzf zookeeper-3.4.9.ar.gz
- 修改
~/.bashrc, 配置zookeeper环境变量$ vim ~/.bashrc export ZOOKEEPER_HOME=/root/soft/apache/zookeeper/zookeeper-3.4.9 export PATH=$PATH:$ZOOKEEPER_HOME/bin $ source ~/.bashrc #使环境变量生效如图:
 1.png
1.png
- 修改
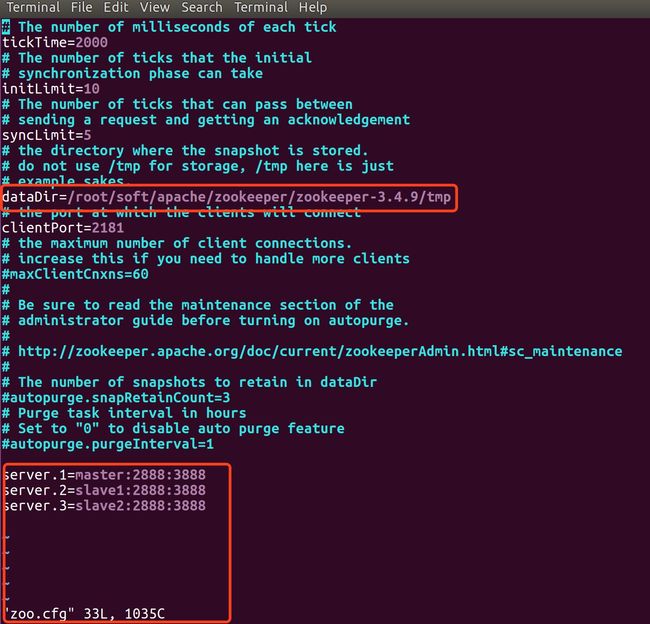
zookeeper配置信息:$ cd zookeeper-3.4.9/conf/ $ cp zoo_sample.cfg zoo.cfg $ vim zoo.cfg修改如下信息:
dataDir=/root/soft/apache/zookeeper/zookeeper-3.4.9/tmp server.1=master:2888:3888 server.2=slave1:2888:3888 server.3=slave2:2888:3888如图:
 2.png
2.png
- 接下来添加
myid文件$ cd ../ $ mkdir tmp $ cd tmp $ touch myid $ echo 1 > myid
..../tmp/myid 文件中保存的数字代表本机的zkServer编号 在此设置master为编号为1的zkServer,之后生成slave1和slave2之后还需要分别修改此文件
安装 Hadoop
- 进入 hadoop 目录,然后解压下载下来的
hadoop-2.7.4.tar.gz$ cd /root/soft/apache/hadoop $ tar xvzf hadoop-2.7.4.tar.gz
- 修改
~/.bashrc, 配置hadoop环境变量$ vim ~/.bashrc export HADOOP_HOME=/root/soft/apache/hadoop/hadoop-2.7.4 export HADOOP_CONFIG_HOME=$HADOOP_HOME/etc/hadoop export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin # 保存退出 esc :wq! $ source ~/.bashrc #使环境变量生效如图:
 1.png
1.png
- 配置
hadoop# 首先进入 `hadoop` 配置文件的目录,因为 `hadoop` 所有的配置都在此目录下 $ cd $HADOOP_CONFIG_HOME/
- 修改核心配置
core-site.xml, 添加如下信息到此文件的< configuration >中间hadoop.tmp.dir /root/soft/apache/hadoop/hadoop-2.7.4/tmp A base for other temporary directories. fs.default.name hdfs://master:9000 true The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem.
- 修改
hdfs-site.xml, 添加如下信息:# dfs.nameservices 名称服务,在基于HA的HDFS中,用名称服务来表示当前活动的NameNode # dfs.ha.namenodes. 配置名称服务下有哪些NameNode # dfs.namenode.rpc-address.. 配置NameNode远程调用地址 # dfs.namenode.http-address.. 配置NameNode浏览器访问地址 # dfs.namenode.shared.edits.dir 配置名称服务对应的JournalNode # dfs.journalnode.edits.dir JournalNode存储数据的路径dfs.nameservices ns1 dfs.ha.namenodes.ns1 nn1,nn2 dfs.namenode.rpc-address.ns1.nn1 master:9000 dfs.namenode.http-address.ns1.nn1 master:50070 dfs.namenode.rpc-address.ns1.nn2 slave1:9000 dfs.namenode.http-address.ns1.nn2 slave1:50070 dfs.namenode.shared.edits.dir qjournal://master:8485;slave1:8485;slave2:8485/ns1 dfs.journalnode.edits.dir /root/soft/apache/hadoop/hadoop-2.7.4/journal dfs.ha.automatic-failover.enabled true dfs.client.failover.proxy.provider.ns1 org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider dfs.ha.fencing.methods sshfence shell(/bin/true) dfs.ha.fencing.ssh.private-key-files /root/.ssh/id_rsa dfs.ha.fencing.ssh.connect-timeout 30000
- 修改
Yarn的配置文件yarn-site.xml:# yarn.resourcemanager.hostname RescourceManager的地址,NodeManager的地址在slaves文件中定义yarn.resourcemanager.hostname master yarn.nodemanager.aux-services mapreduce_shuffle
- 修改
mapred-site.xml
这个文件是不存在的,需要将 mapred-site.xml.template copy一份$ cp mapred-site.xml.template mapred-site.xml
然后编辑 mapred-site.xml ,添加如下信息到文件mapreduce.framework.name yarn
- 修改指定
DataNode和NodeManager的配置文件slaves:$ vim slaves
添加如下节点名master slave1 slave2到此
hadoop算是安装配置好了
安装 Spark
- 进入 spark 目录,然后解压下载下来的
spark-2.2.0-bin-hadoop2.7.tgz$ cd /root/soft/apache/spark $ tar xvzf spark-2.2.0-bin-hadoop2.7.tgz
- 修改
~/.bashrc, 配置spark环境变量$ vim ~/.bashrc export SPARK_HOME=/root/soft/apache/spark/spark-2.2.0-bin-hadoop2.7 export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH # 保存退出 esc :wq! $ source ~/.bashrc #使环境变量生效
- 修改
spark配置$ cd spark-2.2.0-bin-hadoop2.7/conf $ cp spark-env.sh.template spark-env.sh $ vim spark-env.sh
添加如下信息:export SPARK_MASTER_IP=master export SPARK_WORKER_MEMORY=128m export JAVA_HOME=/usr/lib/jvm/java-8-oracle export SCALA_HOME=/root/soft/scala/scala-2.11.11 # scala我们后面会安装它 export SPARK_HOME=/root/soft/apache/spark/spark-2.2.0-bin-hadoop2.7 export HADOOP_CONF_DIR=/root/soft/apache/hadoop/hadoop-2.7.4/etc/hadoop export SPARK_LIBRARY_PATH=$SPARK_HOME/lib export SCALA_LIBRARY_PATH=$SPARK_LIBRARY_PATH export SPARK_WORKER_CORES=1 export SPARK_WORKER_INSTANCES=1 export SPARK_MASTER_PORT=7077
保存退出 esc :wq!
修改指定Worker的配置文件 slaves:$ vim slaves
添加master slave1 slave2到这里,
Spark也算安装配置完成了。
安装 Scala
- 进入 scala 目录,然后解压下载下来的
scala-2.11.11.tgz$ cd /root/soft/scala $ tar xvzf scala-2.11.11.tgz
- 修改
~/.bashrc, 配置spark环境变量$ vim ~/.bashrc export SCALA_HOME=/root/soft/scala/scala-2.11.11 export PATH=$PATH:$SCALA_HOME/bin # 保存退出 esc :wq! $ source ~/.bashrc #使环境变量生效到这里,
scala也算安装配置完成了
安装 SSH, 配置无密码访问集群其它机器
搭建集群环境,自然少不了使用
SSH。这可以实现无密码访问,访问集群机器的时候很方便。
使用如下命令安装 ssh$ apt install ssh
SSH装好了以后,由于我们是Docker容器中运行,所以SSH服务不会自动启动。需要我们在容器启动以后,手动通过/usr/sbin/sshd手动打开SSH服务。未免有些麻烦,为了方便,我们把这个命令加入到~/.bashrc文件中。通过vim ~/.bashrc编辑.bashrc文件,$ vim ~/.bashrc在文件后追加下面内容:
#autorun /usr/sbin/sshd然后运行
source ~/.bashrc使配置生效$ source ~/.bashrc此过程可能会报错:
Missing privilege separation directory: /var/run/sshd需要自己创建这个目录$ mkdir /var/run/sshd
- 生成访问密钥
$ cd ~/ $ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa $ cd .ssh $ cat id_rsa.pub >> authorized_keys
注意: 这里,我的思路是直接将密钥生成后写入镜像,免得在买个容器里面再单独生成一次,还要相互拷贝公钥,比较麻烦。当然这只是学习使用,实际操作时,应该不会这么搞,因为这样所有容器的密钥都是一样的!!!到这里,
SSH也算安装配置完成了
到这里,Spark 集群算是基本安装配置好了,剩下就是部署分布式了。
先查看ip
$ ifconfig
#//172.17.0.2
保存镜像副本
这里我们将安装好
Zookeeper、Hadopp、Spark、Scala的镜像保存为一个副本
- 退出
Docker$ exit
- 保存一个副本
$ docker commit -m "zookeeper hadoop spark scala install" 7b97ba289b22 ubuntu:spark之后我们会基于此副本来运行我们的集群
分布式各节点启动脚本
- 验证一下
IP规则分别开 3 个终端。分别跑如下命令,开启3 个
Docker
终端 1:$ docker run -ti -h master ubuntu:spark $ ifconfig #172.17.0.2
终端 2:$ docker run -ti -h slave1 ubuntu:spark $ ifconfig #172.17.0.3
终端 3:$ docker run -ti -h slave2 ubuntu:spark $ ifconfig #172.17.0.4看到了没,这3个
Docker的ip分别是172.17.0.2、172.17.0.3、172.17.0.4,它是取决于启动Docker的顺序的。
接下来退出这几个Docker,然后编写启动脚本
- 编写集群节点启动脚本
启动 ubuntu:spark$ docker run -ti ubuntu:spark
进入 /root/soft目录,我们将启动脚本都放这里吧$ cd /root/soft $ mkdir shell $ cd shell
vim run_master.sh创建 Master 节点的运行脚本$ vim run_master.sh添加如下信息:
#!/bin/bash #清空hosts文件信息 echo> /etc/hosts #配置主机的host echo 172.17.0.1 host >> /etc/hosts echo 172.17.0.2 master >> /etc/hosts echo 172.17.0.3 slave1 >> /etc/hosts echo 172.17.0.4 slave2 >> /etc/hosts #配置 master 节点的 zookeeper 的 server id echo 1 > /root/soft/apache/zookeeper/zookeeper-3.4.9/tmp/myid zkServer.sh start hadoop-daemons.sh start journalnode hdfs namenode -format hdfs zkfc -formatZK start-dfs.sh start-yarn.sh start-all.sh
vim run_slave1.sh创建 Slave1 节点的运行脚本$ vim run_slave1.sh添加如下信息:
#!/bin/bash #清空hosts文件信息 echo> /etc/hosts #配置主机的host echo 172.17.0.1 host >> /etc/hosts echo 172.17.0.2 master >> /etc/hosts echo 172.17.0.3 slave1 >> /etc/hosts echo 172.17.0.4 slave2 >> /etc/hosts #配置 master 节点的 zookeeper 的 server id echo 2 > /root/soft/apache/zookeeper/zookeeper-3.4.9/tmp/myid zkServer.sh start
vim run_slave2.sh创建 Slave2 节点的运行脚本$ vim run_slave2.sh添加如下信息:
#!/bin/bash #清空hosts文件信息 echo> /etc/hosts #配置主机的host echo 172.17.0.1 host >> /etc/hosts echo 172.17.0.2 master >> /etc/hosts echo 172.17.0.3 slave1 >> /etc/hosts echo 172.17.0.4 slave2 >> /etc/hosts #配置 master 节点的 zookeeper 的 server id echo 3 > /root/soft/apache/zookeeper/zookeeper-3.4.9/tmp/myid zkServer.sh start
vim stop_master.sh创建 Stop 脚本$ vim stop_master.sh添加如下信息:
#!/bin/bash zkServer.sh stop hadoop-daemons.sh stop journalnode stop-dfs.sh stop-yarn.sh stop-all.sh各节点运行脚本到此编写完成。
- 最后
chmod +x run_master.sh chmod +x run_slave1.sh chmod +x run_slave2.sh chmod +x stop_master.sh
- 退出
Docker, 并保存副本$ exit
保存副本$ docker commit -m "zookeeper hadoop spark scala install" 266b46cce542 ubuntu:spark
- 配置虚拟机
ubuntu的hosts$ vim /etc/hosts
添加如下hosts172.17.0.1 host 172.17.0.2 master 172.17.0.3 slave1 172.17.0.4 slave2
到此所有配置安装基本完成了,下面开启你的Spark集群吧!!!
启动 Spark 集群
- 启动 Master 节点
$ docker run -ti -h master ubuntu:spark在这里先不要着急着运行
run_master.sh启动脚本。等最后再运行
- 启动 Slave1 节点
$ docker run -ti -h slave1 ubuntu:spark运行
run_slave1.sh启动脚本$ ./root/soft/shell/run_slave1.sh
- 启动 Slave2 节点
$ docker run -ti -h slave2 ubuntu:spark运行
run_slave2.sh启动脚本$ ./root/soft/shell/run_slave2.sh
- 最后再运行 Master 节点的启动脚本
run_master.sh
切换到启动了 Master 节点的 Docker 终端
$ ./root/soft/shell/run_master.sh
可以使用 jps 命令查看当前集群运行情况$ jps
不出意外的话,你应该能看到类似如下信息:2081 QuorumPeerMain 3011 NodeManager 2900 ResourceManager 2165 JournalNode 2405 NameNode 3159 Worker 2503 DataNode 3207 Jps
到此已经启动了你的 Spark 集群了。
- 还可以登录web管理台来查看运行状况:
服务 地址 HDFS master:50070 Yarn master:8088 Spark master:8080
参考
http://blog.csdn.net/cq361106306/article/details/54237392